读写分离原理
读写分离的基本原理是将数据库读写操作分散到不同的节点上
架构图
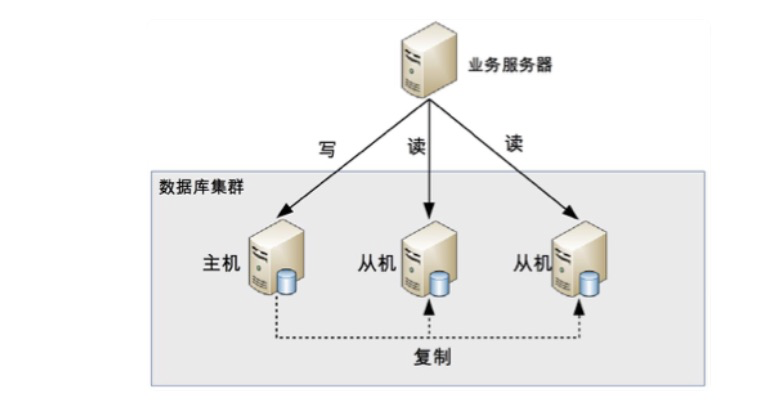
读写分离的基本实现是:
- 数据库服务器搭建主从集群,一主一从、一主多从都可以。
- 数据库主机负责读写操作,从机只负责读操作。
- 数据库主机通过复制将数据同步到从机,每台数据库服务器都存储了所有的业务数据。
- 业务服务器将写操作发给数据库主机,将读操作发给数据库从机。
需要注意的是,这里用的是“主从集群”,而不是“主备集群”。“从机”的“从”可以理解为“仆从”,仆从是要帮主人干活的,“从机”是需要提供读数据的功能的;而“备机”一般被认为仅仅提供备份功能,不提供访问功能。所以使用“主从”还是“主备”,是要看场景的,这两个词并不是完全等同的。
读写分离的实现逻辑并不复杂,但有两个细节点将引入设计复杂度:主从复制延迟和分配机制。
复制延迟
以 MySQL 为例,主从复制延迟可能达到 1 秒,如果有大量数据同步,延迟 1 分钟也是有可能的。主从复制延迟会带来一个问题:如果业务服务器将数据写入到数据库主服务器后立刻(1 秒内)进行读取,此时读操作访问的是从机,主机还没有将数据复制过来,到从机读取数据是读不到最新数据的,业务上就可能出现问题。例如,用户刚注册完后立刻登录,业务服务器会提示他“你还没有注册”,而用户明明刚才已经注册成功了。
解决主从复制延迟有几种常见的方法:
- 写操作后的读操作指定发给数据库主服务器
例如注册账号完成后,登录时读取账号的读操作也发给数据库主服务器。这种方式和业务强绑定,对业务的侵入和影响较大,如果哪个新来的程序员不知道这样写代码,就会导致一个 bug。
- 读从机失败后再读一次主机
这就是通常所说的“二次读取”,二次读取和业务无绑定,只需要对底层数据库访问的 API 进行封装即可,实现代价较小,不足之处在于如果有很多二次读取,将大大增加主机的读操作压力。例如,黑客暴力破解账号,会导致大量的二次读取操作,主机可能顶不住读操作的压力从而崩溃。
