0. channel
单纯地将函数并发执行是没有意义的。函数与函数间需要交换数据才能体现并发执行函数的意义。
虽然可以使用共享内存进行数据交换,但是共享内存在不同的 goroutine 中容易发生竞态问题。为了保证数据交换的正确性,必须使用互斥量对内存进行加锁,这种做法势必造成性能问题。
Go 语言的并发模型是 CSP(Communicating Sequential Processes),提倡通过通信共享内存而不是通过共享内存而实现通信。
如果说 goroutine 是 Go 程序并发的执行体,channel 就是它们之间的连接。channel 是可以让一个 goroutine 发送特定值到另一个 goroutine 的通信机制。
Go 语言中的通道(channel)是一种特殊的类型。通道像一个传送带或者队列,总是遵循先入先出(First In First Out)的规则,保证收发数据的顺序。每一个通道都是一个具体类型的导管,也就是声明 channel 的时候需要为其指定元素类型。
1. channel 类型
channel 是一种类型,一种引用类型。声明通道类型的格式如下:
var 变量 chan 元素类型
举几个例子:
var ch1 chan intvar ch2 chan boolvar ch3 chan []int
2. 创建 channel
通道是引用类型,通道类型的空值是 nil。
var ch chan intfmt.Println(ch)
声明的通道后需要使用 make 函数初始化之后才能使用。
创建 channel 的格式如下:
make(chan 元素类型, [缓冲大小])
channel 的缓冲大小是可选的。
举几个例子:
ch4 := make(chan int)ch5 := make(chan bool)ch6 := make(chan []int)
1.1.4. channel 操作
通道有发送(send)、接收 (receive)和关闭(close)三种操作。
发送和接收都使用 <- 符号。
现在我们先使用以下语句定义一个通道:
ch := make(chan int)
发送
将一个值发送到通道中。
ch <- 10
接收
从一个通道中接收值。
x := <- ch<-ch
关闭
我们通过调用内置的 close 函数来关闭通道。
close(ch)
关于关闭通道需要注意的事情是,只有在通知接收方 goroutine 所有的数据都发送完毕的时候才需要关闭通道。通道是可以被垃圾回收机制回收的,它和关闭文件是不一样的,在结束操作之后关闭文件是必须要做的,但关闭通道不是必须的。
关闭后的通道有以下特点:
对一个关闭的通道再发送值就会导致panic。对一个关闭的通道进行接收会一直获取值直到通道为空。对一个关闭的并且没有值的通道执行接收操作会得到对应类型的零值。关闭一个已经关闭的通道会导致panic。
同步模式下,必须要使发送方和接收方配对,操作才会成功,否则会被阻塞;异步模式下,缓冲槽要有剩余容量,操作才会成功,否则也会被阻塞。
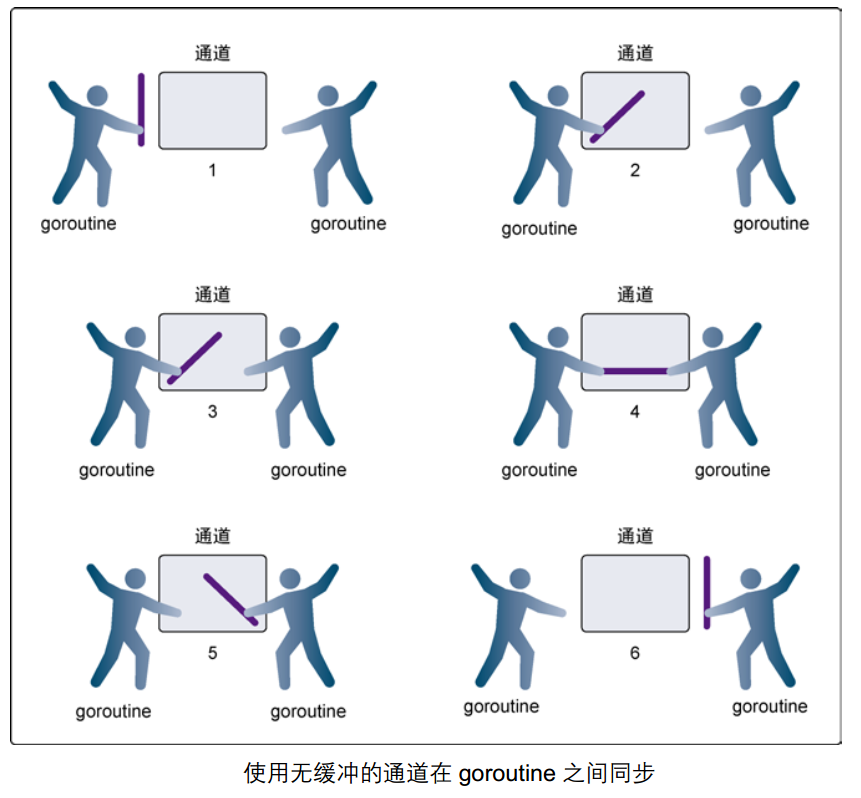
1.1.5. 无缓冲的通道
无缓冲的通道又称为阻塞的通道。我们来看一下下面的代码:
func main() {ch := make(chan int)ch <- 10fmt.Println("发送成功")}
上面这段代码能够通过编译,但是执行的时候会出现以下错误:
fatal error: all goroutines are asleep - deadlock!goroutine 1 [chan send]:main.main().../src/github.com/pprof/studygo/day06/channel02/main.go:8 +0x54
为什么会出现 deadlock 错误呢?
