机器配置
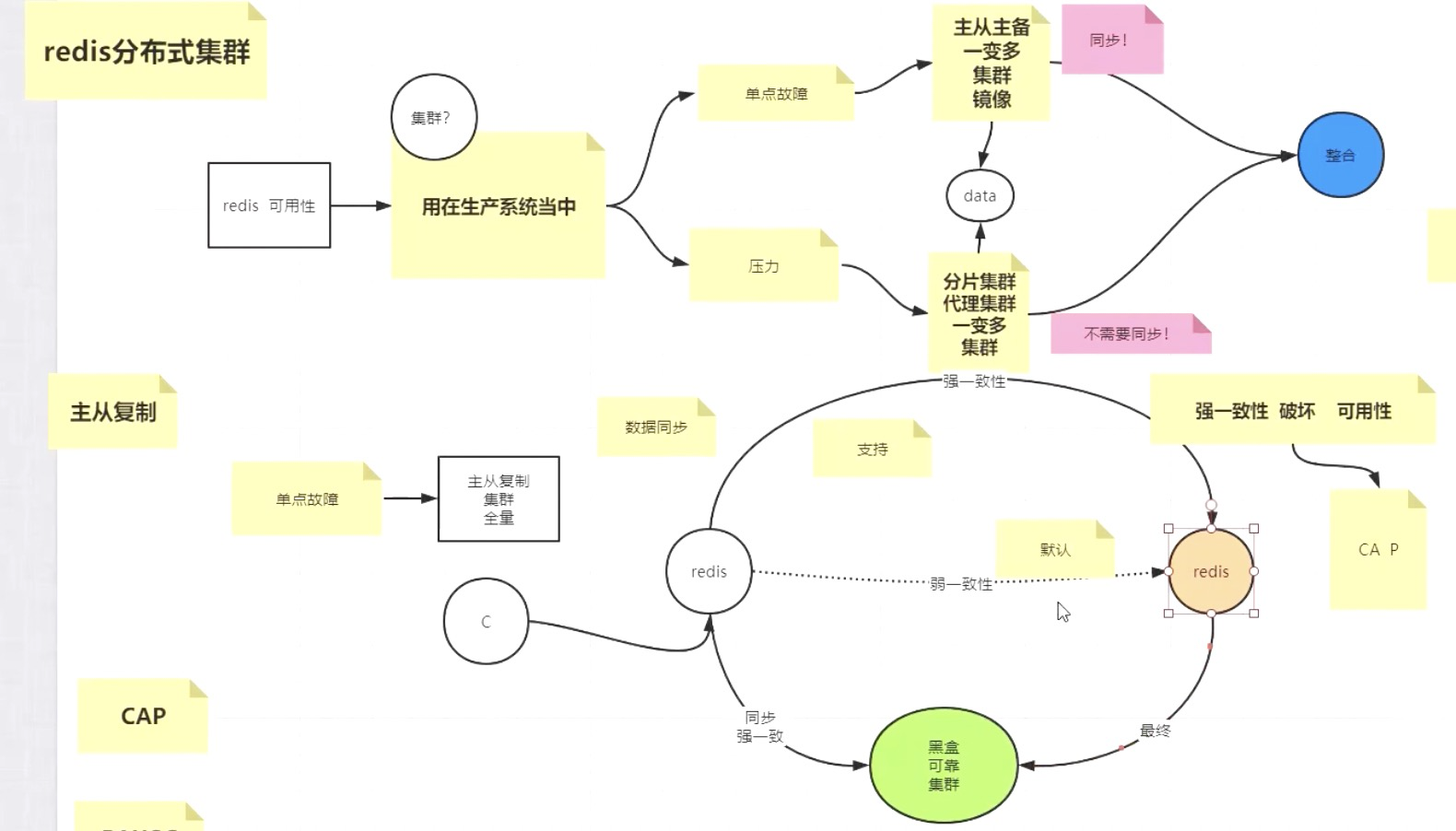
Redis
混合存储:内存占用超90%会将冷数据逐出存至硬盘
单机内存qps2万,
单机硬盘冷数据 随机访问1.5万,20%热5.4万,1%高热11.4万
阿里云集群双副本:
- 总内存: 64G或128G
- 8*2 8分片的主从又副本
- 吞吐量:qps=80万 每秒创建连接数=5万 最大连接数8万 带宽=384M/s
RDS
8核16G
最大连接数:4千 IOPS:8K
QPS:8万
TPS: 内存命中时4K, 磁盘IO时450
ECS
以4核16G机器为例:
单机Nginx的最大QPS=100K
单机tomcat最大QPS=50K (内部无业务代码实现)
1Nginx+4Tomcat=12万Qps
10万的qps需要2Nginx+8Tomcat
高可用部署
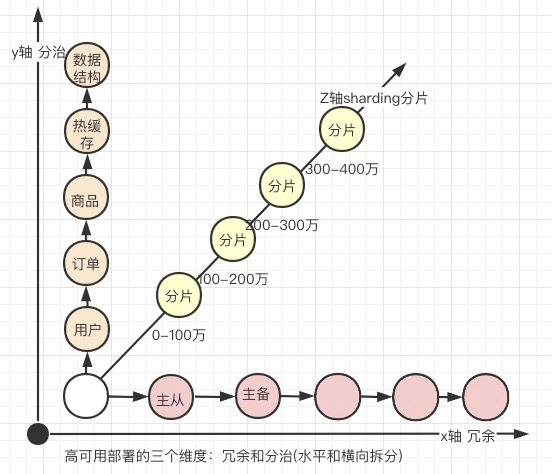
- 冗余 (备份)
- 分治 (多实例)
- 分片
单机部署的痛点及解决方案
单机单实例在高并发场景下面临的问题:
- 单点故障
宕机后服务不可用,造成雪崩
解决:主备集群/主从集群 ,数据镜像
