简介
点击查看【bilibili】
感谢!!!视频2piece共2个多小时。
快速入门
什么是hashmap
HashMap是hash表对map接口的实现,是数组和链表的结合,HashMap同时兼备快速插入和读取的特性。
hashmap提供所有可选的映射操作, 并允许使用Null值和null键。
hashmap并非线程安全,当多个线程写入hashmap时,可能会导致数据不一致。
源码重要全局变量
loadFactor 表示负载因子,默认0.75,当负载因子高于0.75会扩容。
threshold表示所能容纳的键值对的临界值,计算公式为:数组长度*负载因子
modCount字段用来记录hashmap内部结构发生变化的次数。
常量INITIAL_CAPACITY 初始容量为16
常量TREEIFY_THRESHOLD = 8 树化临界值 大于8转红黑树
常量UNTREEIFY_THRESHOLD =6 仅在resize时使用,桶内元素<=6个,存链表。
常量MIN_TREEIFY_THRESHOLD = 64 最小树化容量
结构
hashmap使用数组+链表的数据结构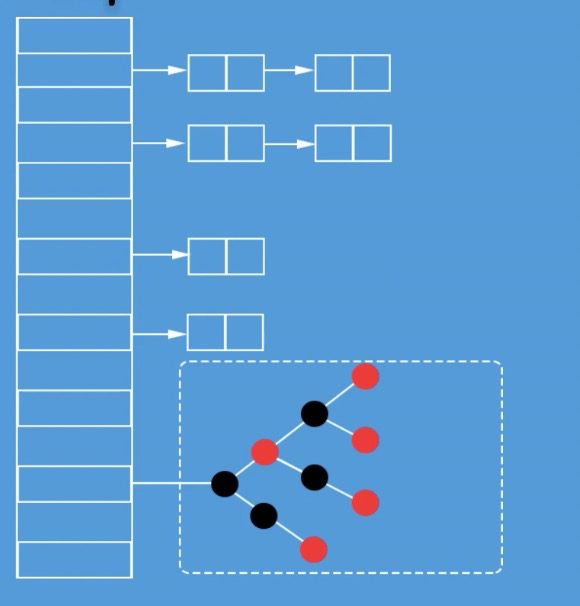
hashmap数组部分称为 hash桶 。当链表长度大于等于8时,链表数据将以红黑树存储,当长度降到6时会转到单向链表
链表遍历的时间复杂度为O(n)
红黑树的时间复杂度为O(log n)
如何设计hashmap?
二进制运算复习
hash
hash值:通过一定的散列算法,把一个固定的输入,转成一个固定的输出,在hashmap中,hash就一个Int值
hashcode计算:
取string的char字符的ascii码,然后再做一定的运算?
hash函数:把hash值打散到 数组的桶 索引位
hash碰撞:不同hash值,通过hash函数 被分配到相同的hash桶。
有哪些hash冲突的解决办法?
1. 再hash
2. 开放寻址
3. 开辟公共溢出区
4. 链地址法(hashmap)
-
如何让设计的hashmap存取效率更高?