因为我们使用 ch := make(chan int) 创建的是无缓冲的通道,无缓冲的通道只有在有人接收值的时候才能发送值。就像你住的小区没有快递柜和代收点,快递员给你打电话必须要把这个物品送到你的手中,简单来说就是无缓冲的通道必须有接收才能发送。
上面的代码会阻塞在 ch <- 10 这一行代码形成死锁,那如何解决这个问题呢?
一种方法是启用一个 goroutine 去接收值,例如:
func recv(c chan int) {ret := <-cfmt.Println("接收成功", ret)}func main() {ch := make(chan int)go recv(ch)ch <- 10fmt.Println("发送成功")}
无缓冲通道上的发送操作会阻塞,直到另一个 goroutine 在该通道上执行接收操作,这时值才能发送成功,两个 goroutine 将继续执行。相反,如果接收操作先执行,接收方的 goroutine 将阻塞,直到另一个 goroutine 在该通道上发送一个值。
使用无缓冲通道进行通信将导致发送和接收的 goroutine 同步化。因此,无缓冲通道也被称为同步通道。
序中必须同时有不同的 goroutine 对非缓冲通道进行发送和接收操作,否则会造成阻塞。
1.1.6. 有缓冲的通道
解决上面问题的方法还有一种就是使用有缓冲区的通道。
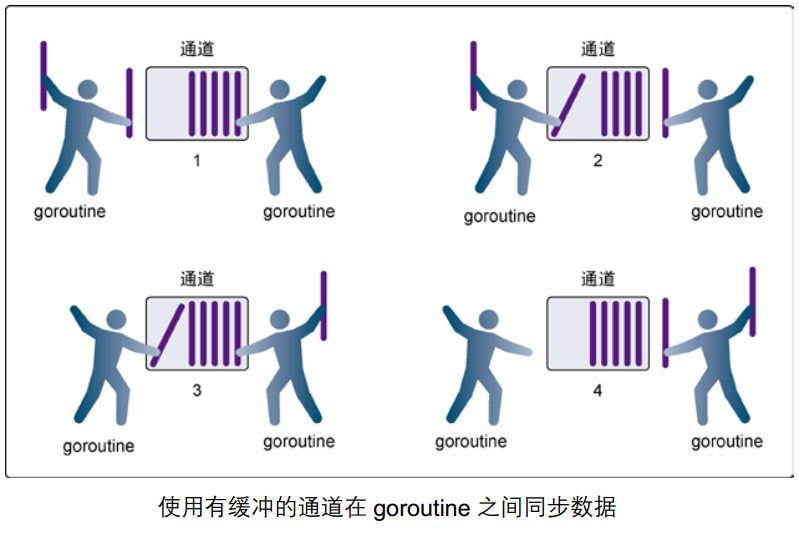
我们可以在使用 make 函数初始化通道的时候为其指定通道的容量,例如:
func main() {ch := make(chan int, 1)ch <- 10fmt.Println("发送成功")}
只要通道的容量大于零,那么该通道就是有缓冲的通道,通道的容量表示通道中能存放元素的数量。就像你小区的快递柜只有那么个多格子,格子满了就装不下了,就阻塞了,等到别人取走一个快递员就能往里面放一个。
我们可以使用内置的 len 函数获取通道内元素的数量,使用 cap 函数获取通道的容量,虽然我们很少会这么做。
一个有缓冲 channel 具备以下特点:
- 有缓冲 channel 的内部有一个缓冲队列;
- 发送操作是向队列的尾部插入元素,如果队列已满,则阻塞等待,直到另一个 goroutine 执行,接收操作释放队列的空间;
- 接收操作是从队列的头部获取元素并把它从队列中删除,如果队列为空,则阻塞等待,直到另一个 goroutine 执行,发送操作插入新的元素。
1.1.7. close()
可以通过内置的 close() 函数关闭 channel(如果你的管道不往里存值或者取值的时候一定记得关闭管道)
package mainimport "fmt"func main() {c := make(chan int)go func() {for i := 0; i < 5; i++ {c <- i}close(c)}()for {if data, ok := <-c; ok {fmt.Println(data)} else {break}}fmt.Println("main结束")}
- 关闭一个 closed channel 会导致 panic
- 向一个 closed channel 发送数据会导致 panic
有一条广泛流传的关闭 channel 的原则:
don’t close a channel from the receiver side and don’t close a channel if the channel has multiple concurrent senders.