- 压力
十年不挂,但cpu和内存率极高影响读写性能
解决:多实例/分片集群/代理集群
【图】海量并发下的高可用部署场景
冗余配置
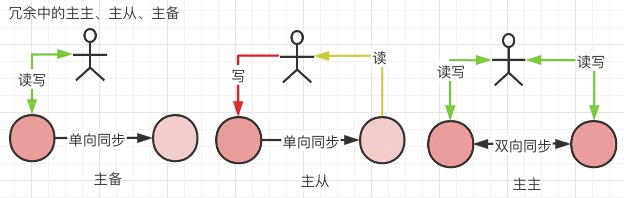
主备:副节点仅备份 主节点宕机切换使用
主从:读写分离,单向同步
主主:双向同步
主备/主从数据同步方案
- 强一致性(支持) 。
写操作时,单点写成功后,阻塞请求,同步数据到其他节点,同步完成后才返回结果给客户端。
存在问题:如果同步其他节点过程中,一个节点宕机,造成整个客户端请求的超时或不可用。(强一致性破坏可用性)
- 弱一致性 (默认)
写请求 放入队列 同步给各个节点。同步的过程中备节点挂了,数据不一致 备节点重启后拿到的数据不是最新的。
黑盒可靠集群(redis暂无实现,但hadoop的hdfs是这么干的):redis主节点与黑盒保持强一致同步,黑盒只保存未同步到其他节点的数据,然后黑盒负责向其他节点弱一致性同步,这样保证如果主节点宕机,主备切换后,数据不会丢失。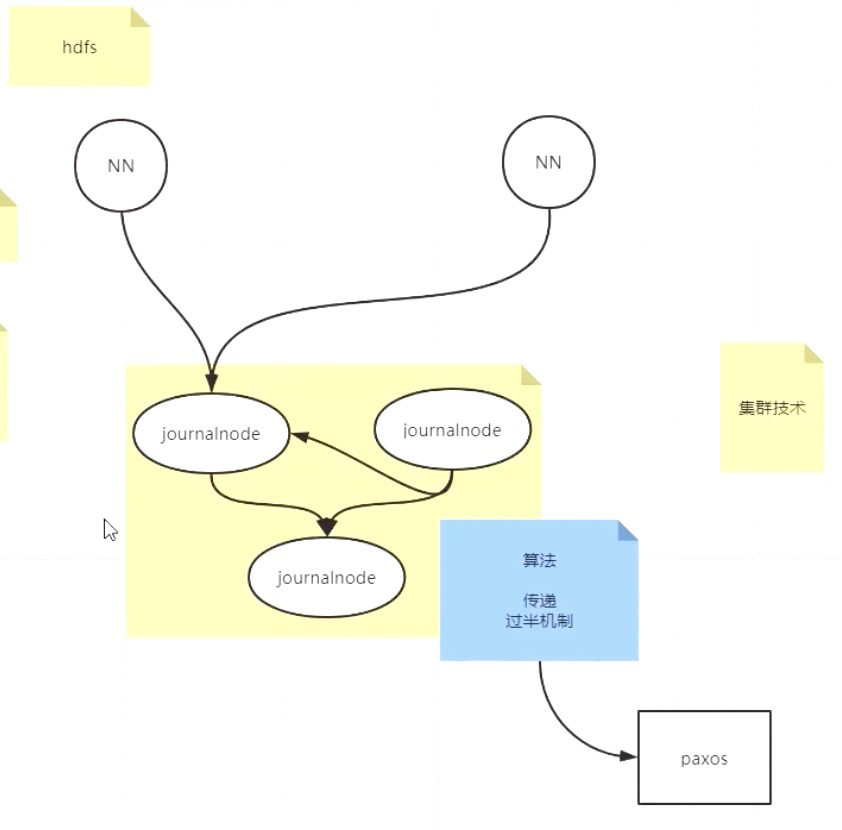
