mysql主从复制原理
0、为什么需要主从复制?
1、在业务复杂的系统中,有这么一个情景,有一句sql语句需要锁表,导致暂时不能使用读的服务,那么就很影响运行中的业务,使用主从复制,让主库负责写,从库负责读,这样,即使主库出现了锁表的情景,通过读从库也可以保证业务的正常运作。
2、做数据的热备
3、架构的扩展。业务量越来越大,I/O访问频率过高,单机无法满足,此时做多库的存储,降低磁盘I/O访问的频率,提高单个机器的I/O性能。
1、什么是mysql的主从复制?
MySQL 主从复制是指数据可以从一个MySQL数据库服务器主节点复制到一个或多个从节点。MySQL 默认采用异步复制方式,这样从节点不用一直访问主服务器来更新自己的数据,数据的更新可以在远程连接上进行,从节点可以复制主数据库中的所有数据库或者特定的数据库,或者特定的表。
2、mysql复制原理
原理:
(1)master服务器将数据的改变记录二进制binlog日志,当master上的数据发生改变时,则将其改变写入二进制日志中;
(2)slave服务器会在一定时间间隔内对master二进制日志进行探测其是否发生改变,如果发生改变,则开始一个I/OThread请求master二进制事件
(3)同时主节点为每个I/O线程启动一个dump线程,用于向其发送二进制事件,并保存至从节点本地的中继日志中,从节点将启动SQL线程从中继日志中读取二进制日志,在本地重放,使得其数据和主节点的保持一致,最后I/OThread和SQLThread将进入睡眠状态,等待下一次被唤醒。
也就是说:
- 从库会生成两个线程,一个I/O线程,一个SQL线程;
- I/O线程会去请求主库的binlog,并将得到的binlog写到本地的relay-log(中继日志)文件中;
- 主库会生成一个log dump线程,用来给从库I/O线程传binlog;
- SQL线程,会读取relay log文件中的日志,并解析成sql语句逐一执行;
注意:
1–master将操作语句记录到binlog日志中,然后授予slave远程连接的权限(master一定要开启binlog二进制日志功能;通常为了数据安全考虑,slave也开启binlog功能)。 2–slave开启两个线程:IO线程和SQL线程。其中:IO线程负责读取master的binlog内容到中继日志relay log里;SQL线程负责从relay log日志里读出binlog内容,并更新到slave的数据库里,这样就能保证slave数据和master数据保持一致了。 3–Mysql复制至少需要两个Mysql的服务,当然Mysql服务可以分布在不同的服务器上,也可以在一台服务器上启动多个服务。 4–Mysql复制最好确保master和slave服务器上的Mysql版本相同(如果不能满足版本一致,那么要保证master主节点的版本低于slave从节点的版本) 5–master和slave两节点间时间需同步
