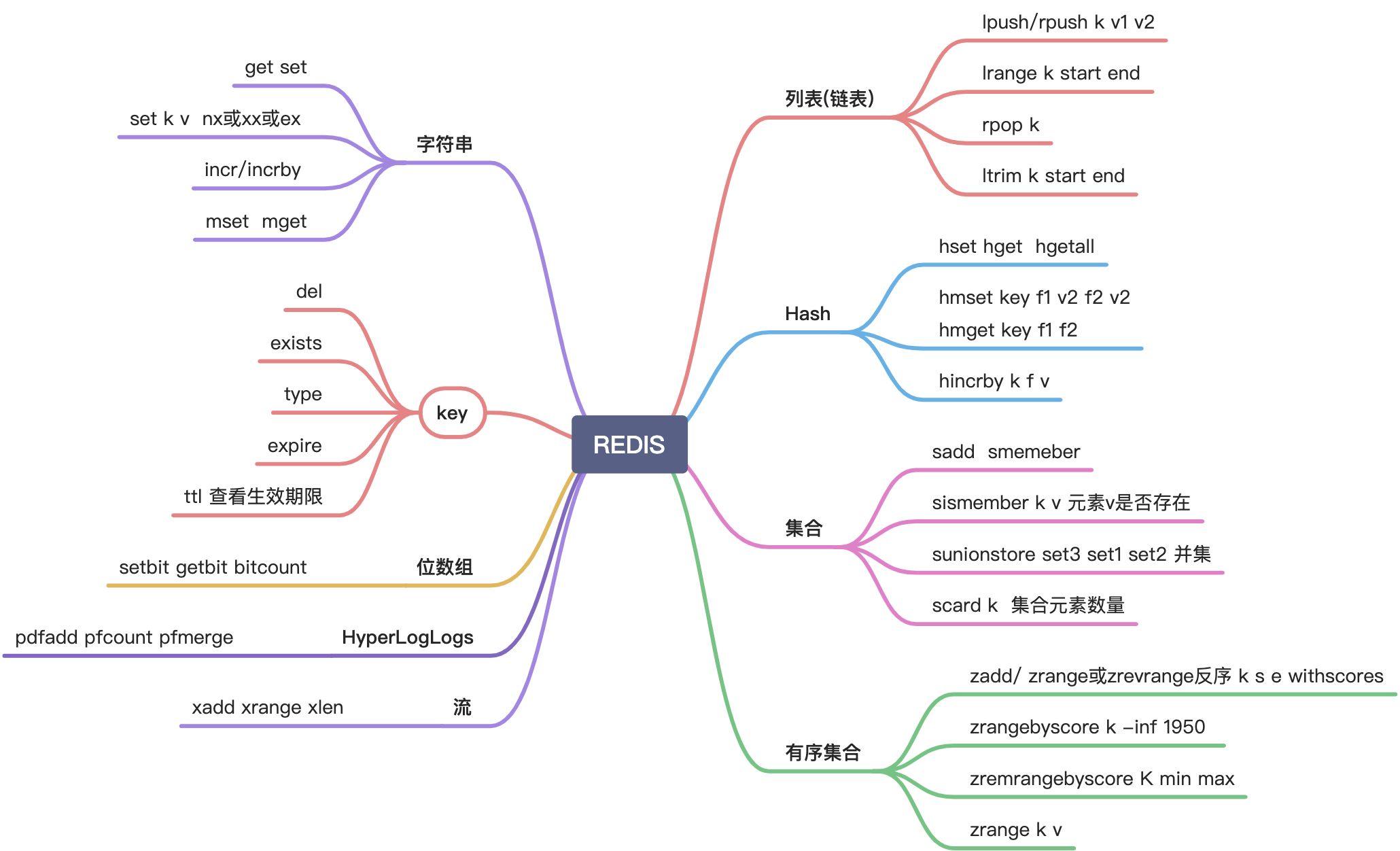
Key
redis key是二进制安全的,任何二进制序列都可以用做key.
