认识大数据
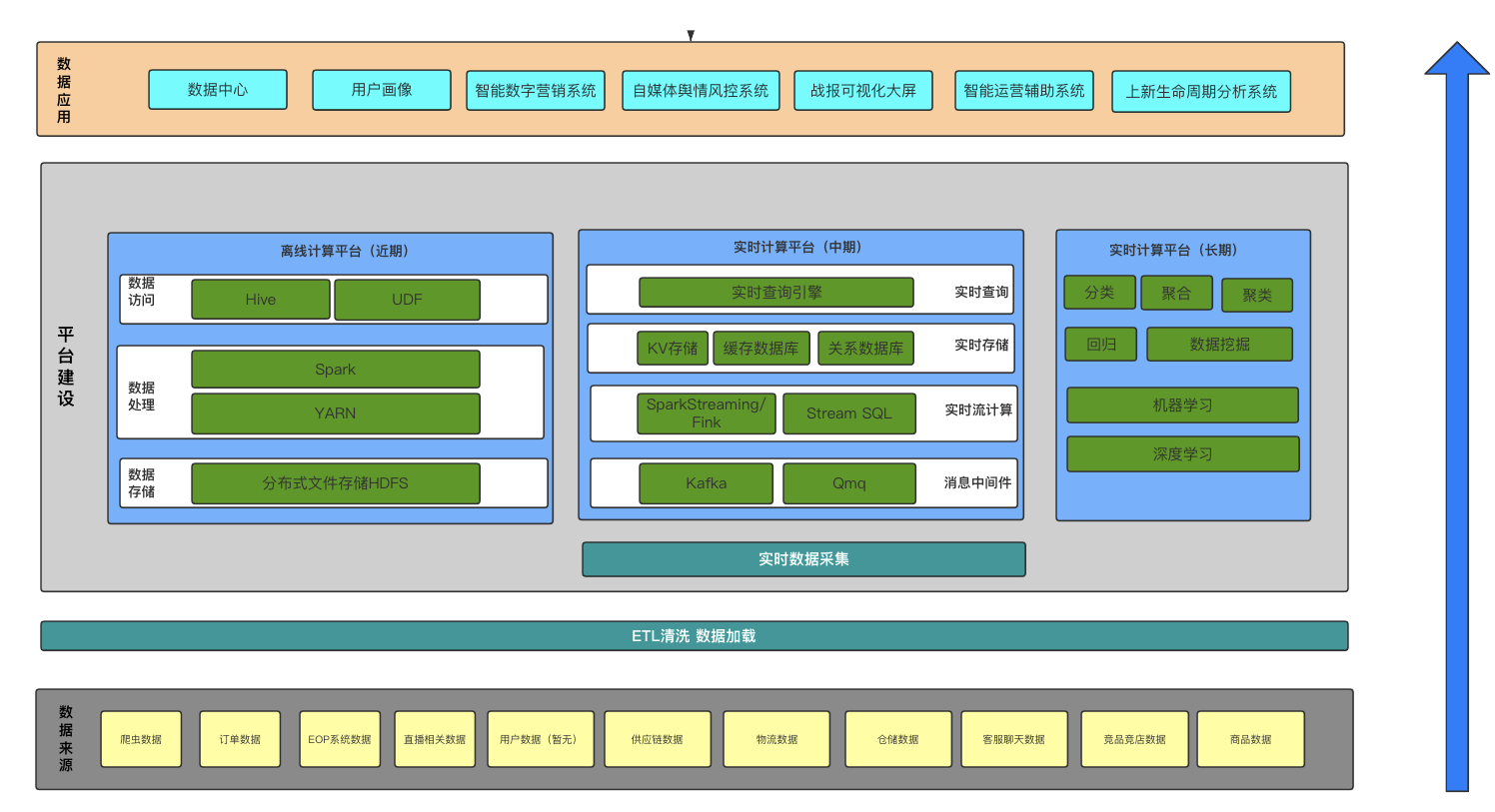
三驾马车: GFS谷歌分布式文件系统、MapReduce大数据计算引擎和 NoSQL数据库系统BigTable
Yarn: 早期MapReduce即是执行引擎,又是资源调度框架,服务器集群的资源调度管理由mapReduce自己完成。后来把资源调度分离出来,这就是yarn.