- 关键业务读写操作全部指向主机,非关键业务采用读写分离
例如,对于一个用户管理系统来说,注册 + 登录的业务读写操作全部访问主机,用户的介绍、爱好、等级等业务,可以采用读写分离,因为即使用户改了自己的自我介绍,在查询时却看到了自我介绍还是旧的,业务影响与不能登录相比就小很多,还可以忍受。
分配机制
将读写操作区分开来,然后访问不同的数据库服务器,一般有两种方式:程序代码封装和中间件封装。
基本架构是
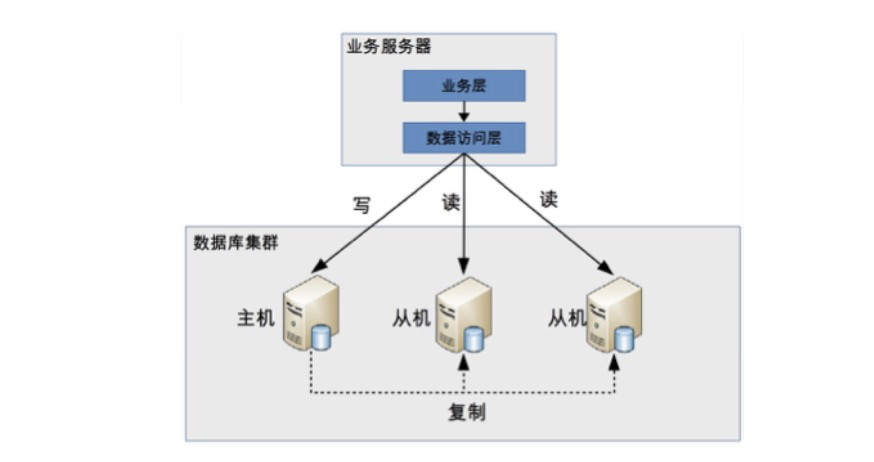
程序代码封装的方式具备几个特点:
- 实现简单,而且可以根据业务做较多定制化的功能。
- 每个编程语言都需要自己实现一次,无法通用,如果一个业务包含多个编程语言写的多个子系统,则重复开发的工作量比较大。
- 故障情况下,如果主从发生切换,则可能需要所有系统都修改配置并重启。
中间件封装
中间件封装指的是独立一套系统出来,实现读写操作分离和数据库服务器连接的管理。中间件对业务服务器提供 SQL 兼容的协议,业务服务器无须自己进行读写分离。对于业务服务器来说,访问中间件和访问数据库没有区别,事实上在业务服务器看来,中间件就是一个数据库服务器。其基本架构是:
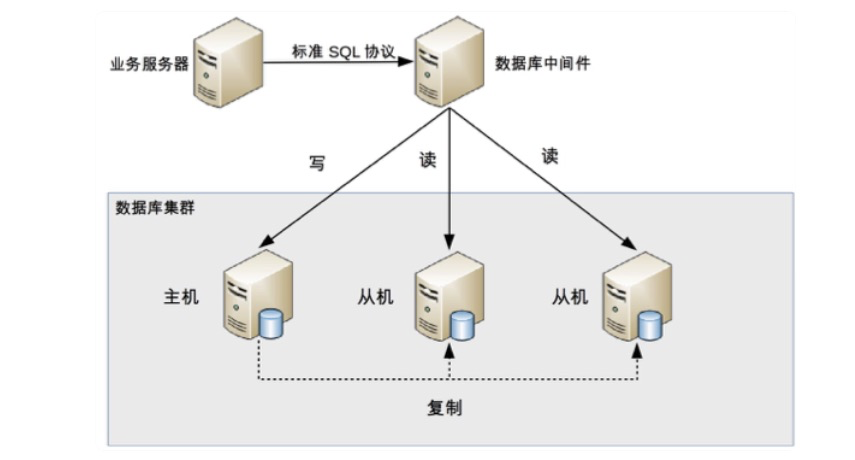
数据库中间件的方式具备的特点是:
- 能够支持多种编程语言,因为数据库中间件对业务服务器提供的是标准 SQL 接口。
- 数据库中间件要支持完整的 SQL 语法和数据库服务器的协议(例如,MySQL 客户端和服务器的连接协议),实现比较复杂,细节特别多,很容易出现 bug,需要较长的时间才能稳定。
- 数据库中间件自己不执行真正的读写操作,但所有的数据库操作请求都要经过中间件,中间件的性能要求也很高。
- 数据库主从切换对业务服务器无感知,数据库中间件可以探测数据库服务器的主从状态。例如,向某个测试表写入一条数据,成功的就是主机,失败的就是从机。

若有收获,就点个赞吧
0 人点赞