具体步骤:
1、从库通过手工执行change master to 语句连接主库,提供了连接的用户一切条件(user 、password、port、ip),并且让从库知道,二进制日志的起点位置(file名 position 号); start slave
2、从库的IO线程和主库的dump线程建立连接。
3、从库根据change master to 语句提供的file名和position号,IO线程向主库发起binlog的请求。
4、主库dump线程根据从库的请求,将本地binlog以events的方式发给从库IO线程。
5、从库IO线程接收binlog events,并存放到本地relay-log中,传送过来的信息,会记录到master.info中
6、从库SQL线程应用relay-log,并且把应用过的记录到relay-log.info中,默认情况下,已经应用过的relay 会自动被清理purge3、mysql主从形式
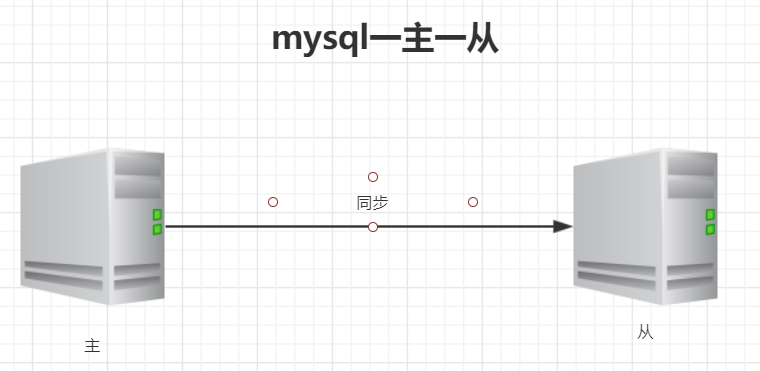
(一)一主一从
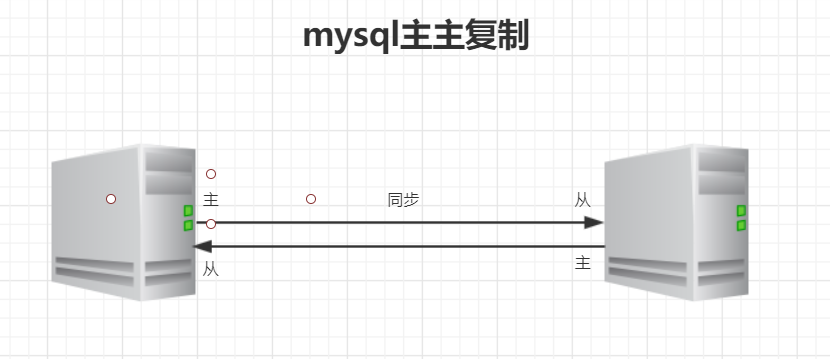
(二)主主复制
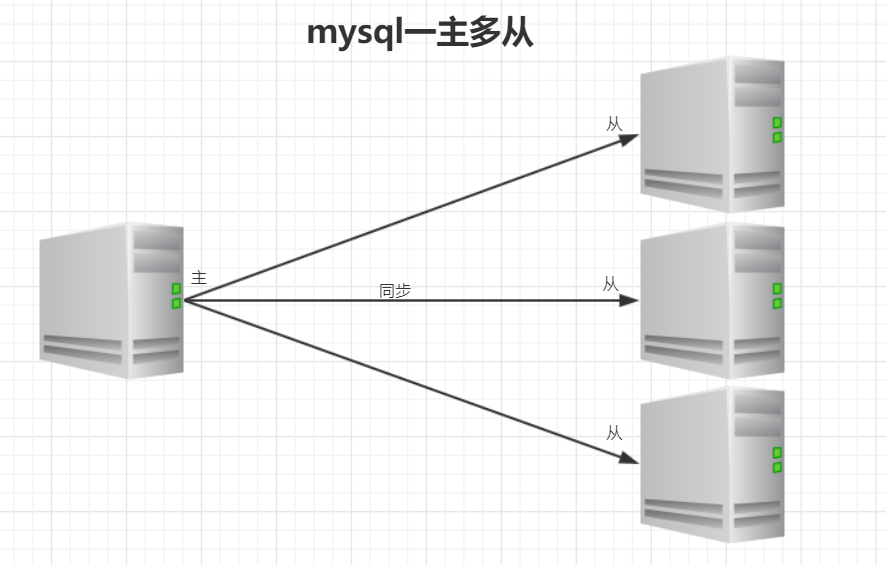
(三)一主多从
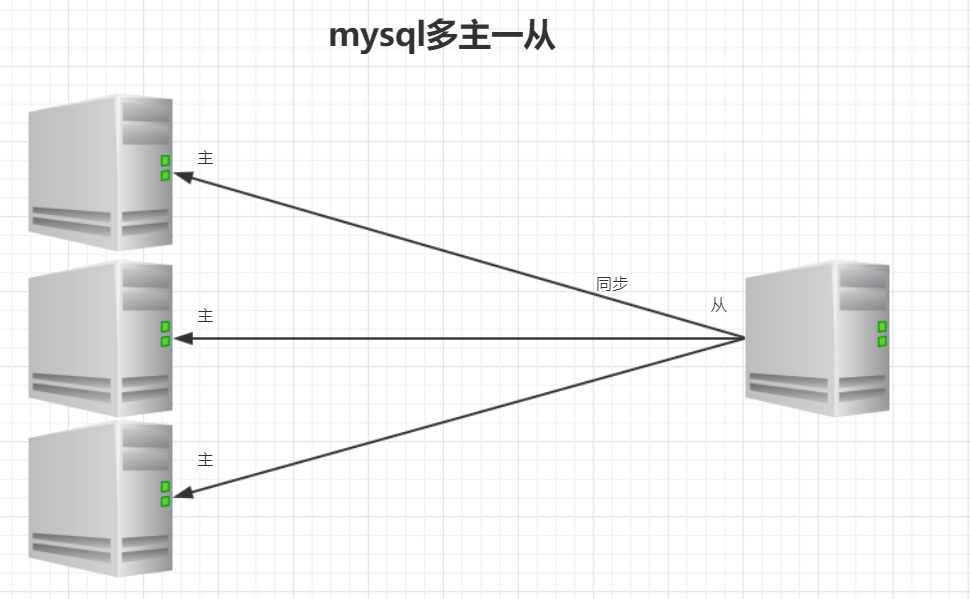
(四)多主一从
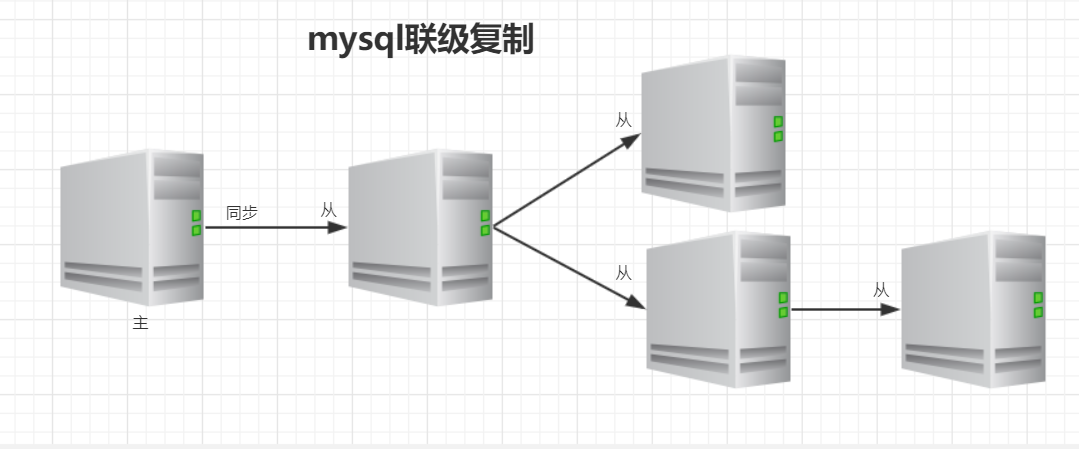
(五)联级复制
4、mysql主从同步延时分析
mysql的主从复制都是单线程的操作,主库对所有DDL和DML产生的日志写进binlog,由于binlog是顺序写,所以效率很高,slave的sql thread线程将主库的DDL和DML操作事件在slave中重放。DML和DDL的IO操作是随机的,不是顺序,所以成本要高很多,另一方面,由于sql thread也是单线程的,当主库的并发较高时,产生的DML数量超过slave的SQL thread所能处理的速度,或者当slave中有大型query语句产生了锁等待,那么延时就产生了。
解决方案:
1.业务的持久化层的实现采用分库架构,mysql服务可平行扩展,分散压力。
2.单个库读写分离,一主多从,主写从读,分散压力。这样从库压力比主库高,保护主库。
