reids官网:http://redis.cn/ http://redis.io
缓存简介
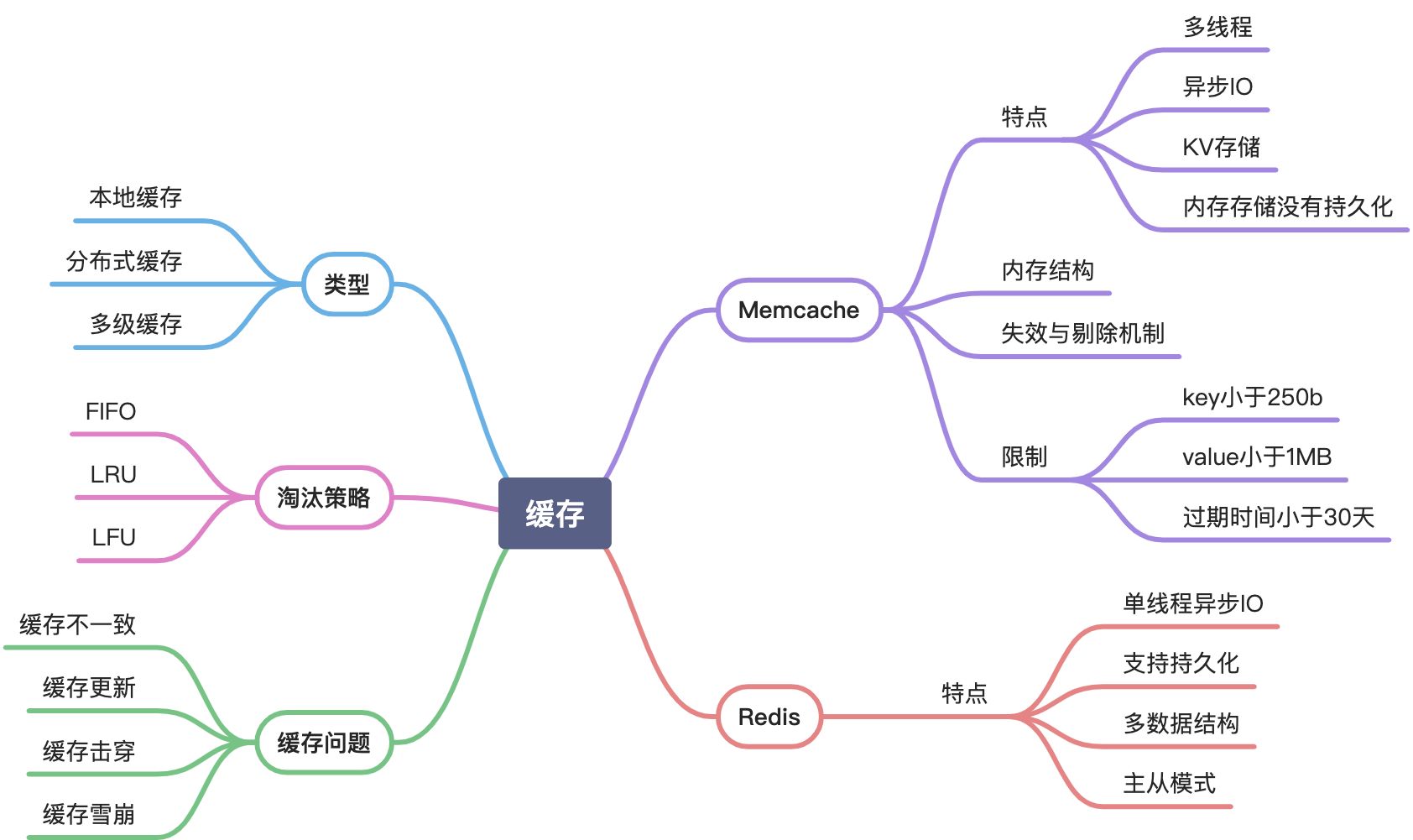
概述
? 为什么要有redis?
特点:内存存储、单线程、多种数据类型、带本地方法,计算向数据移动 、epoll模型
在互联量高并发、海量数据的场景下,关系型数据库往往成为性能瓶颈。从性能上来说,海量数据场景下,B+树索引的深度增加,还带来磁盘io次数的增加。
NoSQL应运而生。
? 为什么redis不做关系型的而要做成k-v结构的
redis存储是有时效性的,不能保证关系型数据库的 约束、范式、冗余。(如当多个Key存在依赖关系时,某个key失效,其他缓存也会伴随失效)
当然另外一个原因还是快
? redis都是单线程的吗?
是单线程,串行化。
redis6.0支持多线程了,但是只有io行为是多线程处理,但是io中读到的数据处理(工作线程)仍然是单线程的。
?redis 有哪些数据类型?
string list hash set zset,且每种数据结构都有自已的本地方法。
? memcache支持string以外的数据类型吗
- 数据类型, memcache的value只有string,所有其他类型数据都需要序列,无法使用memcache做数据计算,而redis支持更丰富的数据类型。
?连接池是线程池吗?连接池一定是多线程吗?