不要从一个 receiver 侧关闭 channel,也不要在有多个 sender 时,关闭 channel。
到底应该如何优雅地关闭 channel?
根据 sender 和 receiver 的个数,分下面几种情况:
- 一个 sender,一个 receiver
- 一个 sender, M 个 receiver
- N 个 sender,一个 reciver
- N 个 sender, M 个 receiver
对于 1,2,只有一个 sender 的情况就不用说了,直接从 sender 端关闭就好了
针对第三种情况
解决方案就是增加一个传递关闭信号的 channel,receiver 通过信号 channel 下达关闭数据 channel 指令。senders 监听到关闭信号后,停止发送数据。代码如下:
func main() {rand.Seed(time.Now().UnixNano())const Max = 100000const NumSenders = 1000dataCh := make(chan int, 100)stopCh := make(chan struct{})// sendersfor i := 0; i < NumSenders; i++ {go func() {for {select {case <-stopCh:returncase dataCh <- rand.Intn(Max):}}}()}// the receivergo func() {for value := range dataCh {if value == Max-1 {fmt.Println("send stop signal to senders.")close(stopCh)return}fmt.Println(value)}}()select {case <-time.After(time.Hour):}}
这里的 stopCh 就是信号 channel,它本身只有一个 sender,因此可以直接关闭它。senders 收到了关闭信号后,select 分支 “case <- stopCh” 被选中,退出函数,不再发送数据。
在 Go 语言中,对于一个 channel,如果最终没有任何 goroutine 引用它,不管 channel 有没有被关闭,最终都会被 gc 回收。所以,在这种情形下,所谓的优雅地关闭 channel 就是不关闭 channel,让 gc 代劳。
针对第四种情况
需要增加一个中间人,M 个 receiver 都向它发送关闭 dataCh 的“请求”,中间人收到第一个请求后,就会直接下达关闭 dataCh 的指令(通过关闭 stopCh,这时就不会发生重复关闭的情况,因为 stopCh 的发送方只有中间人一个)。另外,这里的 N 个 sender 也可以向中间人发送关闭 dataCh 的请求。
func main() {rand.Seed(time.Now().UnixNano())const Max = 100000const NumReceivers = 10const NumSenders = 1000dataCh := make(chan int, 100)stopCh := make(chan struct{})// It must be a buffered channel.toStop := make(chan string, 1)var stoppedBy string// moderatorgo func() {stoppedBy = <-toStopclose(stopCh)}()// sendersfor i := 0; i < NumSenders; i++ {go func(id string) {for {value := rand.Intn(Max)if value == 0 {select {case toStop <- "sender#" + id:default:}return}select {case <- stopCh:returncase dataCh <- value:}}}(strconv.Itoa(i))}// receiversfor i := 0; i < NumReceivers; i++ {go func(id string) {for {select {case <- stopCh:returncase value := <-dataCh:if value == Max-1 {select {case toStop <- "receiver#" + id:default:}return}fmt.Println(value)}}}(strconv.Itoa(i))}select {case <- time.After(time.Hour):}}
代码里 toStop 就是中间人的角色,使用它来接收 senders 和 receivers 发送过来的关闭 dataCh 请求。
这里将 toStop 声明成了一个 缓冲型的 channel。假设 toStop 声明的是一个非缓冲型的 channel,那么第一个发送的关闭 dataCh 请求可能会丢失。因为无论是 sender 还是 receiver 都是通过 select 语句来发送请求,如果中间人所在的 goroutine 没有准备好,那 select 语句就不会选中,直接走 default 选项,什么也不做。这样,第一个关闭 dataCh 的请求就会丢失。
1.1.8. 如何优雅的从通道循环取值
当通过通道发送有限的数据时,我们可以通过 close 函数关闭通道来告知从该通道接收值的 goroutine 停止等待。当通道被关闭时,往该通道发送值会引发 panic,从该通道里接收的值一直都是类型零值。那如何判断一个通道是否被关闭了呢?