已经说了是hashmap,就不要再讲数组+链表,继承数组的快速读和链表的快速插
- 尽可能少的产生hash冲突
- 确实发生hash冲突,使用最佳的数据结构来保证hash桶内的数据最优存取
Hash函数
hash值 -> 数组索引值
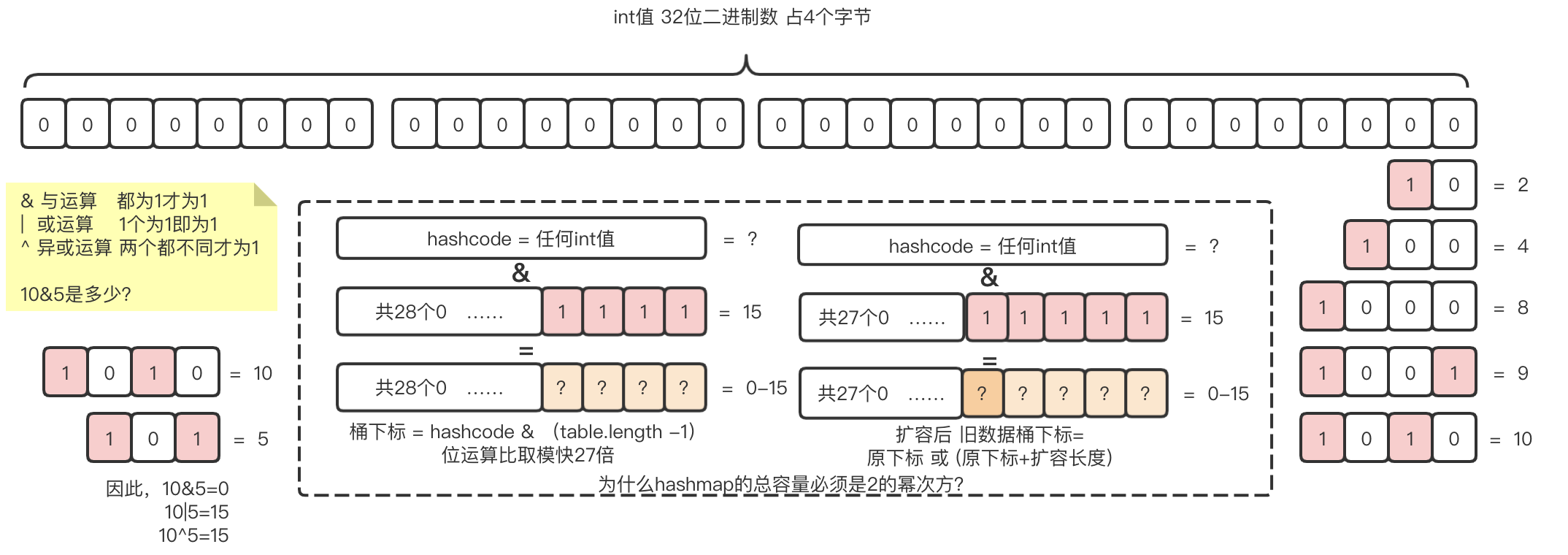
// 伪代码: 拿hash值,计算数组索引值static int indexForHash(int hash, int lenght){return hash & (lenght - 1);}
为什么hashmap的lenght一定要是2的幂次方? 为什么扩容要以2的倍数?
- 位运算比取模运算快27倍。用lenght-1 和 hash值的二进制 与运算 得到的值总是 [0,lenght-1],有取模相同的效果但性能更优. (只有和2的n次方的&运算能够有取模相同的效果,不要再问了)
因此,这个的hash函数的离散率依赖hashCode值。hashcode值越分散,hash冲突越少。
- 1.8以后 resize后不需要rehash 老数据桶下标=旧下标 或者(旧下标+扩容长度)
resize 扩容
什么时候扩容?
JDK 1.7
扩容后再加元素
add时,负载因子高于0.75 且 当前桶下标产生hash碰撞
JDK 1.8
怎么扩容?
