背景
互联网应用发展史
单一应用架构
ORM减少crud工作量是关键
垂直应用架构
一个大的应用垂直拆分成几个不相干的应用
分布式服务架构
应用之间允许有交互
提高业务复用及整合的分布式服务框架RPC是关键
流动计算架构
提高机器利用率的资源调度和治理中心(SOA)是关键
需求
- 注册中心统一管理服务
早期可能使用RMI和hessian暴露和引用远程服务,但服务越来越多时,服务URL配置管理变得非常困难。这时候需要一个注册中心来统一管理。
- 应用间的依赖关系图
应用依赖关系和启动顺序
- 配置中心
- 注册中心
- zk
- redis
- multicast
- 集群中心
- 负载均衡
- 容错
- 路由
- 远程通信
- http
- netty
- mina
- p2p
- zk
- 远程调用
- http
- hession
- rmi
- memcahce/redis
- 监控
- 过滤
- 序列化
架构
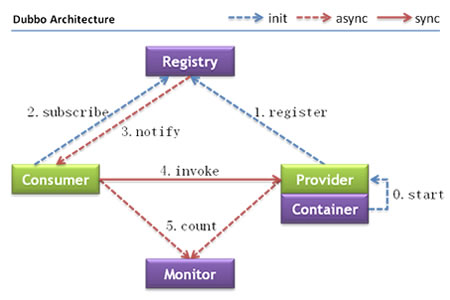
其中,monitor是监控中心,container是服务运行容器
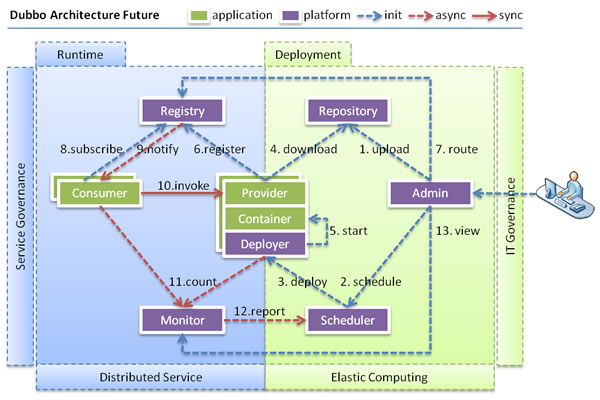
这是未来dubbo可能的架构
deployer 是自动化部署服务 相关于jekins
Scheduler 是调度中心基于访问压力自动增减服务提供者
admin dubbo统一管理控制台
Repository 相当于git代码仓库
SPI可扩展机制
dubbospi使得需要对dubbo做扩展时,只需要基于扩展点实现定制需求不需要改dubbo源码.
DubboSPI和JavaSPI的区别
- 延迟加载 不需要一次性把所有扩展点实现类全部加载进来
- 实现了SPI的ioc和aop的机制
- dubbospi支持缓存 SPI的name和value缓存在concurrentHashMap里
- dubbospi支持默认值 如@SPI(“dubbo”) 默认使用dubbo协议
服务导出和引入
集群容错
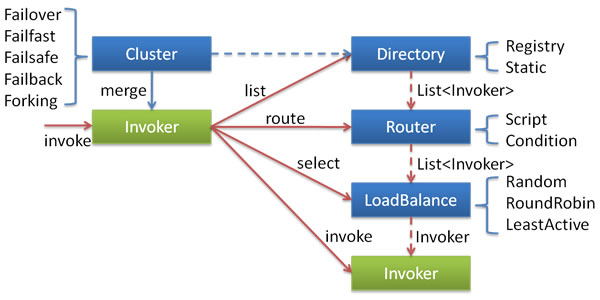
dubbo提供多种容错方案,默认为failover,自动重试
Failover Cluster
失败自动重试其它服务,通常etgfyfn操作。但重试会带来更长延迟。
Failfast Cluster
Failsafe Cluster
Failback Cluster
失败自动恢复,后台记录失败请求,定时 重发。用于消息通知操作。
Forking Cluster
同时调用多台服务器,只要有一个成功就返回,用于实时性要求比较高的读操作,但需要浪费更多服务资源。forks=2来设置最大并行数。
Broadcast Cluster
广播逐个调用所有提供者,任意一台报错就报错。
负载均衡策略
Random
按配置权重随机
调用量越大分布越均匀,而且按概率使用权重后也比较均匀有利于动态调整提供者权重。
RoundRobin
轮询 按权重设置轮询比率
慢积累:当轮询到第二台时,第二台响应慢但没挂,大多请求都卡在第二台上。
LeastActive
最少活跃调用数 相同活跃数随机
使慢的提供者收到更少请求,但会有马太效率,越慢的提供者调用越小
ConsistentHash
一致性hash,相同参数请求总是发到同一提供者。
一台服务器挂 一部分用户总是请求不到,而另一部分人却没事。
线程模型?
dubbo线程池满怎么解决?
- 减少Http超时时间,减少dubbo重试次数
- 加大dubbo线程容量
- dubbo限流
参考文献
Dubbu官方文档
http://dubbo.apache.org/zh-cn/docs/user/preface/background.html
秒懂Dubbo框架(原理篇)

若有收获,就点个赞吧
0 人点赞
