- java程序员需要了解的底层知识第一课
- 硬件和操作系统的底层知识
- 操作系统之进程管理
- linux系统的内存映射
- 内核同步方法及用汇编启动内核
计算机组成原理
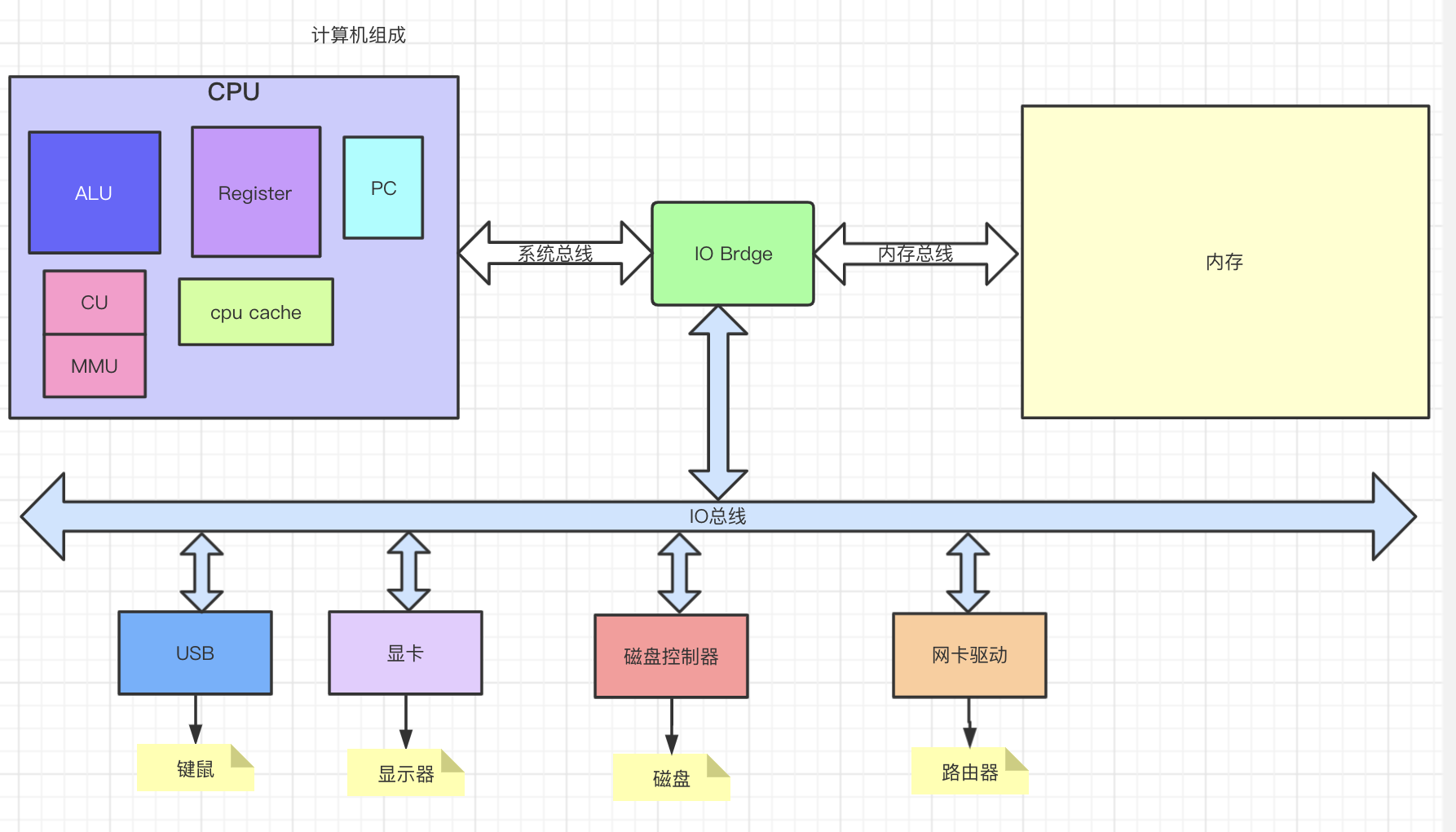
- pc program couter 程序计数器
- cu 控制单元,发送中断信号 cpu芯片的一部分
- alu 算术逻辑单元
- mmu 内存管理单元
- register 暂时存储cpu计算时用到的数据和指令,离cpu最近,存取最快,有几十上百个寄存器有不同的功能,64位cpu表示cpu一次可以从寄存器读64个bit
- cpu cache
CPU原理
计算要解决最根本的问题:把物理信号转化为数字信号。
震荡器(时钟发生器):产生- - - -带有中断的电信号
芯片:接收带有中断的电信号,将该物理电信号,转化成数字01信号
cpu的每个针脚就是用来接收(输入和输出)一个电信号的。
内存是存储电信号的,cpu是读取这些存储的电信号然后计算。
总线:一次性向内存读64个电信号,那么这次总线至少有64根线连接到内存去读信号。总线就是这些线的汇总。(所谓64位就是指cpu一次性可以读取64个数字,总线不一定64根,总线一次读128没关系cpu消费两次,总线一次读32,cpu等总线再去取一轮然后凑够64个数字再执行)。
cpu工作过程:
计算机通电 -> cpu读取内存数据(电信号输入)
-> 时钟发生器不断震荡断电 -> 推动cpu内部一步步执行(执行多少取决于指令需要的时钟周期)
-> 计算完成 -> 写回(电信号) -> 写给显卡输出