黑盒内部有n个journalnode, 集群且对外可靠。 主节点过半备份,则认为是指令的强一致性备份成功。
脑裂 如上图三个journalnode节点组成的集群,一个节点挂掉或不能和集群其他节点正常通信,该节点与其他节点的可视范围小于一半,会从集群中shutdown掉,不再对外界提供服务。
分治
分片集群和代理集群
分片集群
由开发自行实现分片策略,各个节点存储相应分片的数据段。
代理集群
代理节点去做负载均衡算法,把数据/请求通过一次的分片规则,分发不同的节点。
应用集群部署时使用的Nginx, redis的sential都相当于代理节点。
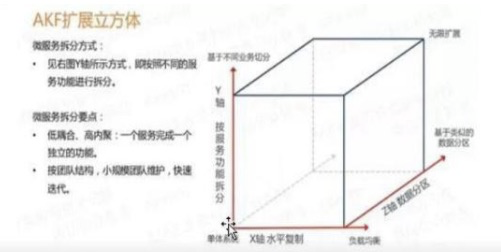
AKF
Redis Cluster 3.3以后的集群实现
16384个槽位。所有redis集群部署不应该多于16384个。当有分片键要插入集群节点时,该key对应的hash取模16384,得到虚拟槽位,然后把虚拟槽位 维护到一个map中,映射到物理节点上去。未来扩容时,只需要改map映射表,把部分虚拟槽对应的数据取出放到其他节点。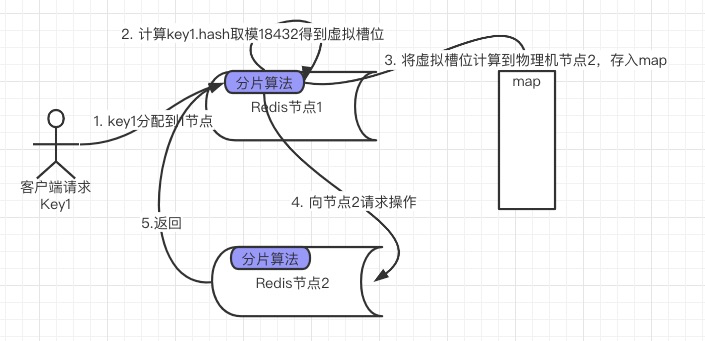

若有收获,就点个赞吧
0 人点赞