- 字段串
- 图片内容
- 空串等都可以
规则:
- key不要太长
- 非常短也不好 不易读且容易碰撞
- key格式尽量统一
- key最大为512M
过期时间
过期时间的精度为毫秒 ,到期时间的分辨率始终为1毫秒
数据结构
字符串
typedef struct dictht {//哈希表数组dictEntry **table;//哈希表大小unsigned long size;//哈希表大小掩码,用于计算索引值unsigned long sizemask;//该哈希表已有节点的数量unsigned long used;}
SDS
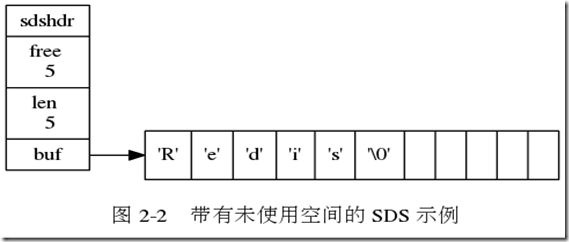
- buf char数组 是用于保存SDS所表示的字符串的char数组,以空字符结尾(以便redis可以直接复用c语言原生字符串操作函数)
- len sds字符串长度,并不是array的length
- free buf array的空闲空间,这一属性用于空间换时间,有了它redis可以预分配空间和惰性空间释放的操作。
预分配空间:
- 当sds的len小于1M时,当向sds添加字符,char数组需要扩容时,char数组将扩容到字符串修改后的len的2倍+1
- 当大于1M时,当向sds添加字符,char数组需要扩容时,char数组将扩容到字符串修改后的len+1M
惰性空间释放
并不会每次修改字段串以后,都立即数组扩容或释放空间,而是在起容量时预留空间扩容。
列表
typedef struct list{//表头节点listNode * head;//表尾节点listNode * tail;//链表长度unsigned long len;//节点值复制函数void *(*dup) (void *ptr);//节点值释放函数void (*free) (void *ptr);//节点值对比函数int (*match)(void *ptr, void *key);}
列表 list (lrange ),底层实现是一个双端链表。
redis链表特性如下:
- 双端
- 无环 (头部的prev和尾部的next都指向Null)
- 带表头指针和表尾指针 (head/tail)
- 带长度计数器 len
- 多态 可以用于保存各种不同类型的值
Hash
C语言并没有内置Map这种数据结构,因此reids需要自己构建字典实现。
字典
typedef struct dict {// 类型特定函数dictType *type;// 私有数据void *privedata;// 哈希表dictht ht[2];// rehash索引 表示渐进式rehash执行到dictEntry数组的第几个元素了in trehashidx;}
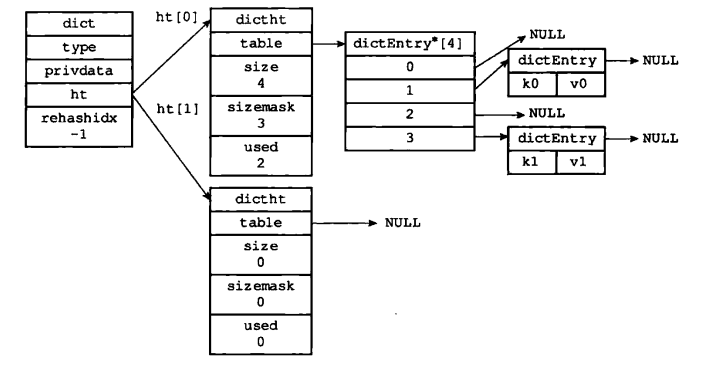
ht是一个包含两个hash表的数组,一般情况下,字典只会使用ht[0], ht[1]是在rehash的时候使用
hash表
typedef struct dictht {//哈希表数组dictEntry **table;//哈希表大小unsigned long size;//哈希表大小掩码,用于计算索引值unsigned long sizemask;//该哈希表已有节点的数量unsigned long used;}
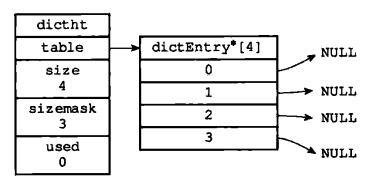