cpu频率:时钟发生器振荡频率
汇编语言
所以,计算机只认识 01001001,十分不易读, 而程序一定要人来设计,使用人类易于理解的语言。 20世纪50年代开始出现了符号式程序设计语言,这就是汇编语言。
比如
store 将数据存入内存 -> 对应一个机算机语言的二进制指令
add 加 -> 对应一个机算机语言的二进制指令
sub 减 -> 对应一个机算机语言的二进制指令
因此,编写汇编程序时,很可能是:1add2
缺点:
汇编语言会先通过虚拟机器将汇编指令转成计算进二进制指令,但汇编语言仍然是面向实际机器的语言,因为每一条如add指令,都与计算机实际执行的指令一一对应,因此这种语言仍然要求程序对计算机内部组成和指令系统十分熟悉。
高级程序语言
到了20世纪60年代,就出现了高级语言,如BASIC,C等。这类语言更接近人类语言,且具有较强的通用性。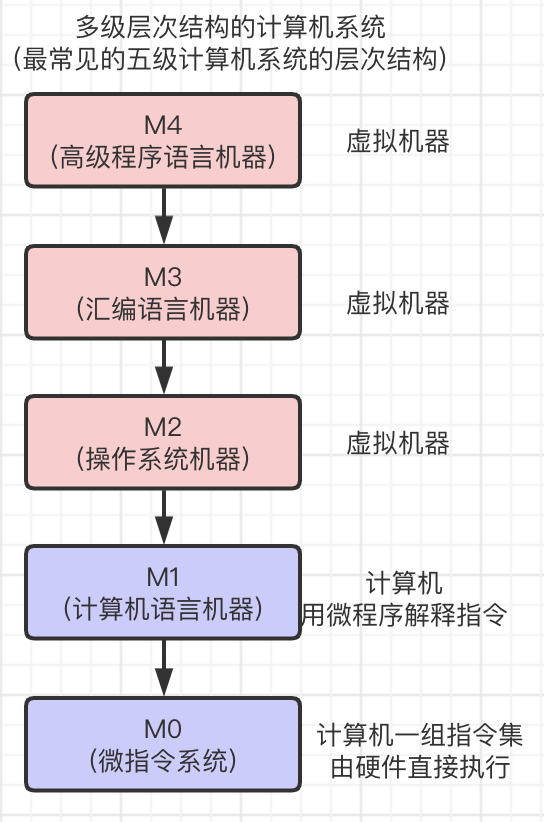
cpu执行过程
cpu乱序执行
cpu在执行读等的同时执行指令,是乱序的根源。指令重排序
乱不是目的,提高效率才是目的。
DCL单例为什么要加volatile?
public class T(){int m = 8;}T t = new T();new #2 // 分配内存dup // 复制栈引用invokespecial #3 init //实例化astore_1 // m赋值为8return
如上代码,jvm指令第8行和第9行可能会重排,使得赋值早于实例化。
当线程一正在实例化T,申请了空间,并且将M赋值为8,此时T处于半初始化状态,???????
