内存
CPU要想从内存读取数据,需要通过地址总线,把地址传输给内存,内存准备好数据,输出到数据总线
若是32位地址总线,可以寻址[0,2的32次方-1],占用内存4g
有些CPU是能够支持访问任意地址的,它是做了很多处理,比如想从地址1读取8字节的数据,CPU会分2次读,第一次从0-7,只取后7字节,第二次从8-15,但只取第一字节。把2次结果拼接起来拿到所需数据。这样比较耗费性能,编译器会把各种类型的值安排到合适的位置,并占用合适的长度。每种类型的对齐边值就是它的对齐边界。int16(2),int32(4),内存对齐要求数据存储地址以及占用的字节数都是它对齐边界的倍数。
内存对齐的收益
- 提高代码平台兼容性
- 优化数据对内存的使用
- 避免一些内存不对齐带来的坑
- 有助于一些源码的阅读
为什么要对齐
列举一些常见的单位
- 位 bit
- 计算机内存数据存储的最小单位
- 字节 byte
- 计算机数据处理的基本单位
- 机器字 machine word
- 计算机用来一次性处理事务的一个固定长度
- 平台原因
- 某些硬件平台只能在某些地址处取某些特定类似的数据
- 性能原因
- 数据结构应该尽可能地在自然边界上对齐,为了访问未对齐的内存,处理器需要作2次内存访问,而内存对齐就只需要一次访问
- 64位字的安全访问保证
- 在x86-32上,64位函数使用Pentium MMX之前不存在的指令。在非Linux ARM上,64位函数使用ARMv6k内核之前不可用的指令
- 在ARM、x86-32和32MIPS上,调用方有责任安排对原子访问的64位字对齐。变量或分配的结构、数组或切片中的第一个字(word)可以依赖当做是64位对齐的(摘抄的,不是太懂)
- 操作系统的cpu不是一个字节一个字节访问的,而是2,4,8这样的字长来访问的
- 处理器从存储器子系统读取数据至寄存器,或者,写寄存器数据到存储器,传送的数据长度通常是字长。
如何确定每种类型的对齐边界?
和平台有关
go语言支持这些平台
| archName | PtrSize(指针宽度) | RegSize(寄存器宽度) |
|---|---|---|
| 386 | 4 | 8 |
| amd64 | 8 | 8 |
| arm | 4 | 4 |
| arm64 | 5 | 8 |
| …… |
被Go语言称为寄存器宽度的这个值,就可以理解为机器字长,也是平台对应的最大对齐边界,而数据类型的对齐边界是取类型大小与平台最大对齐边界中的较小的那个
| 类型 | 大小 | RegSize |
|---|---|---|
| int8 | 1 byte | 8 byte |
| int16 | 2 byte | 8 byte |
| int32 | 4 byte | 8 byte |
| int64 | 8 byte | 8 byte |
| string | 16 byte | 8 byte |
| slice | 24 byte | 8 byte |
| … | … | … |
同一个类型在不同平台上的大小可能不同,不按照最大对齐边界或者最小对齐边界来考虑是为了减少浪费、提高性能
如何确定一个结构体的对齐边界
先确定每个成员的对齐边界,然后取最大值
type T stract {a int8 1 byteb int64 8 bytec int32 4 byte 最大对齐 8 byted int16 2 byte}
内存对齐的第一个要求、存储这个结构体的起始地址是对齐边界的整数倍
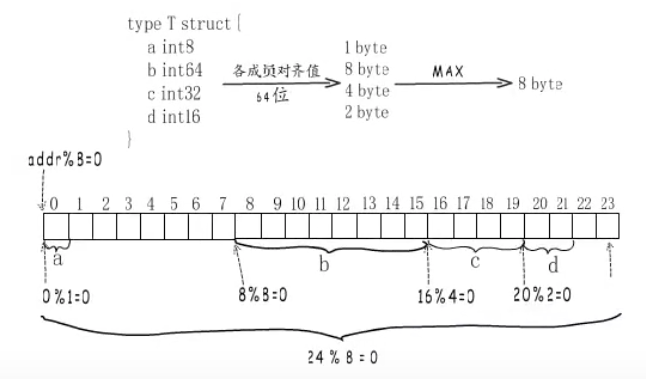
第一个成员a,它要对齐到1字节,而这里是相对地址0,所以直接放这里,然后是第二个成员b,它要对齐到8字节,但是接下来的地址对8取模不等于0,所以要往后移。接下来是c,它要对齐到4字节。所有成员放好还不算完,内存对齐的第二个要求是结构体整体占用字节数需要是类型对齐边界的整数倍,不够的话要往后扩张。所以要扩充到相当地址23这里。最终这个结构体类型的大小就是24字节
为啥要限制类型大小等于其对其边界的整数倍 ?
假如不扩张到对齐边界的整数倍,这个结构体大小就是22字节,如果要使用长度为2的T类型数组,按照元素类型大小,会占用44字节,就会导致于第二个元素并没有内存对齐

所以只有每个结构体的大小是对齐值的整数倍,才能保证数组中的每一个都是内存对齐的
内存对齐的第二个要求:结构体整体占用字节数需要是类型对齐边界的倍数,不够的话要往后扩张一下
举个特例
type T1 struct {a struct{}x int64}type T2 struct {x int64a struct{}}a1 := T1{}a2 := T2{}fmt.Printf("zone size struct{} of T1 size:%d,Ts(as final field) size:%d",unfafe.Sizeof(a1), // 8unfafe.Sizeof(a2), // 64位,16;32位:12)
T2可能做了一个Padding(填充),因为在边界,可能会对一些边界的值进行引用等
特殊:
struct{} 和[0]T{} 的大小为0; 不同的大小为0的变量可能指向同一块地址。
零大小字段对齐
零大小字段(zero sized field)是指struct{}
大小为0,按理作为字段时不需要对齐,但当在作为结构体最后一个字段(final field)时需要对齐的。
为什么?
因为,如果有指针指向这个final zero field, 返回的地址将在结构体之外(即指向了别的内存),
如果此指针一直存活不释放对应的内存,就会有内存泄露的问题(该内存不因结构体释放而释放)
使用 golangci-lint 检测对齐
golangci-lint run —disable-all -E maligned
结论
- 内存对齐是为了cpu更高效的访问内存中的数据
- 结构体对齐依赖类型的大小保证和对齐保证
- 地址对齐保证是:如果类型t的对齐保证是n,那么类型t的每个值的地址在运行时必须是n的倍数
- 零大小字段要避免只作为struct最后一个字段,会有内存浪费
参考

若有收获,就点个赞吧
0 人点赞
