消息中间件功能与选型
消息队列 是 队列的一种数据结构,作为中间件提供服务
MQ功能
异步、解耦
不需要同步执行的远程调用异步处理加快响应
两个或多个应用不相互依赖
流量削峰
流量到达高峰时,用mq缓冲大量请求,匀速消费,当消息堆积过多时
,可以动态扩展消费端,保证不丢失重要请求。
大数据处理
日志、用户行为、系统状态等数据文件作为消息收集到主题中
数据使用方可以订阅自己感兴趣的数据内容互不影响,进行消费
异构系统
跨语言
选型
| 类型 | 优点 | 缺点 | 使用场景 |
|---|---|---|---|
| rabbitmq | 轻量、延迟低 消息可靠性高 功能全面 |
1. 对消息堆积极不友好 1. 吞吐量相对较低 1. erlang开发 难以扩展开发 |
小规模吞吐量的应用场景 |
| RocketMQ | 高吞吐、高可用 功能强大 |
官方文档简单 只支持java |
几乎所有mq消息场景 |
| Kafka | 吞吐量大 性能好 集群高可用 |
会丢数据 功能单一 |
日志分析 大数据采集 |
性能对比
- rabbitmq 5.9w/s
- rocketmq 11.6w/s
- kafka 17.3w/s (csdn博客有用顶配机测试最高吞吐为2千万/w)
RocketMQ
简介
低延迟、高可用、行业可发展性好、万亿级消息容量、对大数据友好、支持大量消息堆积
主流的MQ有很多,比如ActiveMQ、RabbitMQ、RocketMQ、Kafka、ZeroMQ等。
之前阿里巴巴也是使用ActiveMQ,随着业务发展,ActiveMQ IO 模块出现瓶颈,后来阿里巴巴 通过一系列优化但是还是不能很好的解决,之后阿里巴巴把注意力放到了主流消息中间件kafka上面,但是kafka并不能满足他们的要求,尤其是低延迟和高可靠性。
所以RocketMQ是站在巨人的肩膀上(kafka)MetaQ的内核,又对其进行了优化让其更满足互联网公司的特点。它是纯Java开发,具有高吞吐量、高可用性、适合大规模分布式系统应用的特点。 RocketMQ目前在阿里集团被广泛应用于交易、充值、流计算、消息推送、日志流式处理、binglog分发等场景。
RocketMQ角色

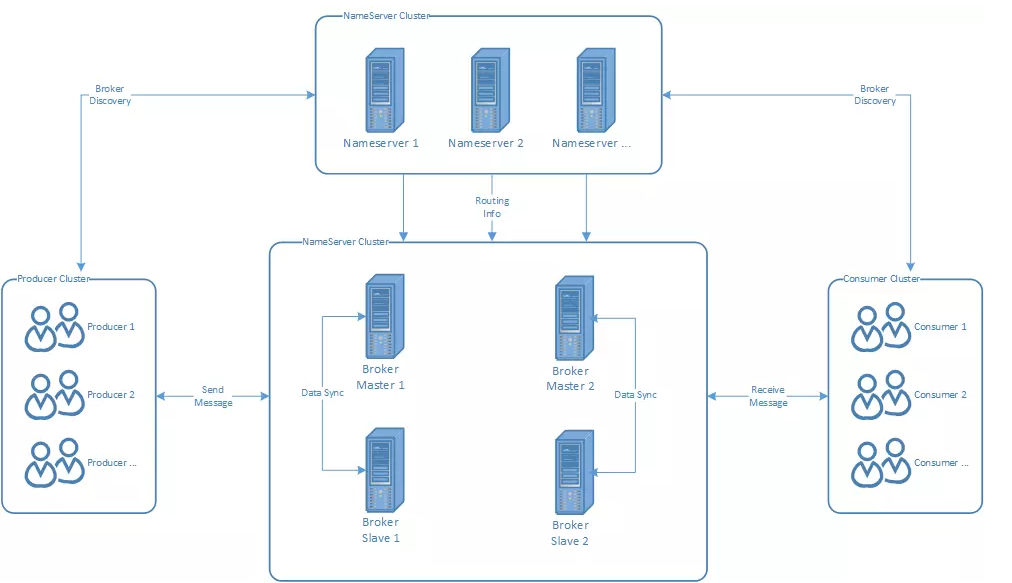
图【1】 rocketMQ部署架构
broker
- broker分别向consumer和producer收发消息
- 向nameserver上报自己的信息
- 消息存储、转发
- 每个broker节点,在启动时都会遍历所有的nameserver列表,并把自己的信息注册到nameserver
每个broker都会与nameserver集群中的所有节点建立长连接,定时注册topic信息到nameserver
broker集群
broker高可用,可以配置成Master/Slave结构,主从模式
一个Master可以有多个slave
Master与Salve之间主从关系是通过指定相同的brokerName,主从内部brokerName相同,brokerid不同,brokerId=0为主,其余为从
- Master多机负载,可以部署多个broker
producer
- 消息生产者
- 通过集群中的其中一个节点建立长连接,获取topic路由信息,包括topic下面哪些queue,这些queue分布在哪些broker上
- 接下来向提供topic服务的master建立 长连接,且定时向master发送心跳
consumer
消息者通过nameserver获取topic路由信息,连接到对应的broker上
由于Broker Master和slava都可读消息,因此Consumer会与Master Slave都建立连接
nameserver
由netty实现,提供路由字处理、服务注册、服务发布的功能,是一个无状态节点。
nameserver接受集群注册信息并保存,然后提供心跳机制检查其他角色的健康状况。每个nameserver将保存所有路由信息和用于客户端查询的队列信息。
- nameserver 是服务发现者,集群中的各个角色都需要定时向nameserver上报状态,以便互相发现彼此,超时不上报,会被nameserver剔除
- namesever支持集群 当多个nameserver存在时,其他角色需要逐个上报
- nameserver集群间互不通信 没有主从主备概念
为什么NameServer不使用Zk?