因为实例化的时候可能会指令重排序,volatile防止指令重排。
防止乱序
硬件:intel的fence 和 锁总线
软件:jvm的hanppens-before / as-if-serial / 内存屏障
合并写
Write Combining Buffer,为了提高写效率,cpu在写入L1时,会同时用WC写入L2
一般是4个字节,由于ALU速度太快,所以在写入L1的同时,写入一个WC buffer,满了之后再直接更新到L2
NUMA
non Uniform Memory Access
ZGC-NUMA aware 分配内存会优先分配该线程所在cpu的最近内存
拓展
量子计算机
普通计算机是0或者1的bit组成的二进制指令完成的,而量子比特的一个bit位即可以1也可以是0,也就是传统计算机的01是静态的,也是0要么是1,而量子比特是动态的,有时候是0有时候是1.
于是当一个8位bit代表普通计算机二进制,只能表示2的8次方个数字,
而8位量子bit因其是动态的 可以表征更多数字 。这使得计算机的计算效率提升是指数级的。
超线程
超线程:一个ALU对应多个寄存器组. 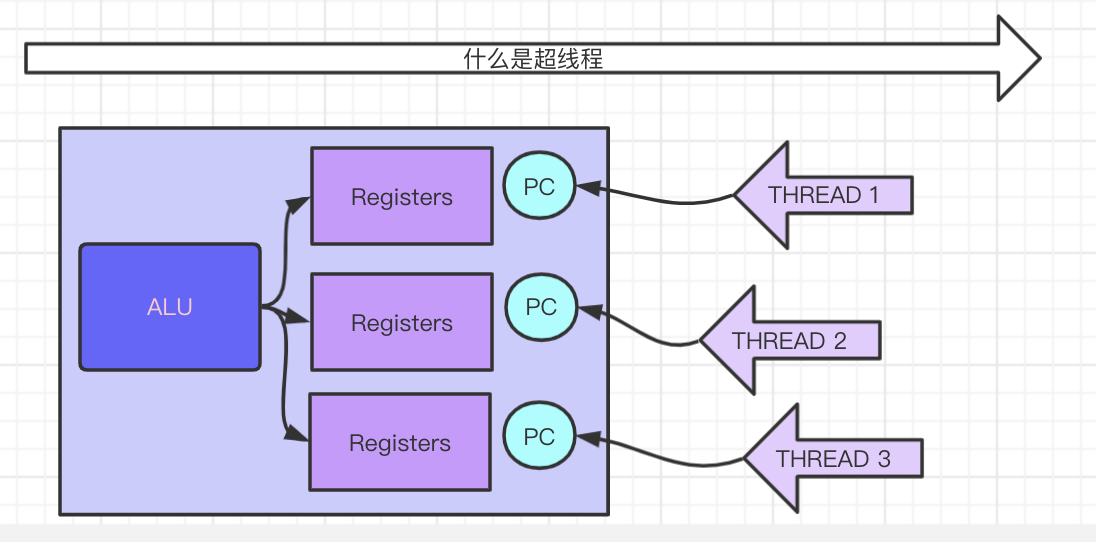
主要用来减少线程上下文切换,alu在响应时钟中断,切换线程时,只需要切换寄存器,而不需要切换线程上下文。
