1. 背景
2. 解决问题
3. 分表方案
3.1 技术选型
3.1.1 中间件选型
| 项目 | Sharding-jdbc | MyCat | zdal |
|---|---|---|---|
| 事务 | 自带弱xa,最大努力送达型柔性事务base | 自带弱xa | 自带弱xa 最大努力送达型柔性事务base |
| 分库分表 | 不支持单库分表 | ||
| 开发成本 | 代码侵入大 开发成本高 |
开发成本小 代码侵入小 |
开发成本不算高 配置明确 |
| 运维成本 | 低 | 高,需独立部署中间件 | 低 |
| 监控 | 无 | 有 | |
| 社区活跃底 | 不少公司开始在新项目使用 | 很高,很多公司已经在用 | 低 |
| 限制 | 部分jdbc方法不支持 sql语句受限 |
sql语句受限制 | |
| 配置难度 | 一般 | 复杂 | 比较简单 |
总结:sharding-jdbc增量分片和增量迁移数据效果更佳,Mycat比较适合大数据工作。
sharding是jdbc proxy, mycat是db proxy
3.1.2 分库分表策略
分库策略:
分表策略
分片方案:
- hash取模方案
优点:数据均匀分布
缺点:扩展要所有数据迁移
- range范围
优点:扩展不需要迁移
缺点:数据分布严重不均
- 一致性hash
优点:扩展时迁移较少数据
缺点:数据分布不是非常均匀
组合(分治法),如21组合
按range分组,0-500万分第一组,超出500万分第二级,此后第一组不需要迁移。每组内部hash取模离散数据。
分式主键 :
uuid和雪花算法
雪花算法优点:在假定集群机器时间同步的情况下可保证分布式id有序性
雪花算法缺点:严重依赖时间,如果时钟回拔,可能产生重复id. 当时钟回拔时,对序列化的初始值设置步长,时钟回拔,步长加1w。
分片键 :
合适的分片键应该在具体的业务场景下 查更少的表。
3.2 分表
分几张表?
以当前数据规模和预测三年后最大数据规模 两个参考值分表,使得在最小分片数的单表最大数据量一般不超过500万。
3.3 弹性伸缩
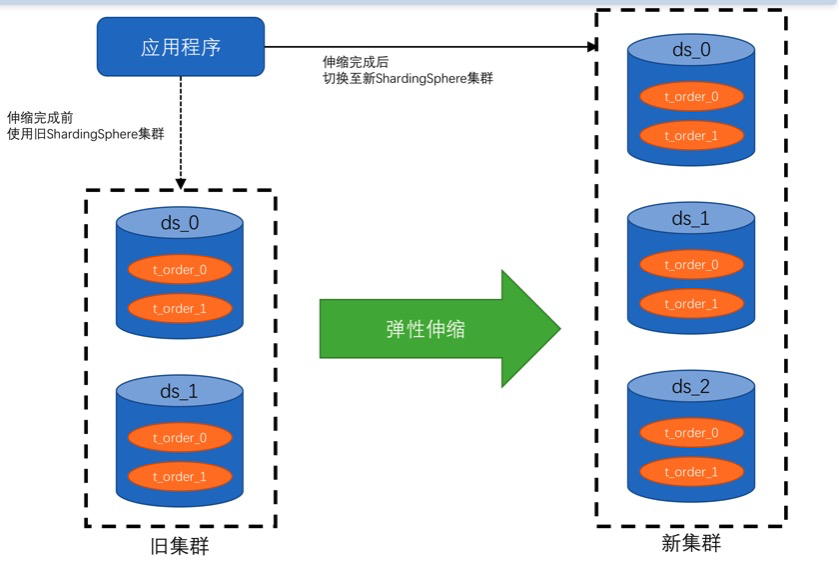
4阶段弹性伸缩工作流
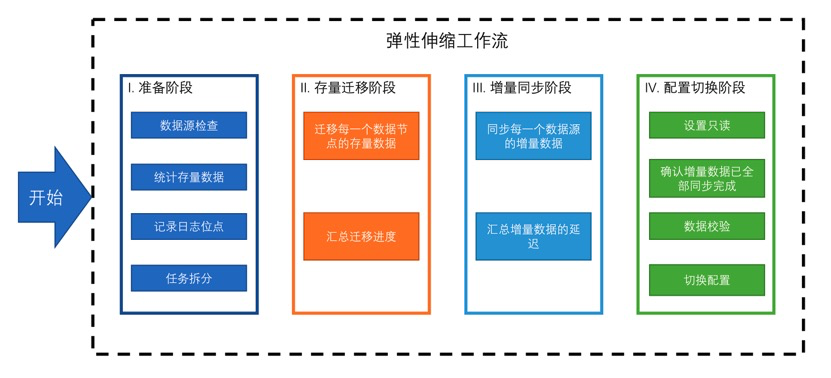