JDK1.7
常规操作: 扩容 , rehash然后数据迁移
存在问题:头插法造成单线程迁移产生死环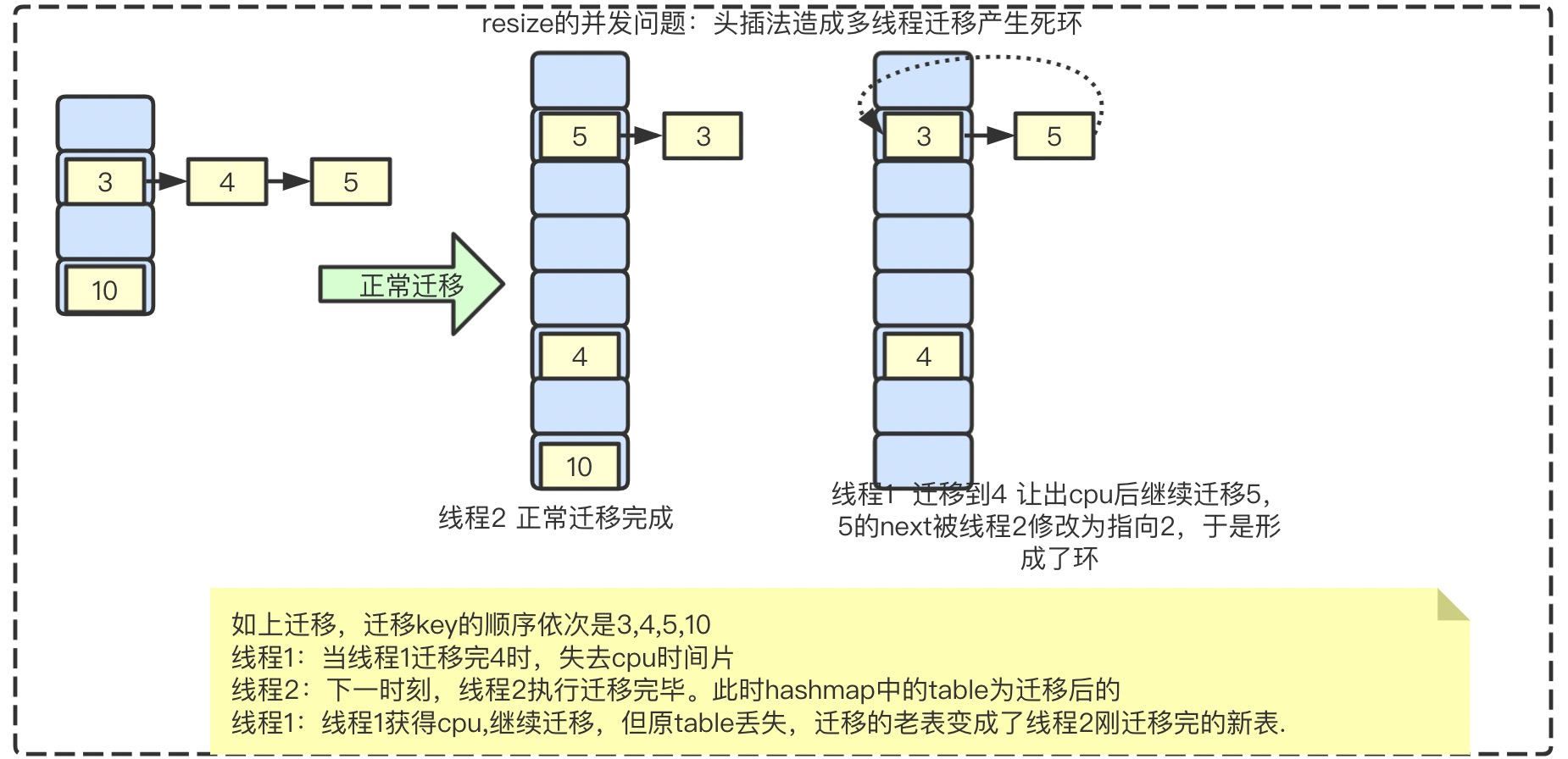
JDK1.8
尾插法 add
桶内为单链表,对单链表迁移
桶内为红黑树(同时也是双向链表),将双向链表进行数据迁移。
为什么桶内元素个数>=8时转红黑树?
根据泊松分布,桶内元素=8个的概率=亿分之6,小于亿分之十,树化的概率很低,但树化后对get的效率提升很高。
扩容后有什么问题(多线程环境)?
jdk1.7
jdk1.8
多线程下 会有数据丢失的问题
什么样的hash函数是最好的?