线程上下文切换意味者,线程中断,寄存器中的数据和指令要写回线程内存,然后寄存器装载下一个线程的数据和指令,在此期间alu在空闲状态,性能损耗可想而知
cpu从各个存储媒介取数用时
Registers : 小于1ns
L1 Cache : 1ns
L2 Cache : 3ns
L3 cache : 15ns
内存 : 80ns
缓存一致性
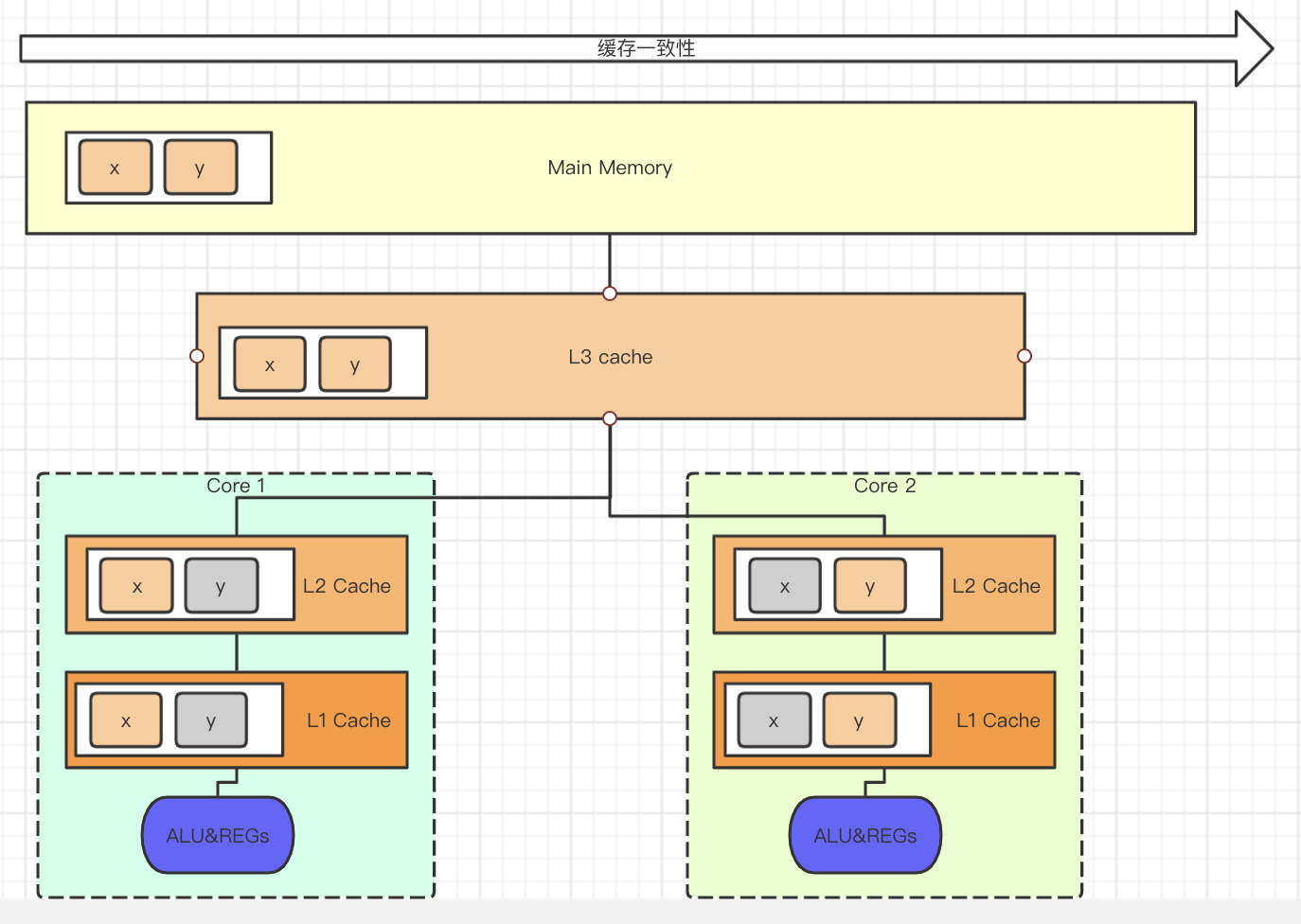
一个缓存行64字节。
cpu从内存读数据,按块读取,因此数据读取到cpu cache时,以缓存行形式存在。
如上图, core1 使用缓存行中的x, core2使用同一个缓存行中的y, 如果core1更新了x,则必须同步到其他核心。
同一个缓存行的一致性,由MESI一致性协议来保证,但有些情况下,缓存数据比较大,一个缓存行装不下,或者无法被缓存的数据,就需要锁总线来保证缓存一致性,当然锁总线的开支就高了。
另外,inter用的MESI,其他芯片商在实现一致性时也用到其他协议如,MSI,MOSI Synapse Firefly Dragon.
inter cpu的cache line 一般64个字节,缓存行越大,局部执行效率高,但读取时间慢。
既然有MESI和锁总线来保证缓存一致性了,为什么还需要volatile来保证可见性?
