二进制安全 存储二进制字节数组 客户端完成编解码。kafka/zk/hbase都是二进制安全的
String
编码 raw和embstr和int
embstr:当sds的Len小于等于44,redis读出串的redisObject为64字节,刚好一个缓存行的大小,
字符sds
数值
bitmap (setbit)
setbit key1 1 1 把bitmap key1 向左偏移1位值设置为1
也就是 00000000 设置为 01000000 当二进数为0-127时,表示ASCII码表中的一个字符 ,如左64表示@
动态扩宽
起始容量是1个8位 0-255 , 当setbit key1 8 1时,会扩容1个8位。
bitcount 区间1计数
setbit bitest 1 1 # 01000000setbit bitest 7 1 # 01000001setbit bitest 10 1 # 01000001 00100000bitcount bitest 0 0 # 2 //计算第一个字节1个数bitcount bitest 1 -1 # //计算第二个字节1的个数
使用场景
- 用户签到: 记录用户签到8年的数据,只需要365个字节。
- 按年分片
- 权限
内核权限系统缓存体系:777 rwx rwx rwx000 000 000 = 000 #无任何权限111 100 001 = 741 #写-读-共享 权限
以车辆业务中台为例,不管内部权限范围、类型如何复杂,一个人对一辆车的权限,只包括对象的元数据权限和人对车的业务数据权限。