连接池不是线程池,两者没啥关系。
连接就是socket, 连接池就是一个List, 一个简单连接池不是必须依赖线程池的。像NIO就是单线程的。
?redis部署
多实例部署,则每个实例放在不同的redis服务器上。
线上redis单实例数据量一般不要超过10G,可以做业务拆分。这样数据恢复到内存是很快。
? Redis的IO性能来自于哪里?
redis使用epoll模型(如果操作系统没有epoll会降级为select,总之使用io多路复用模型)。
?Redis BGSAVE如何解决 已写数据被篡改?
copy on write 写时复制 SC-clone()一个线程出来,线程内对象引用指向还是开始BGSAVE那个时刻的。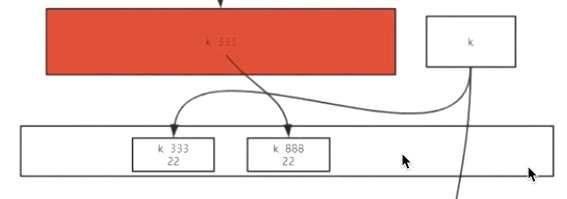
数据结构
- 串 sds
- hash
- list
- set
- zset
阿里云redis4.0
多线程性能增强
Redis性能增强型实例将Redis服务各阶段的任务进行分离,通过分工明确的多个线程并行处理各阶段任务,达到提高性能的目的。
- IO线程:负责请求读取、响应发送、命令解析等;
- Worker线程:负责命令处理、定时器事件等;
- 辅助线程:负责高可用探测、保活等。
图 1. Redis单线程模型
图 2. Redis多线程模型
IO线程读取用户的请求并进行解析,之后将解析结果以命令的形式放在队列中发送给Worker线程处理。Worker线程将命令处理完成后生成响应,通过另一条队列发送给IO线程。
Redis性能增强型实例最多支持4个IO线程并发运行。为了提高线程的并行度,IO线程和Worker线程之间采用无锁队列和管道进行数据交换。
数据结构模块集成
云数据库Redis企业版性能增强系列集成了多个自研的Redis模块,包括TairString、TairHash、TairGIS、TairBloom和TairDoc,从多方面扩展Redis的适用性,降低复杂场景下业务的开发难度,使您专注于业务创新。
- TairString 是一种带版本号的k-v string结构,可用于乐观锁等场景。
- TairGIS 是一种 R-Tree做索引,支持地理信息系统GIS(Geographic Information System)相关接口的数据结构。
- TairBloom 是一种可动态扩容的布隆过滤器。
- TairDoc是一种文档类型的数据结构,支持JSON标准,完全兼容ReJSON模块的命令。TairDoc数据以二进制树的方式存储,支持对JSON中子元素的快速访问。
混合存储型实例
云Redis企业版混合存储型实例整合了内存和磁盘二者的优势,在提供高速数据读写能力的同时满足了数据持久化的需求。
用磁盘存储全量数据,将热数据保存到内存中供应用快速读写。在保证常用数据访问性能不下降的基础上,Redis混合存储型实例能够大幅度降低用户成本,实现性能与成本的平衡,同时使单个Redis实例的数据量不再受内存大小的限制。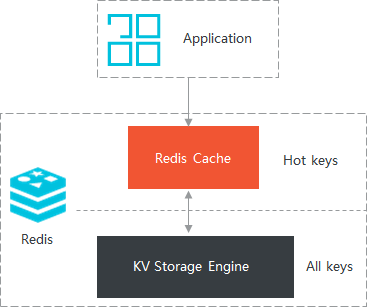
云Redis的高可用
实例架构
| 架构类型 | 说明 |
|---|---|
| Redis标准版-双副本 | 系统工作时主节点(Master)和副本(Replica)数据实时同步,主节点故障时系统自动秒级切换,备节点接管业务,全程自动且对业务无影响,主从架构保障系统服务具有高可用性。 |
| Redis集群版-双副本 | 集群(Cluster)实例采用分布式架构,每个数据分片都支持主从(master-replica)高可用,能够自动进行容灾切换和故障迁移。集群版提供多种规格,您可以根据业务压力的大小选择合适的规格,还可以随着业务的发展自由变配。集群版支持两种连接模式: - 代理模式是集群版的默认连接方式,可提供智能的连接管理,降低应用开发成本。 - 直连模式支持客户端绕过代理服务器直接访问后端数据分片,可降低网络开销和服务响应时间,适用于对Redis响应速度要求极高的业务。 |
| Redis读写分离版 | 与标准版-双副本架构类似,读写分离实例采用主从(Master-Replica)架构提供高可用,主节点挂载只读副本(Read Replica)实现数据复制,支持读性能线性扩展。 只读副本可以有效缓解热点key带来的性能问题,适合高读写比的业务场景。 读写分离实例有两种类型,即非集群版和集群版: - 非集群版读写分离实例支持一个只读副本、三个只读副本或五个只读副本三种版本。 - 集群版读写分离实例在每个分片下挂载一个只读副本,提供分片级别的自动读写分离能力,适合超大规模高读写比的业务场景。 |
参考资料
谈谈服务雪崩、降级与熔断
Redis 缓存和 MySQL 数据如何实现一致性?
记一次线上Redis缓存击穿
总结Redis缓存穿透、缓存击穿、缓存雪崩各是怎样的,解决思路及方案
高可用Redis服务架构分析与搭建
谈谈关于缓存穿透,缓存击穿,缓存雪崩,热点数据失效问题的解决方案
阿里云redis4.0新特性
redis为什么这么快
内置复制
redis详解-底层数据结构
redisAOF持久化详解

若有收获,就点个赞吧
0 人点赞