我们来看下面这个例子:
func main() {ch1 := make(chan int)ch2 := make(chan int)go func() {for i := 0; i < 100; i++ {ch1 <- i}close(ch1)}()go func() {for {i, ok := <-ch1if !ok {break}ch2 <- i * i}close(ch2)}()for i := range ch2 {fmt.Println(i)}}
从上面的例子中我们看到有两种方式在接收值的时候判断通道是否被关闭,我们通常使用的是 for range 的方式。
1.1.9. 单向通道
有的时候我们会将通道作为参数在多个任务函数间传递,很多时候我们在不同的任务函数中使用通道都会对其进行限制,比如限制通道在函数中只能发送或只能接收。
Go 语言中提供了单向通道来处理这种情况。例如,我们把上面的例子改造如下:
func counter(out chan<- int) {for i := 0; i < 100; i++ {out <- i}close(out)}func squarer(out chan<- int, in <-chan int) {for i := range in {out <- i * i}close(out)}func printer(in <-chan int) {for i := range in {fmt.Println(i)}}func main() {ch1 := make(chan int)ch2 := make(chan int)go counter(ch1)go squarer(ch2, ch1)printer(ch2)}
其中,
1.chan<- int是一个只能发送的通道,可以发送但是不能接收;2.<-chan int是一个只能接收的通道,可以接收但是不能发送。
在函数传参及任何赋值操作中将双向通道转换为单向通道是可以的,但反过来是不可以的。
1.1.10.channel 退出
func main() {var wg sync.WaitGroupwg.Add(1)stopCh := make(chan bool)go func() {defer wg.Done()watch(stopCh, "watch")}()time.Sleep(5 * time.Second)stopCh <- truewg.Wait()}func watch(stopCh chan bool, name string) {for {select {case <-stopCh:fmt.Println(name, "copy that, stop")returndefault:fmt.Println(name, "watching……")}time.Sleep(1 * time.Second)}}
1.1.11. 优雅的方式
- 情形一:M个接收者和一个发送者,发送者通过关闭用来传输数据的通道来传递发送结束信号。
- 情形二:一个接收者和N个发送者,此唯一接收者通过关闭一个额外的信号通道来通知发送者不要再发送数据了。
- 情形三:M个接收者和N个发送者,它们中的任何协程都可以让一个中间调解协程帮忙发出停止数据传送的信号。
1.1.12.数据结构
type hchan struct {qcount uint // chan 里元素数量dataqsiz uint // chan 底层循环数组的长度buf unsafe.Pointer // 指向底层循环数组的指针,只针对有缓冲的 channelelemsize uint16 // chan 中元素大小closed uint32 // chan 是否被关闭的标志elemtype *_type // chan 中元素类型sendx uint // 已发送元素在循环数组中的索引recvx uint // 已接收元素在循环数组中的索引recvq waitq // 等待接收的 goroutine 队列sendq waitq // 等待发送的 goroutine 队列lock mutex // 保护 hchan 中所有字段}
qcount— Channel 中的元素个数;dataqsiz— Channel 中的循环队列的长度;buf— Channel 的缓冲区数据指针,是个循环链表sendx— Channel 的发送操作处理到的位置;recvx— Channel 的接收操作处理到的位置;
elemsize 和 elemtype 分别表示当前 Channel 能够收发的元素类型和大小;sendq 和 recvq 存储了当前 Channel 由于缓冲区空间不足而阻塞的 Goroutine 列表,这些等待队列使用双向链表 [runtime.waitq](https://draveness.me/golang/tree/runtime.waitq) 表示,链表中所有的元素都是 [runtime.sudog](https://draveness.me/golang/tree/runtime.sudog) 结构:
原理
创建channel实际上就是在内存中实例化了一个hchan的结构体,并返回一个ch指针,使用过程中channel在函数之间的传递都是用的这个指针,这就是为什么函数传递中无需使用channel的指针,而直接用channel就行了,因为channel本身就是一个指针。
channel就是用了一个锁。hchan本身包含一个互斥锁mutex
channel中有个缓存buf,是用来缓存数据的
当使用send (ch <- xx)或者recv ( <-ch)的时候,首先要锁住hchan这个结构体。
当channel缓存满了之后会发生什么?这其中的原理是怎样的?