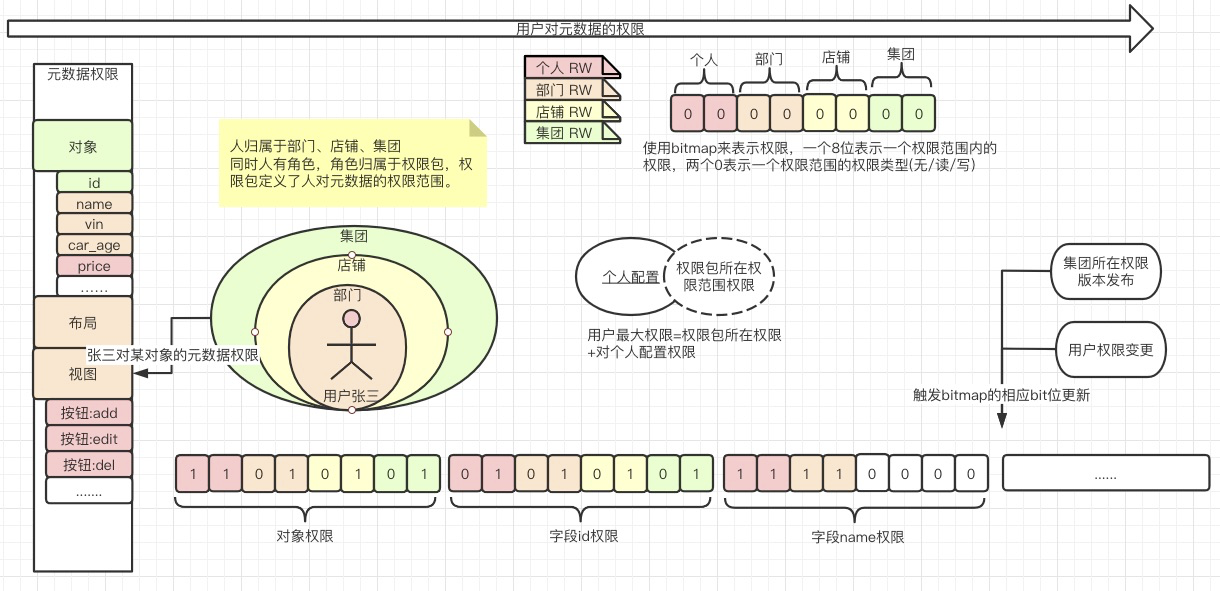
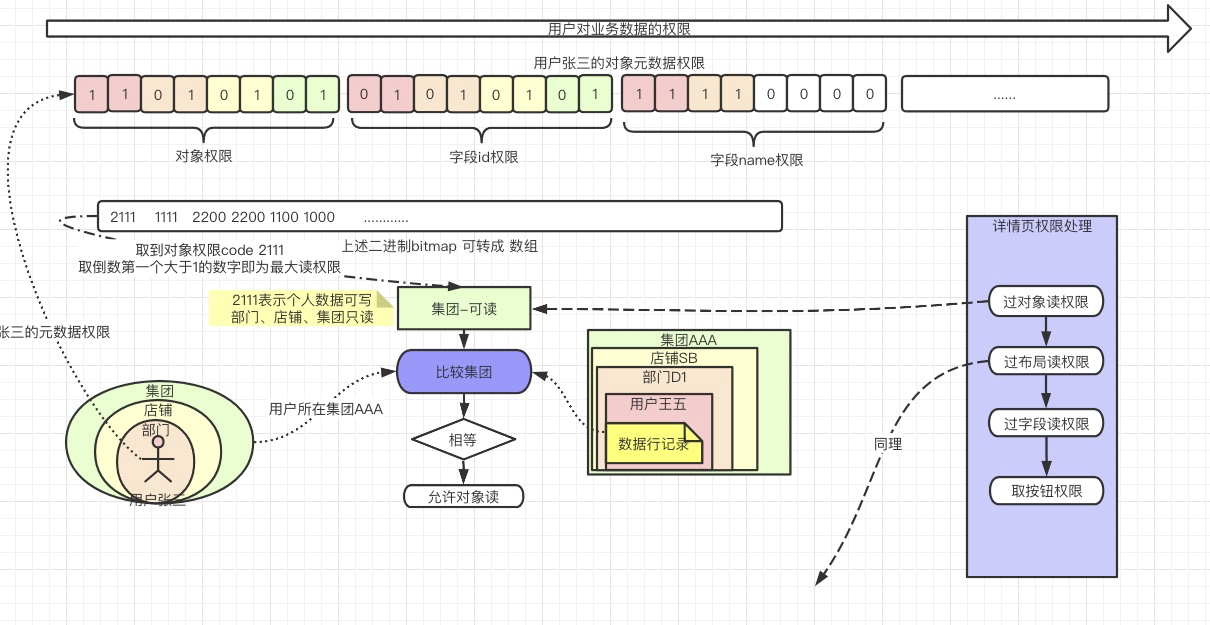
读
- 读取张三的权限时,需要读出张三的元数据权限,简单的本地计算,可得到对象权限、有权限的字段列表、视图、布局、有权限的按钮列表等。
- 读取张三对这辆车的数据权限。
写
数据权限由数据归属店铺、归属人、归属集团、归属部门和人的权限范围决定的,在新增和编辑时,可能会影响权限变更,当新增车辆时,更新所有用户的???
- 活跃用户数统计
同比(看去年)/环比
若用户id自增(不是自增Id转化成自增),然后每个用户将被映射在一个n个0组成的bitmap里(n=用户数),用户登录时,将其对准的偏移位设置为1. 这样就可以统计一段时间内有多少活跃用户。
# 用户202101月登录情况setbit _202101 99 1 #id=99的用户 登录过setbit _202101 100000 1 #id=十万的用户 登录过#用户202102月的登录情况setbit _202102 28 1 # id=28的用户 2月登录过#21年1月活跃用户数bitcount _202101 0 -1 # 2# 21年1月和2月活跃用户数bitop or res_0102 _202101 _202102 #把1月和2月两个月的bitmap 或运算,结果输出到res_0102bitcount res_0102 #计算两个月共有多少活跃用户 =3
- 12306抢票
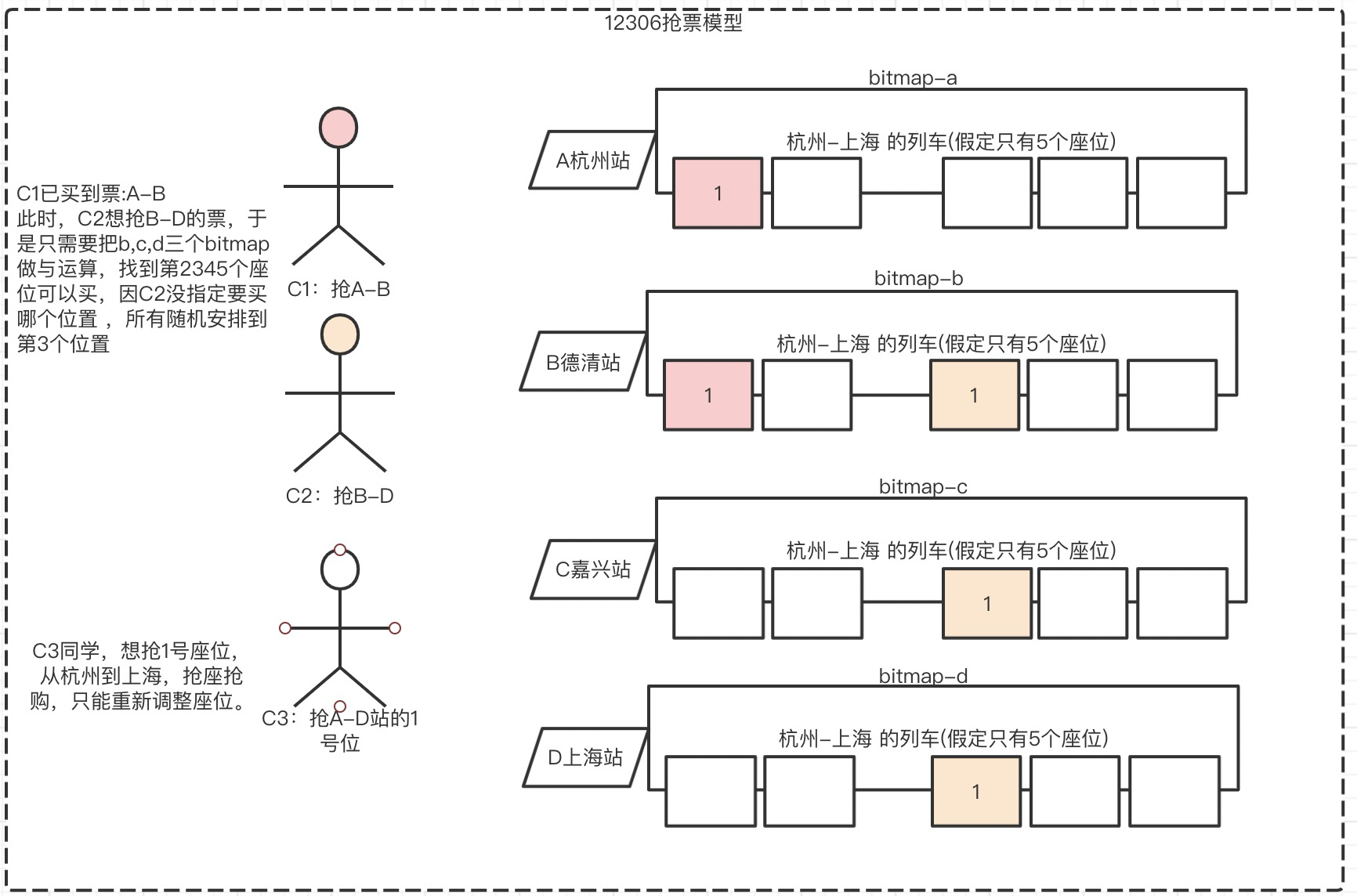
