概述
缓存问题
- 什么是redis缓存穿透
- 缓存击穿、穿透、雪崩
- 布隆过滤器的核心原理
- 如何基于本节课知识出去吹比?
缓存穿透
缓存穿透 如果查询数据的时候,在redis查不到,去mysql中查询,这个现象就叫缓存穿透,低频高频都算
低端黑客攻击: 某低端黑客频繁使用 一定不存在的固定id请求你的接口,造成数据库超负荷,怎么办?
解决方案:将任何mysql的查询结果都缓存到redis中 (包括Null )
正常黑客:使用脚本每次换不同的id频繁尝试.
布隆过滤器
优点:有效过滤绝大多数非法攻击; 占用内存小, 1亿数据只占用0.1164GB内存
缺点:必定存在的key必定不会被拦截,必定不存在的key可能不会被拦截(与存在的key发生hash碰撞时)
用途:1.反恶意攻击,过滤不存在的请求 2.避免推荐已读文章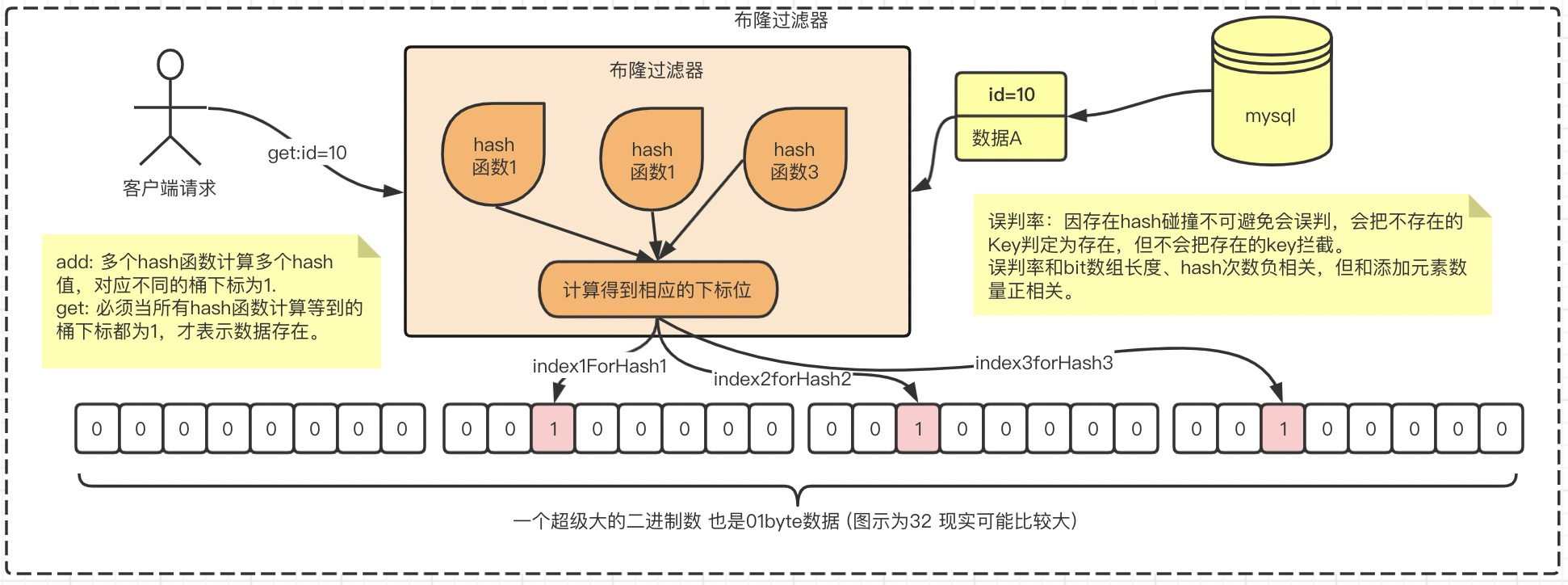
-> 点我去知乎:5分钟搞懂布隆过滤器
布隆过滤器的误判率:(大概10分之1)
布隆过滤器有一个可预测的误判率(FPP):
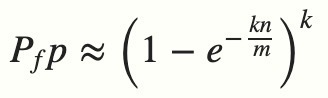
- n 是已经添加元素的数量;
- k 哈希的次数; 3-5个就可以了,如果过多,太多的桶位被标记为1,反而让误判率大幅提高
- m 布隆过滤器的长度(如比特数组的大小);
阿里云redis的tailBloom数据结构实现的布隆过滤器,支持动态扩容,支持用户设定误判率(0-1之间),且扩容时误判率不变,但设定的误判率越低,内存和cpu使用率越高。
在程序设计时,如何向布隆过滤器添加key?
两种方案:1. redis或Mysql get前插入 2. 先get数据,在异步任务中,添加key.
推荐方案二, 异步标记。还没标记成功,get请求就到了怎么办?异步标记的延迟没那么高,基本没必要考虑
有哪些常见的BF常用的hash函数?
【笔试】设计一个布隆过滤器
缓存击穿
缓存失效,海量并发击穿数据库。击穿是穿透的一种特殊情况。
怎么解决缓存击穿?
- 分布式锁。
- 多级缓存 越高级的缓存时郊果越短
- 定时刷新 跑一个job定时主动去更新快要过期的缓存
分布式锁
什么情况需要加分布式锁?