3.服务的基础架构在业务和mysql之间加入memcache或者redis的cache层。降低mysql的读压力。
4.不同业务的mysql物理上放在不同机器,分散压力。
5.使用比主库更好的硬件设备作为slave,mysql压力小,延迟自然会变小。
6.使用更加强劲的硬件设备
mysql5.7之后使用MTS并行复制技术,永久解决复制延时问题——自学
**mysql读写分离
1、读写分离的介绍
MySQL读写分离基本原理是让master数据库处理写操作,slave数据库处理读操作。master将写操作的变更同步到各个slave节点。
MySQL读写分离能提高系统性能的原因在于:
1、物理服务器增加,机器处理能力提升。拿硬件换性能。
2、主从只负责各自的读和写,极大程度缓解X锁和S锁争用。
3、slave可以配置myiasm引擎,提升查询性能以及节约系统开销。
4、master直接写是并发的,slave通过主库发送来的binlog恢复数据是异步。
5、slave可以单独设置一些参数来提升其读的性能。
6、增加冗余,提高可用性。
mysql的命令行会出现无法连接的情况,所以建议使用客户端
mysql -uroot -p123 -h192.168.85.14 -P 4040
使用amoeba实现mysql读写分离
1、什么是amoeba?
Amoeba(变形虫)项目,专注 分布式数据库 proxy 开发。座落与Client、DB Server(s)之间。对客户端透明。具有负载均衡、高可用性、sql过滤、读写分离、可路由相关的query到目标数据库、可并发请求多台数据库合并结果。
主要解决:
• 降低 数据切分带来的复杂多数据库结构
• 提供切分规则并降低 数据切分规则 给应用带来的影响
• 降低db 与客户端的连接数
• 读写分离
2、为什么要用Amoeba
目前要实现mysql的主从读写分离,主要有以下几种方案:
1、 通过程序实现,网上很多现成的代码,比较复杂,如果添加从服务器要更改多台服务器的代码。
2、 通过mysql-proxy来实现,由于mysql-proxy的主从读写分离是通过lua脚本来实现,目前lua的脚本的开发跟不上节奏,而写没有完美的现成的脚本,因此导致用于生产环境的话风险比较大,据网上很多人说mysql-proxy的性能不高。
3、 自己开发接口实现,这种方案门槛高,开发成本高,不是一般的小公司能承担得起。
4、 利用阿里巴巴的开源项目Amoeba来实现,具有负载均衡、高可用性、sql过滤、读写分离、可路由相关的query到目标数据库,并且安装配置非常简单。国产的开源软件,应该支持,目前正在使用,不发表太多结论,一切等测试完再发表结论吧,哈哈!

若有收获,就点个赞吧
0 人点赞