也就是说未来对分片扩展,是一定会做存量迁移的。
3.4 数据迁移方案
3.2.0 停机迁移
第一步,上线前在预发环境并行迁移 将某个时间点的数据全部迁移到新表
第二步,停机订正 上线。对第一步开始迁移到上线期间的变更数据,重迁到新表,校正数据后上线。
- 数据量大 一阶段迁移时间过长 可以分批订正,上线前一小时再做一次订正,然后,上线停机的时间就会更短。
3.2.1 只写新表 被动迁移和被动迁移
被动迁移
每次有新数据变更表逻辑表时,触发该数据所在分片迁移单元的立即迁移。
~~主动迁移 ~~
满足特定条件 编写特定程序自动从老表取数迁到新表。每天晚上12点以后,高负载主动迁移;白天单线程控制流量迁移,预计1-2周内,存量数据全量迁完。
需要解决并发问题:先数据变更后,后老数据迁移,新写入的变更丢失。
3.2.2 双写
第一步,修改系统中写库代码,同时写入到老库和新的分库分表。
第二步,编写一个后台迁移工具,从老的库里读数据,写入到新库中去
第三步,迁移完成之后,去比较一下新旧库表的数据,如果一模一样,则迁移完成,否则继续执行迁移。
第四步,新旧库表数据无差异之后,将代码中写入旧的数据库代码删掉,只写新库。
存量迁移阶段的数据变更,双写到老表和新表。于是不管何时,老表和新表的数据都是最新的。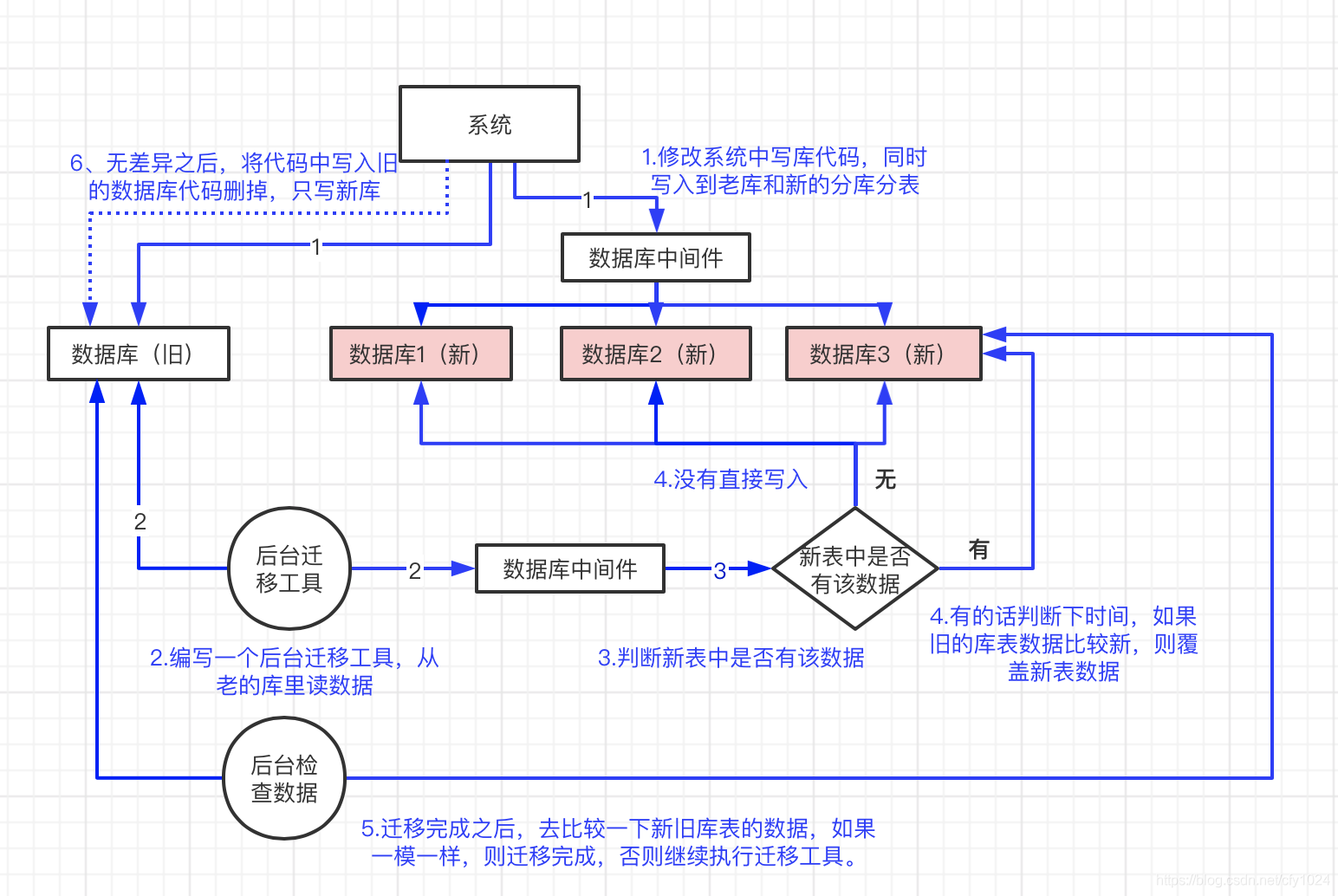
双写 是 主动+被动?
主要看迁移单元。以car_id为迁移单位,保证单车照片迁移的原子时,适宜使用主动+被动迁移。以店铺为单位,适合双写。
3.5 监控
关注迁移进度
- 关注店铺数
- 旧表停止新增后的店铺总数
2. 已成功迁移的店铺总数
3. 迁移发生失败的店铺数
- 关注活跃总数
- 旧表停止新增后的 活跃数据总量
2. 新表迁移数据总量
当迁移成功总店铺数 = 旧表停止新增后的店铺总数 并且 旧表活跃数据总数=新表已迁移数据 时表示迁移成功完成。
关注性能
- 接口rt
- 迁移过程对 jdbc性能稳定的影响
3.6 迁移成功后置处理
所有迁移成功后
- 清除redis中用于迁移过程的数据
- 制定旧表清理方案 (待定)
- 下线 主动迁移 和 渐进式迁移代码
3.7 分布式事务支持
暂不需要

若有收获,就点个赞吧
0 人点赞