nameserver不支持各节点信息通信,也就是说nameserver之间允许数据不同步,避免了数据强一致性保证带来的性能消耗。
Topic是一个逻辑概念,实际上message存储在queue上
消息
消息分类
集群消息
集群消息是 集群化部署消费者
集群消费时,mq认为一条消息只需要被集群内的一个消费者处理即可
特点:
- 每个集群(GID)消费一次
- 消息重投时 不能保证路由到同一台机器
- 消费状态由borer维护
广播消息
特点:
- 保证每个消费者消费一次
- 消费进度由consumer维护
- 消费失败的消息不会重投
消息发送方式
同步消息
异步消息
send(MessageQueue, SendCallback) 生产者发送完毕消息立马返回,broker收到消息刷盘后执行生产者回调函数
单向发送
sendOneWay(``MessageQueue``) 只管发 不管收到没有,有无响应
批量发送
impleBatchProducer.send(messageList)
特点:
消息存储
存储方式
RocketMQ使用文件系统持久化消息,性能比使用DB要高
M.2 NVME协议的磁盘存储
数据0copy技术
发送消息时存储流程
存储文件与内存映射
存储结构
commitLog 存储消息的详细内容,按照消息收到顺序,所有消息存储在一起,每个消息存储后记录一个OffSet(记录消息位置)
内部:mappedFileQueue -> MappedFile(默认1G)
ConsumerQueue
通过消息偏移量创建的消息索引
indexFile
消息的key和时间戳索引
刷盘机制
在CommitLog初始化时,判断配置文件加载相应的servcie
- 同步刷盘 消息被broker写入磁盘后才给producer响应
- 异步刷盘 消息被broker写入内存后立即给producer响应,当内存消息积累到一定程序时才写入磁盘
文件恢复与过期删除机制
索引
消息重试
- producer 默认发送2次,默认不向其他broker重试setRetryAnotherBorkerWhenNotStoreOK
- consumer
- 消费超时 单位分钟
- 发送ack 消费失败 RECONSUME_LATER
消息种类
顺序消息
simpleBatchProducer.send(messageList)
攒够一批再发
对时延要求不高,但量比较大
一个大消息split成多条
SplitBatchProducer过滤消息
TAG与SQL92
消息过滤在Broker端过滤,缺点:broker压力大。filterConsumer把过滤条件上推给broker,broker根据规则完成过滤。
可以使用tag来过滤消息 consumer.subscribe(“TopicTest”, “TagA||TagB”);// * 代表订阅Topic下的所有消息
-
FilterServer过滤机制
事务消息
实现方式:
半消息:预处理消息,当broker收到此类消息后,会存储到半消息队列
- 检查事务状态:Broker会开启一个定时任务,消费半消息队列中的消息,每次执行任务会向消息发送者确认事务状态,如果未知等待下一次回调。
- 超时:如果超过回查次数,默认回滚消息
TransactionListener事务监听处理的两种方法
- ExecuteLocalTransaction
半消息发送成功触发此方法来执行本地事务
- CheckLocalTransaction
Broker将发送检查消息来检查事务状态,并将调用此方法来获取本地事务状态
ACL权限控制
消息消费
Push&Poll
push模式
broker把消息推到consumer,consumer被动消费
poll模式
PollConsumer.pullBlockIfNotFound(messageQueue, null, offset, maxNums_32);
consumer去meesageQueue主动拉 ,从偏移量开始,默认最大拉32条消息。
偏移量:一个topic下的所有消息,分片存储在每一个meeasgeQueue里,每个messageQueue存在于一个的Broker节点上,而消息者主动拉取时的偏移量,指的是(消息者组)在messageQueue中已消费的位置。
litePollConsumer
- 支持从指定messageQueu拉消息
- 支持批量拉
LitePollConsumer.fetchMessageQueues(“topic_a”);