一个hash表包含一个dictEntry数组, dictEntry是一个键值对。size属性记录了哈希表的大小,used表示已使用的节点数量。
Entry节点
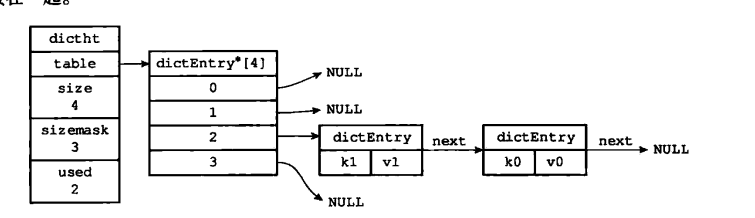
和JavaMap一样,这里是链表+数组的结构,如上图在dictEntry数组的index=2的位置,发生了hash碰撞,以链表处理hash冲突。
哈希算法
当需要向hash表添加键值对时,先根据键值对的key计算出key对应的hash值,然后根据hash值计算出key在dictEntry数组中的索引值,最后将键值对添加在数组所在下标位置的链表上
redis使用的是MurmurHash算法来计算key的hash值
rehash
当不断向链表追加键值对时,如上图,假如dictEntry数组只有4个元素,而Hash表已经保存了1000个键值对,也就是说1000个键值对分布在4个链表上,此时hash表的负载因子 非常高,get一个键值要遍历链表的期望次数是250次,这时候就需要将dictEntry数组扩容,同时也伴随着rehash的过程。
负载因子

当目前没有执行bgsave时,负载因子大于等于1时,需要扩容;当在执行bgsave,并且负载因为大于等于5时,需要扩容。同样地当小于0.1时候会收缩。
过程
rehash指的是重新计算键的hash值和索引值。数组扩容,则原来的链表的hash值和索引值可能会改变,也就是可能会被分配到数组的其他index上去。而数组收缩则反之。
过程:
- 为ht[1]分配空间
- 将所有键值重新计算hash值和索引值, 然后迁移到ht[1] 指定的位置
释放ht[0],将ht[1]设置为ht[0], 并创建一个空的新ht[1]
渐进式rehash
现实中,字典的used可能会非常庞大,服务器无法在短时间内一次性、集中地将全部的键值rehash到ht[1],而是分多次、渐进式完成。
渐进式rehash步骤:为ht[1]分配空间
- 在字典初始化索引计数器变量rehashidx=0,表示rehash正式开始
- 在rehash期间,每次对字典执行curd操作时,程序除执行常规操作外,还会将rehashidx索引上的所有键值rehash到ht[1],完成后将rehashidx+1
- 随着操作不断执行,在第size次操作时,最终ht[0]上的所有键值都会被rehash迁移到ht[1], 此时rehashidx将被设置为-1,表示迁移完成。、
因渐进式rehash可能是一个漫长的过程,所以在rehash期间crud操作的读操作,需要两次计算hash值和索引值,即先去老表ht[0]中查,查不到表示已迁移到ht[1]中,则需要使用新的Hash算法去ht[1]中查找,更新和删除操作之前的读操作也是如此。而create操作,则一定会添加到ht[1]中去
zset
指令
- zrange k start end withscores
a
1
b
2
- zrangebyscore k -inf 20
选出集合k中score=负无穷到20之间的所有元素
- zremrangebyscore k min max
删除min和max区间内的所有元素
- zrange k v
集合k按socre从小大到排序后,取出v的排序下标
跳表
空间换时间
- 查。 每次跳跃会少遍历很多元素
- 写。
- 0层链表插入
- 随机造层,修正指针。
t_zset.c # zslRandomLevel 跳表随机造层 最高64层
参考文档

若有收获,就点个赞吧
0 人点赞