bitmap与运算抢票:用户C1,C2,C3,各自抢杭州-上海的去不同目的地的票。
布隆过滤器BF过滤请求:
通过一定的hash算法把已买到的座位+站点映射到布隆过滤器,拿3号位来说,所有包含B,C,D站的3号位的买票请求,将被BF过滤掉。
list
双向链表 有序(放入顺序) 同时能实现栈、队列、数组等结构
分布式队列(或分布式数据结构):jvm重启或宕机,数组或队列中的数据会丢失,但如果使用redis,不会有这个问题。
ltrim 保留热数据
应用场景
- 列表 评论列表、关注列表、粉丝列表
-
hash
应用场景
商品详情页
- 数据聚合: 商品详情+产品详情+订单信息
set
无序:内部排序不可靠,rehash之后内部排序还会改变。
集合尽量少用,因为操作很慢。可以用多实例来解决,A实例用于热点数据存取,B实例用于分布式数据结构,C实例用于其他静态数据。取集合n个随机元素 SRandMember
SRANDMEMBER key n : 返回集合内随机n个元素, 如果n为负数,则可以返回重复元素(每个元素随机)。使用场景
数据结构实现:ziplist/skiplist
默认是ziplist,当满足以下条件:1. 元素个数比较多,2.比现一个比较大的元素 时,会转skiplist
应用场景
- 动态排行榜
- 评论列表 (基于点赞数、评论时间等维度排序)
- 需要对某个数据列表做不同维度的排序 怎么办? 特点单个数据很大,把数据维护在hash中,一个记录对应一个Key, 然后zset中存在数据对应的key+score而不是数据行+score,这样减少数据占用

若有收获,就点个赞吧
0 人点赞