消息消费偏移量
每个broker中的queue在收到消息时会记录offset,初始值为0,每记录一条消息offset会+1
maxOffset/minOffset
consumerOffset 当前消费位置
diffTotal 消息堆积数
消息处理队列ProcessQueue
poll->长轮询
长轮询:建立长连接,连接一旦建立,不会断开
短轮询:每次轮询都要重新连接
Consumer -> Broker RocketMQ采用的长轮询建立连接
- consumer的处理能力Broker不知道
- 直接推送消息 broker端压力较大
- 采用长连接有可能consumer不能及时处理推送过来的数据
- pull主动权在consumer手里
消息负载与算法
相同的group中的每个消费者只消费topic中的一部分内容
group中的所有消费者都参与消费过程,每个消费者消费内容不重复,从而达到负载均衡的效果
消费者动态添加
ACK
消费进度与OffSet
RocketMQ集群 HA
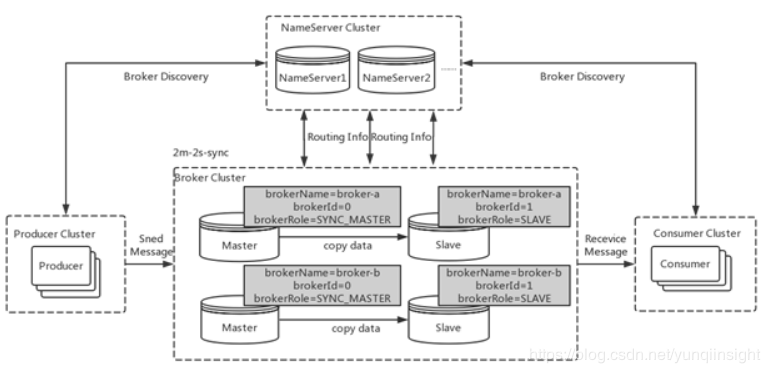
单Master模式
只有一个 Master节点
优点:配置简单,方便部署
缺点:这种方式风险较大,一旦Broker重启或者宕机时,会导致整个服务不可用,不建议线上环境使用
多Master模式
一个集群无 Slave,全是 Master,例如 2 个 Master 或者 3 个 Master
优点:配置简单,单个Master 宕机或重启维护对应用无影响,在磁盘配置为RAID10 时,即使机器宕机不可恢复情况下,由与 RAID10磁盘非常可靠,消息也不会丢(异步刷盘丢失少量消息,同步刷盘一条不丢)。性能最高。多 Master 多 Slave 模式,异步复制
缺点:单台机器宕机期间,这台机器上未被消费的消息在机器恢复之前不可订阅,消息实时性会受到受到影响
多Master多Slave模式(异步复制)
每个 Master 配置一个 Slave,有多对Master-Slave, HA,采用异步复制方式,主备有短暂消息延迟,毫秒级。
优点:即使磁盘损坏,消息丢失的非常少,且消息实时性不会受影响,因为Master 宕机后,消费者仍然可以从 Slave消费,此过程对应用透明。不需要人工干预。性能同多 Master 模式几乎一样。
缺点: Master 宕机,磁盘损坏情况,会丢失少量消息。
多Master多Slave模式(同步双写)
每个 Master 配置一个 Slave,有多对Master-Slave, HA采用同步双写方式,主备都写成功,向应用返回成功。
优点:数据与服务都无单点, Master宕机情况下,消息无延迟,服务可用性与数据可用性都非常高
缺点:性能比异步复制模式略低,大约低 10%左右,发送单个消息的 RT会略高。目前主宕机后,备机不能自动切换为主机,后续会支持自动切换功能
主备切换 故障转移
在 RocketMQ 4.5 版本之前,RocketMQ 只有 Master/Slave 一种部署方式,一组 broker 中有一个 Master ,有零到多个 Slave,Slave 通过同步复制或异步复制的方式去同步 Master 数据。Master/Slave 部署模式,提供了一定的高可用性。 但这样的部署模式,有一定缺陷。比如故障转移方面,如果主节点挂了,还需要人为手动进行重启或者切换,无法自动将一个从节点转换为主节点。因此,我们希望能有一个新的多副本架构,去解决这个问题。
新的多副本架构首先需要解决自动故障转移的问题,本质上来说是自动选主的问题。这个问题的解决方案基本可以分为两种:
利用第三方协调服务集群完成选主,比如 zookeeper 或者 etcd(raft)。这种方案会引入了重量级外部组件,加重部署,运维和故障诊断成本,比如在维护 RocketMQ 集群还需要维护 zookeeper 集群,并且 zookeeper 集群故障会影响到 RocketMQ 集群。 利用 raft 协议来完成一个自动选主,raft 协议相比前者的优点是不需要引入外部组件,自动选主逻辑集成到各个节点的进程中,节点之间通过通信就可以完成选主。
整合
与Spring整合
与springcloud整合
监控与运维
rocketmq-console监控平台
命令行mqadmin
- updateTopic
- deleteTopic
- topicStatus
- topicRoute
- brokerStatus

若有收获,就点个赞吧
0 人点赞