仅保证了可见性,没保证有序性,为防止指令重排。
伪共享:如上图,xy在一个缓存行,本意是为了实现数据共享,但实际上为了保证一致性,却触发缓存行同步事件,这种不必要的数据共就是伪共享。
缓存行对齐 一种编程方式,对于特别敏感的数字 ,会存在线程高竞争的访问,为了保证不发生伪共享,可以使用缓存行对齐的编程方式。
disruptor: 7个long+一个cusor+7个long, 这样curor前面的7个Long和后面7个long必须不可能位于相同的缓存行,两个7之间不会发生mesi一致性同步,而每个7内部,又可以实现数据共享。
jdk7 中,很多地方用long padding来提高效率
jdk8,加入了@Contendted注解,@Contended在类级别上的注释,可以进行缓存行填充。这样,多线程情况下的减少伪共享冲突问题。
IO
寄存器 64位一级缓存L1 4×64KB二级缓存L2 4×256KB三级缓存L3 8MB
各种存储媒介读取耗时
L1 cache reference 0.5 nsBranch mispredict 5 nsL2 cache reference 7 nsMutex lock/unlock 100 ns //互斥锁加解锁Main memory reference 100 nsCompress 1K bytes with Zippy 10,000 nsSend 2K bytes over 1 Gbps network 20,000 nsRead 1 MB sequentially from memory 250,000 nsRound trip within same datacenter 500,000 nsDisk seek 10,000,000 nsRead 1 MB sequentially from network 10,000,000 nsRead 1 MB sequentially from disk 30,000,000 nsSend packet CA->Netherlands->CA 150,000,000 ns
硬盘
寻址时间:ms
带宽、吞吐:百兆/s (pci-e nvme 的固态硬盘可达G/s)
内存
局部性原理和磁盘预读
局部性原理
时间局部性
如果一个数据正在被访问,近期它还会被访问到
空间局部性
在最近的将来将用到的数据很可能与正在用读的数据的空间地址相临近 -> (按块读)
顺序局部性
除转移类指令外,大部分指令是顺序执行的,顺序执行和非顺序执行的比例是5:1,此外对大型数组的访问也是顺序的。<br />指令的顺序执行和数组连续存放是产生顺序局部性的原因
磁盘预读原理
内存读约100ns, 而磁盘寻址10ms, 内存读速度比磁盘读快的多,但内存容量远小于磁盘,而cpu的处理速度而远大于内存和磁盘io.
内存读取
内存是一系列的存储单元组成的,每个存储单元存储固定大小的数据,且有一个唯一地址。当需要内存读时,将地址信号放到地址总线上传给内存,内存解析信号并定位存储单元,然后把该存储单元上的数据放到数据总线上回传。
写内存时,系统将要写入的数据和单元地址分别放到数据总线和地址总线上,内存读取两个总线的内容,做相应的操作。
内存存取效率和次数有关,先读a和后读a不会影响效率
磁盘读取
磁盘IO涉及机械操作。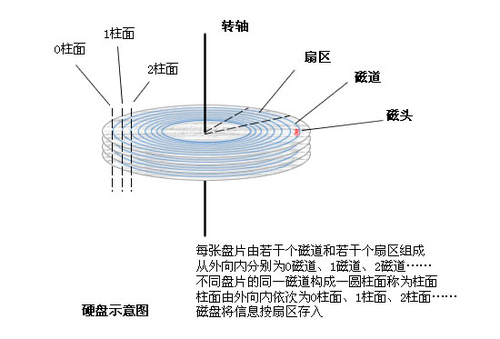
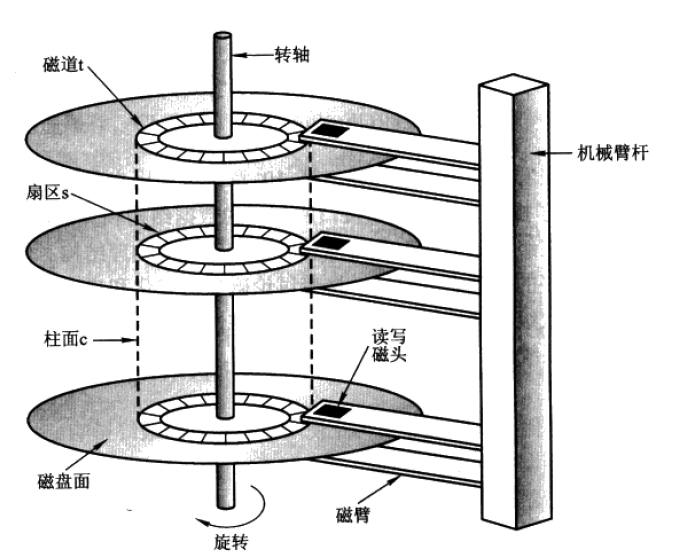
磁盘寻址过程
磁道和扇区。扇区是磁盘存储的最小物理单元(每个扇区512b)。
磁臂前后振动 来读取不同的磁道。磁片转到可以读到不同扇区的数据。
磁盘读时:
寻址:系统将数据的逻辑地址传递给磁盘,磁盘的控制电路会解析出物理地址(磁道2-扇区a)
寻址时间包括寻道时间和旋转时间(从磁道内找到对应扇区),这就是一个完整的寻址过程,至少需要10ms.