Spark: 2012年的时候,内存已突破容量和成本限制,Spark解决了MapReduce在机器学习计算时性能非常差的问题,一经推出,倍受追捧,逐步替代MR在企业应用中的地位。
hadoop: hadoop = HDFS + MapReduce (分布式文件存储 和 大数据计算引擎)
Hive: 支持使用SQL语句进行大数据计算,比如你写一个select的数据查询语句,Hive会把sql语句转化成mapReduce的计算程序。
Sqoop: 专门把数据库中的数据导入导出到hadoop平台;
Flume: 针对大规模日志进行分布式收集、聚合和传输
Oozie: MapReduce工作流高度引擎
Storm/Flink/SparkStreaming :大数据时实计算 ,流计算(MR和spark则是离线计算,一般计算以天为单位的历史数据)
Hbase/Cassandra:海量数据存储的数据库系统。其中HBase是从Hadoop中分离出来基于HDFS存储的NOSQL
大数据的发展
搜索引擎时代 -> 数仓时代 -> 数据挖掘 -> 机器学习时代
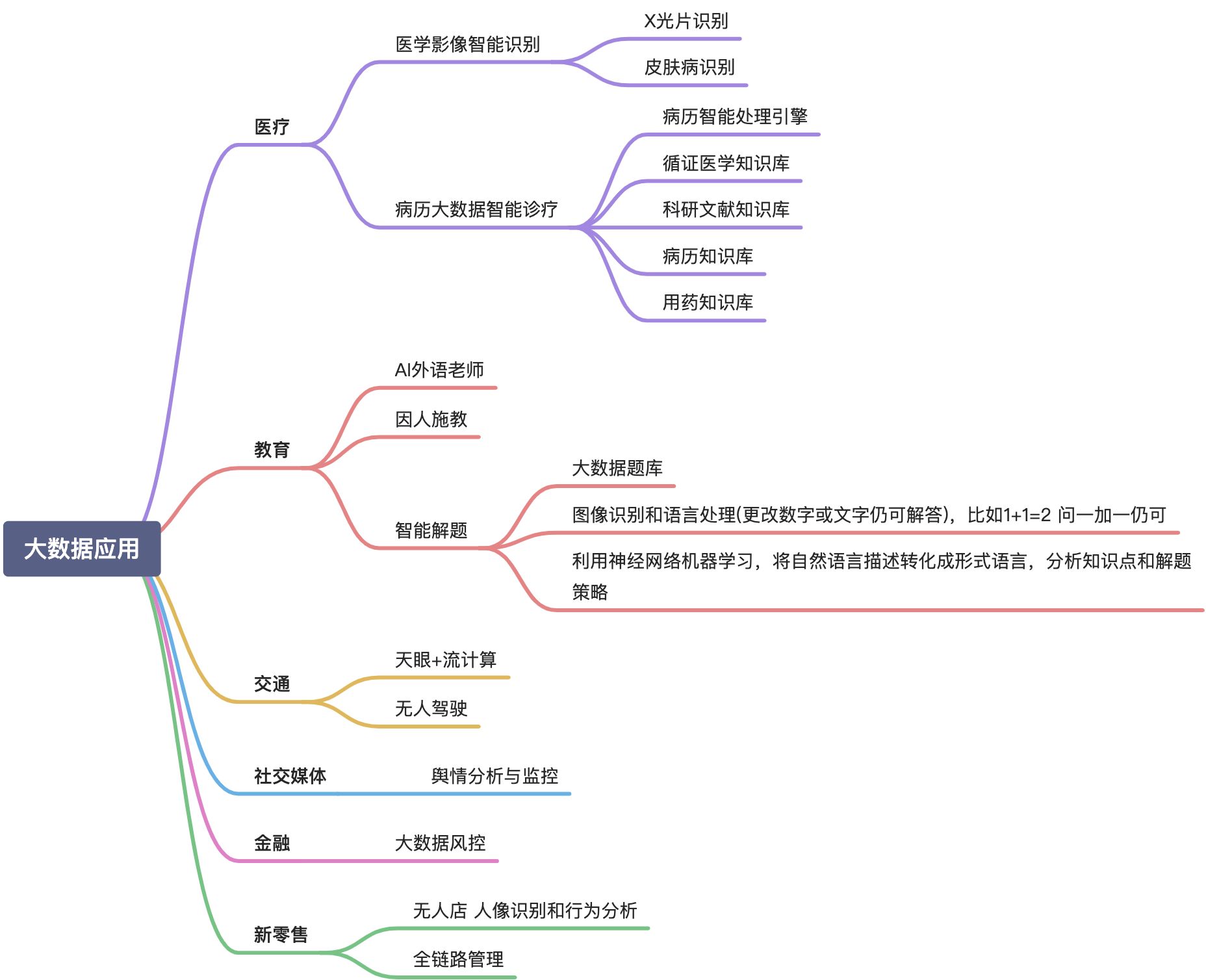
大数据的应用

若有收获,就点个赞吧
0 人点赞
