背景
伴随项目迭代,最终都会走向分布式、微服务的架构,项目的业务垂直拆分更细化,分出的项目更多,各项目分工更明细,这有利于项目具体到人的维护,和更清晰的项目业务承担。但与此同时,在项目分布式架构演进中,渐渐暴露出调用连路过长的问题,从http接口前台,到dao层需要穿过好几层分布式服务,再加上业务之间交叉,项目之间又不可避免地来回调用,这最终造成接口性能差,甚至响应超时的严重问题谨待解决。
现存问题
循环调用
分批取
多次调用
一个用户线程内,多次dubbo invoke某接口
参数相同时,应该调用一次,保存结果到内存或缓存以便下次共享数据
参数不同,考虑使用参数数组,一次取
调用链路过长
高耦合 来回调
基础架构为了做到通用,内部耦合了过多的业务逻辑,比如获取商品某属性值,内部实现需要先过对商品对象的权限,再过商品字段的权限范围,最后取数。
明确各分布式项目的层级关系,不允许下层调上层
平级的应用层之间 也要避免来回调用,正确的做法是,要么提供过程,要么提供数据。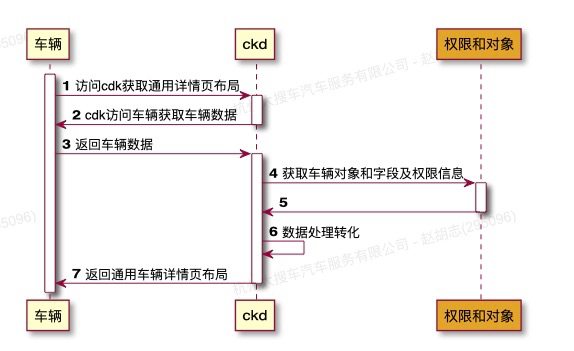
优化方案
按需定制,而不是相反
需要什么接口,要求基础服务有定制地提供,而不是基础服务提供什么我们用什么
有针对性优化,只对热点数据热点接口做优化
降低耦合 三层调用
 优化后
优化后

新接口新版本新实现
提供新版v2的平级接口给新版客户端使用(使用新版app的用户将调到优化后的接口)
绕开老接口旧实现
view层全新实现
service层如果老方法性能可观可复用可以直接用,如果老方法性能差全新实现,如果老方法性能可观但不可用需要造则复制重构
数据复用
思想:一次查询、重复利用。
复盘老接口时发现老接口喜欢用id作为参数 ,每次子过程都拿id再查一次数据。
于是采用分阶段的方式,做好数据共享和复用:
一阶段:数据准备
二阶段:数据处理
异步回调
两个可以并行进行的过程使用异步回调模式处理,
然后合并结果集,返回。
分布式缓存
一个用户对一个商品页的详情数据,在大多数情况下认为是常量,可以缓存的redis中
当商品变更、用户权限变更时,才会影响数据正确。因此只需要评估所有影响点找到影响接口,对其做缓存失效处理。这就保证缓存的准确性。

若有收获,就点个赞吧
0 人点赞