负载因子低,使数据离散地分布在每个hash桶里面。或者说hash碰撞最少。
源码级解读
put原理
JDK 1.7
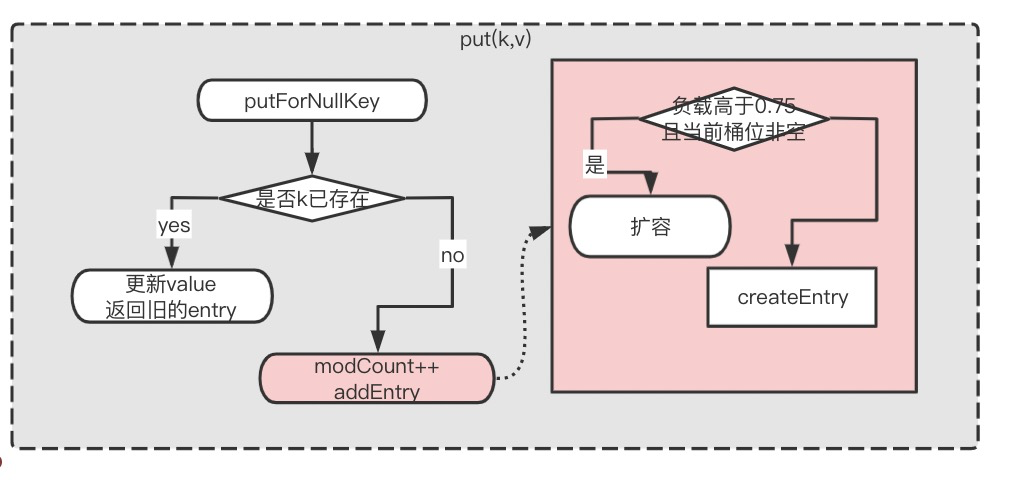
public V put(K k, V v){if(k==null) return putForNullKey(v);// 内部通过一个扰乱算法 得到一个hash值 用于计算数组索引int hash = hash(key);// 计算数组桶下标int i = indexFor(hash,table.length);// 判断是否已存在 重复键for( e at 桶内元素集 ){if (e.hash==hash && (e.key == k || key.equals(k))){// 更新k对应的value值V old = e.value;e.value = value;e.recordAccess(this);return old;}}modCount++;// key不存在 添加新元素addEntry(hash,key,value,i);return null;}void addEntry(int hahs,K k, V v, int bucketIndex){if(size>= threshold && null!=table[bucketIndex]){// 负载高于0.75 且 当前桶位非空// 扩容为两倍resize(2*table.length);// rehashhash= null==key?0:hash(key);buckeyIndex = indexFor(hash,table.length);}// 添加kv到bucketIndexcreateEntry(hash,k,v,bucketIndex);}
jdk1.8
public V put(int hash, K k, V v, boolean evict){int i = (table.length-1)&hash// table初始化if (table==null || table.length==0){n = (table = resize()).length;}// 当前桶位 无元素 直接放入if(table[i]==null) {table[i]=newNode(hash,k,v,null);}else{// 存在hash碰撞Node record = table[i];if(record.key==k){根节点的Key刚好=k, 更新v}else if(当前桶内集合为红黑树){record = putTreeVal(..);}else{桶内集合为单链表for(ele at 链表all){record = ele;if(record.next==null){插入链表尾部if (链表size>8) treeify(...); 添加到树();break;}if(record.key=k) break; // key重复}}if(record!=null){// 如果插入已存在的key更新record值return record;}}// key不存在于新增 且 新增后 超出临界值 直接扩容if(++size>threshold)resize(...)afterNodeInsertion(evict)return null}
扩容
jdk1.7
void resize(int newCapacity){扩容;newTable = new Entry[newCapacity];transfer(newTable,rehash);threshold = 0.75*newCapacity;table = newTable;}void transfer(newtab,rehash){int newcapacity = newtab.length;for (e at table){while(null != e){// 重新计算hash值,数据从老表迁移到新表next = e.next;if(rehash){e.hash==null?0:hash(e.key);}int i = indexFor(e.hash,newCapacity);newTable[i] = e;e=next;}}}
jdk1.8
void resize(){计算new阈值,newCapacity, 初始化table;table = newTable// 执行迁移for (e at oldTable){if(e.next==null) {直接put到newTable;}else if (e instance of TreeNode){// spilt树到新表((TreeNode<K,V>)e).split(this, newTab, j, oldCap);}else{// 单链表迁移while(e.next !=null){// hashmap的老数据 迁移后 桶下标 = 旧下标或者 (旧下标+扩容长度)if(e.hash & oldCap == 0){table[i] = oldTable[i]; //此时全局变量table已指向新表}else{table[i] = oldTable[i+newCap/2]}}}}}
// todo putTreeVal 和 tree.splite 两个源码?

若有收获,就点个赞吧
0 人点赞
