一 性能分析与评估
指标
定位
查看应用数据
埋点
借助运营埋点,采集用户行为数据 流量
日志埋点,深度分析接口内部耗时操作
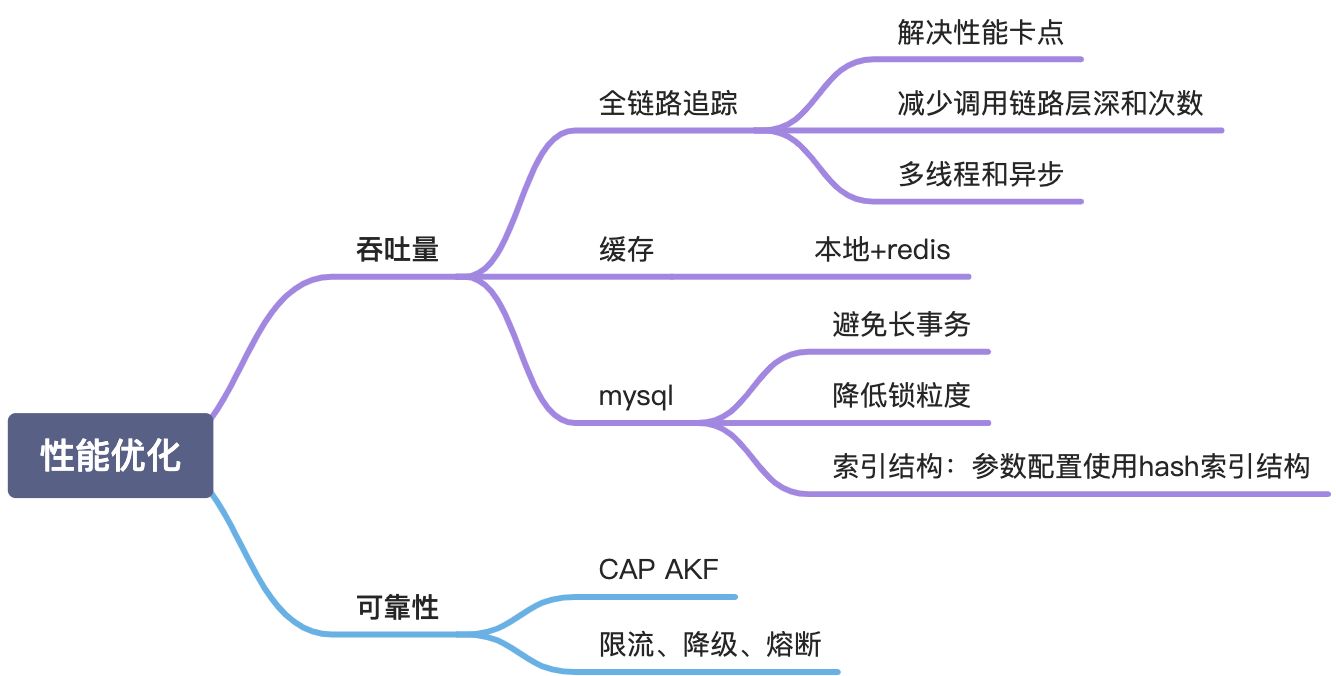
日志和链路
监控大盘,过滤500ms以上的http响应和200ms以上rpc和100ms以上sql
优化模式
系统设计原则
- 最小可用 经济
敏捷开发,实现最核心功能,快速接入,快速完成 避免过度设计
降低开发周期 分阶段上线,把更大的风险降到更小可控范围
- 复用
数据复用
代码复用
- 奥卡姆剃刀原则
非必要功能不要 非必要代码不写
性能恶化模式
- 长请求阻塞
单次请求时间过长
- 多次请求杠杆
每一次简单请求 撬起 下层更多的请求
- 重复缓存
性能优化模式
水平分割模式
一次请求总耗时=解析请求耗时 + ∑(获取数据耗时+处理数据耗时) + 组装返回结果耗时
大部分耗时长的服务主要时间都花在中间两个环节,即获取数据和处理数据环节。对于非计算密集性的系统,主要耗时都用在获取数据上面。获取数据主要有三个来源:本地缓存,远程缓存或者数据库,远程服务。三者之中,进行远程数据库访问或远程服务调用相对耗时较长,特别是对于需要进行多次远程调用的系统,串行调用所带来的累加效应会极大地延长单次请求响应时间,这就增大了系统进入长请求拥塞反模式的概率。
水平分割模式有两个关键优化点:减少Stage数量和降低每个Stage耗时。为了减少Stage数量,需要对一个请求中不同业务之间的依赖关系进行深入分析并进行解耦,将能够并行处理的业务尽可能地放在同一个Stage中,最终将流程分解成无法独立运行的多个Stage。降低单个Stage耗时一般有两种思路:1. 在Stage内部再尝试水平分割(即递归水平分割),2. 对于一些可以放在任意Stage中进行并行处理的流程,将其放在耗时最长的Stage内部进行并行处理,避免耗时较短的Stage被拉长。
水平分割模式不仅可以降低系统平均响应时间,而且可以降低TP95响应时间(这两者有时候相互矛盾,不可兼得)。通过降低平均响应时间和TP95响应时间,水平分割模式往往能够大幅度提高系统吞吐量以及高峰时期系统可用性,并大大降低系统进入长请求拥塞反模式的概率。
垂直分割
代码或者业务的垂直分割,对各个分布式业务结果合并
提高吞吐量
减少IO
- 读写转跨机为单机读写
复制冗余,将跨机查询转为本机查询,将多机操作转成单点操作
BASE 将跨机事务折分多个本机事务,然后通过中间件协调最终一致
计算向数据移动
计算过程下沉到各个下级节点,主节点负责计算结果的合并
减少编码 减少序列化
- 使用二进制字节流传输来替代 对象传输
- 使用Protobuf替代java序列化
- 不要使用BeanCopy 使用mapstrupt代替
异步
数据共享与复用
- 大对象创建复制、 大集合计算导致的性能问题
- 多级缓存 保证对象复用
数据层
1. 分库分表
2. 多库Join
- 增加冗余字段设计
- 向多库发n次查询
- 复制表到本地数据库
- 连接表 邻接表
- sql调优 解决慢查询
- 使用子查询优化分页查询
- 去掉不必要的子查询 子查询过多 创建临时表过多
提高可用性
C 一致性
基于saga的弱一致性
saga的性能损耗:单次serviceTask在4核8G机器上的RT消耗在微秒级别(约540vs)
重试
多次重试
轮询异常数据执行
- dubbo重试机制 和 重试策略
限流和降级
降级:流量高峰时 打开降级开关,关闭非核心业务
流量高峰时,把降级开关打开,原列表20条数据 改为显示5条,大数据分析人车匹配推荐在详情页关闭
限流:
拒绝服务:当qps远远高出预期时,Nginx设置过载保护,返回静态页面提示
超时处理
- 超时降级
- 重试和自动处理
- 读降级 多级缓存架构下,服务端缓存和db不可用时,使用前端缓存
- 写降级
蓝绿发布
全链路日志和监控
结果
快速响应异常
优化前故障后上下线操作需要研发人员改代码上线配合,平均故障处理时间(MTTR)达小时级。 包括问题定位、订正sql/订正脚本。
优化后,可靠性更高且,大部分故障可重试执行。
参考资料

若有收获,就点个赞吧
0 人点赞