按页读取(按块预读)
为了减少io操作,计算机一般采取预读的方式,预读的长度为一页的整数倍。页是计算机管理存储器的逻辑块,硬件和OS往往将主存和磁盘分割成连续大小的相等的块,每个块称为一页(通常为4k),主存和硬盘以页为单位交换数据。当程序要读取的数据不存在主存中时,会触发一个缺页异常,此时系统会向磁盘发出读磁盘信号,然后磁盘向后连接读1页或多页装载到内存,然后异常返回,程序继续运行。
一页 = 8扇区 = 8*512b = 4kb
每次内存读的最小单元是一页4kb,而磁盘预读能通常是4k的整数倍。根据时间局部性和空间局部性,程序运行期间所需要的数据通常都比较集中、连续。由于磁盘顺序读的效率很高(不需要寻址),所以即使cpu只取一个字节,内存读也会读一页。
按块读取
程序局部性原理,可以提高效率,充分发挥总线、cpu针脚等一次性读取更多数据的能力。
内存和磁盘有分散连接(单独的连线,区别于总线),内存可以直接向磁盘发送指令把数据块加载到内存,而不需要经过cpu.
OS 操作系统
操作系统就是配置在计算机上的第一层软件,主要作用是管理好计算机设备,提高硬件的利用率和系统的吞吐量;同时对用户和应用提供简单接口,便于使用。
内核分类
- 宏内核
宏内核是cpu调度、文件系统、应用管理、内存管理、进程管理、中断处理和设备驱动都在一块内存。
目前的pc phone都是宏内核
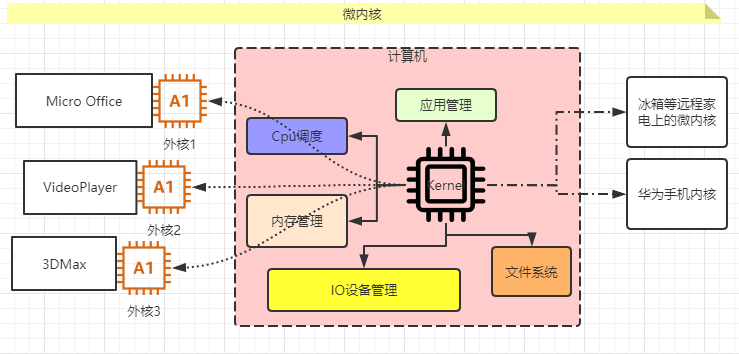
- 微内核 弹性部署 5G IoT
微内核:相反,kernel和cpu管理、内存调度等等各自独立,kernel负责集中调度其他内核。
- 外核 - 科研阶段
外核则更像是为某些应用或外部服务定制的核(暂不存在),目前还不处于实验室阶段。这样的定制化带来更多性能上的收获,比如对webserver专门开发的核心可以定制session级别的内存管理和gc策略。
阿里的多租户 request-based gc jvm
- vmm - visul memery machine 虚拟机
用户态与内核态
cpu分不同的指令级别
linux内核跑在ring 0级,用户程序跑在ring3 ,对于系统的关键访问,需要kernel的同意(系统调用),保证系统健壮性内核执行的操作。
进程的内核态0 和 用户态3

若有收获,就点个赞吧
0 人点赞