goroutine的阻塞操作,实际上是调用send (ch <- xx)或者recv ( <-ch)的时候主动触发的,具体请看以下内容:
这个时候G1正在正常运行,当再次进行send操作(ch<-1)的时候,会主动调用Go的调度器,让G1等待,并从让出M,让其他G去使用
同时G1也会被抽象成含有G1指针和send元素的sudog结构体保存到hchan的sendq中等待被唤醒。
那么,G1什么时候被唤醒呢?这个时候G2隆重登场。
G2执行了recv操作p := <-ch,于是会发生以下的操作:
G2从缓存队列中取出数据,channel会将等待队列中的G1推出,将G1当时send的数据推到缓存中,然后调用Go的scheduler,唤醒G1,并把G1放到可运行的Goroutine队列中。
发送数据和接收数据过程
发送数据时先判断channel类型,如果有缓冲区,判断channel是否还有空间,然后从等待channel中获取等待channel中的接受者,如果取到接收者,则将对象直接传递给接受者,然后将接受者所在的go放入P所在的可运行G队列,发送过程完成,如果未取到接收者,则将发送者enqueue到发送channel,发送者进入阻塞状态,有缓冲的channel需要先判断channel缓冲是否还有空间,如果缓冲空间已满,则将发送者enqueue到发送channel,发送者进入阻塞状态如果缓冲空间未满,则将元素copy到缓冲中,这时发送者就不会进入阻塞状态,最后尝试唤醒等待队列中的一个接受者。
接收channel与发送类似首先也是判断channel的类型,然后如果是有缓冲的channel就判断缓冲中是否有元素,接着从channel中获取接受者,如果取到,则直接从接收者获取元素,并唤醒发送者,本次接收过程完成,如果没有取到接收者,阻塞当前的goroutine并等待发送者唤醒,如果是拥有缓冲的channel需要先判断缓冲中是否有元素,缓冲为空时,阻塞当前goroutine并等待发送者唤醒,缓冲如果不为空,则取出缓冲中的第一个元素,然后尝试唤醒channel中的一个发送者
1.1.12. 通道总结
channel 常见的异常总结,如下图:
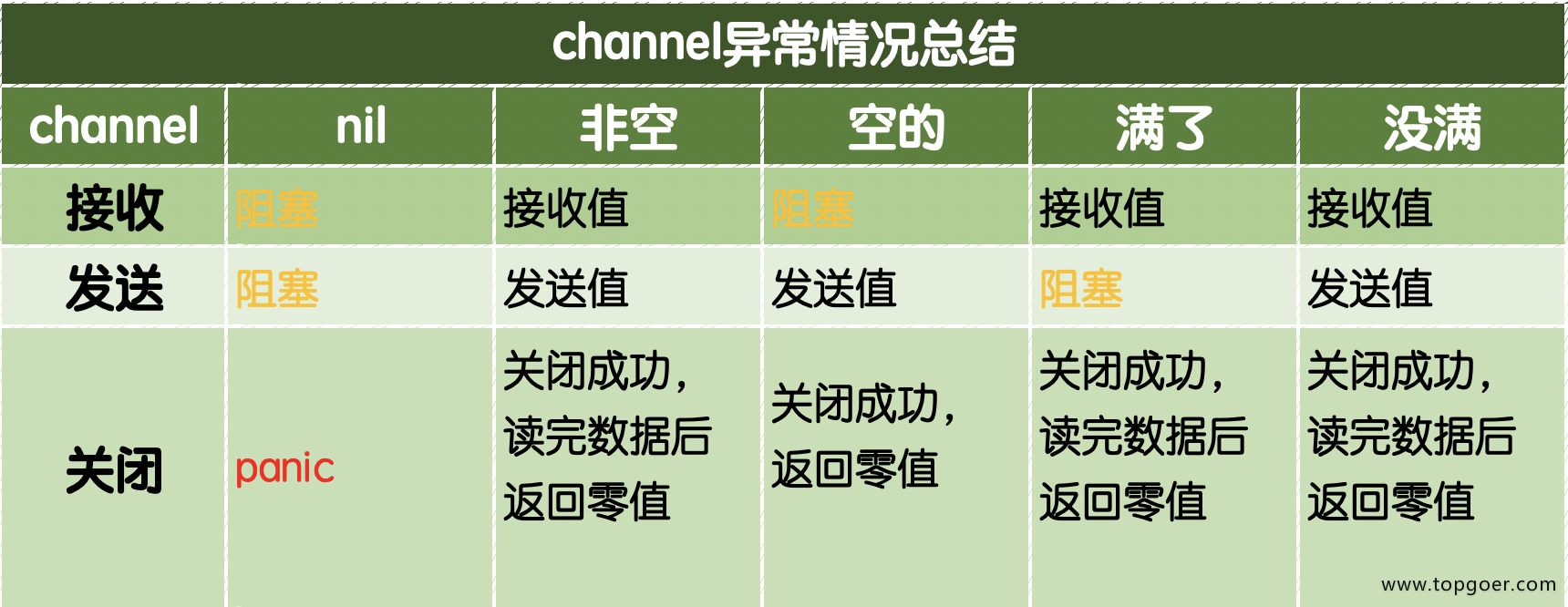
注意: 关闭已经关闭的 channel 也会引发 panic。
channel 为什么是并发安全的呢?是因为 channel 内部使用了互斥锁来保证并发的安全
channel 有哪些应用
定时任务
select {case <-time.After(100 * time.Millisecond):case <-s.stopc:return false}
等待 100 ms 后,如果 s.stopc 还没有读出数据或者被关闭,就直接结束。这是来自 etcd 源码里的一个例子,这样的写法随处可见。