资源共享、请求互斥、多任务环境
Redis分布式锁问题
死锁
- 设置超时时间;
能够避免大多数死锁,但存在问题:
a. 死锁。当正在执行的应用进程和分布式锁中间件同时挂掉,仍然存在死锁可能。redis宕机后 expire不会在下次启动时执行。
b. 一票多卖和超卖。 当timeOut超时时间=10分钟 ,但因机器卡顿/fullGC等原因,程序执行超过10分钟,锁提前释放,则可能会造成一票多卖和超卖问题.
如何优化上述问题?使用基于zookeeper的分布式锁。
【笔试】设计一个分布式锁?
缓存雪崩
所有redis数据在同一时间同时失效,大量请求压在数据上。雪崩也是穿透的一种特殊情况。
什么原因导致雪崩?
- 同一时间失效 : 给每条数据设置时效+随机有效期
- redis宕机 redis集群迁移 -> 集群和主从切换;使用一致性hash算法。
一致性hash算法
数据分片时 水平扩展做更少的数据迁移。
该算法的牛比之处在于:不管集群中有多少机器 ,每次需要迁移数据的机器 不会大于新增机器数+1
缺点:更容易发生数据倾斜(数据不能均匀分布在每台机器)。如何解决?虚拟节点。
缓存与db的一致性
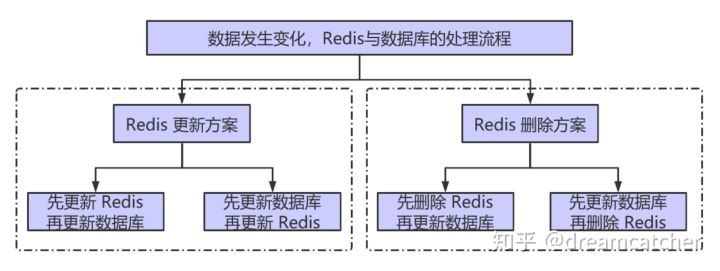
先commit数据库再更新
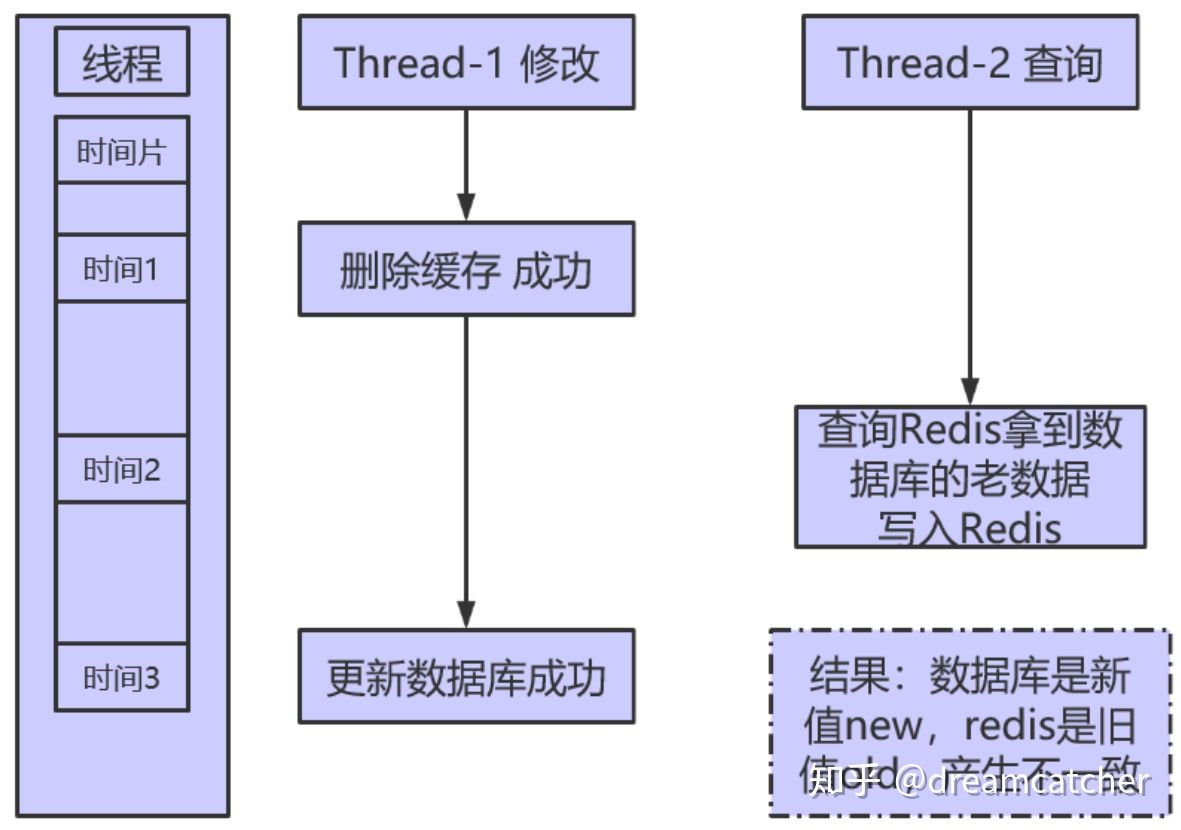
threadA: commit
threadB: commit
threadB: updateCache
thrreadA: updateCache
先删除缓存再commit
延时双删
时间怎么确定 commit最大时间+读写分离主从同步的时间+100ms

若有收获,就点个赞吧
0 人点赞