执行定时任务
func worker() {ticker := time.Tick(1 * time.Second)for {select {case <- ticker:// 执行定时任务fmt.Println("执行 1s 定时任务")}}}
解耦生产方和消费方
服务启动时,启动 n 个 worker,作为工作协程池,这些协程工作在一个 for {} 无限循环里,从某个 channel 消费工作任务并执行:
func main() {taskCh := make(chan int, 100)go worker(taskCh)// 塞任务for i := 0; i < 10; i++ {taskCh <- i}// 等待 1 小时select {case <-time.After(time.Hour):}}func worker(taskCh <-chan int) {const N = 5// 启动 5 个工作协程for i := 0; i < N; i++ {go func(id int) {for {task := <- taskChfmt.Printf("finish task: %d by worker %d\n", task, id)time.Sleep(time.Second)}}(i)}}
5 个工作协程在不断地从工作队列里取任务,生产方只管往 channel 发送任务即可,解耦生产方和消费方。
控制并发数
有时需要定时执行几百个任务,例如每天定时按城市来执行一些离线计算的任务。但是并发数又不能太高,因为任务执行过程依赖第三方的一些资源,对请求的速率有限制。这时就可以通过 channel 来控制并发数。
var limit = make(chan int, 3)func main() {// …………for _, w := range work {go func() {limit <- 1w()<-limit}()}// …………}
构建一个缓冲型的 channel,容量为 3。接着遍历任务列表,每个任务启动一个 goroutine 去完成。真正执行任务,访问第三方的动作在 w() 中完成,在执行 w() 之前,先要从 limit 中拿“许可证”,拿到许可证之后,才能执行 w(),并且在执行完任务,要将“许可证”归还。这样就可以控制同时运行的 goroutine 数。
这里,limit <- 1 放在 func 内部而不是外部,原因是:
如果在外层,就是控制系统 goroutine 的数量,可能会阻塞 for 循环,影响业务逻辑。 limit 其实和逻辑无关,只是性能调优,放在内层和外层的语义不太一样。
还有一点要注意的是,如果 w() 发生 panic,那“许可证”可能就还不回去了,因此需要使用 defer 来保证

若有收获,就点个赞吧
0 人点赞
