摘要
在软件项目中广泛采用第三方库是有益的,但也有风险。 已经采用的第三方库可能会被其维护者放弃,可能存在许可证不兼容性,或者可能不再符合当前的项目要求。 在这种情况下,开发人员需要将库迁移到另一个具有类似功能的库,但迁移决策通常是基于意见和次优的,手头的信息有限。 因此,已经提出了几种基于过滤的方法来从现有软件数据中挖掘库迁移,以利用“the wisdom of crowd”,但它们要么精度低,要么具有不同阈值的低召回率,这限制了它们在支持迁移决策方面的用处。
在本文中,我们提出了一种新方法,该方法利用多个指标(metrics)进行排名并因此推荐库迁移。
给定一个要迁移的库,我们的方法首先从大型软件存储库语料库中生成候选目标库,然后通过组合以下四个指标对它们进行排名,以从开发历史中捕获不同维度的证据:规则支持、消息支持、距离支持、 和 API 支持。 我们使用 773 条迁移规则(190 个源库)评估我们的方法的性能,这些规则是从以前的工作中借用并从 21,358 个 Java GitHub 项目中恢复的。
实验表明,我们的指标有助于识别真正的迁移目标,我们的方法明显优于现有工作,MRR 为 0.8566,top-1 精度为 0.7947,前 10 名 NDCG 为 0.7702,前 20 名召回率为 0.8939。
为了证明我们方法的通用性,我们手动验证了先前工作中未包含的 480 个流行库的推荐结果,并确认了 480 个库中的 231 个具有可比性能的 661 条新迁移规则。 源代码、数据和补充材料位于:https://github.com/hehao98/MigrationHelper。
1. INTRODUCTION
现代软件系统严重依赖第三方库来提供丰富且随时可用的功能、降低开发成本和提高生产力 [1]、[2]。 近年来,开源软件的兴起以及GitHub [3]、Maven Central [4]和NPM [5]等软件包托管平台的出现,导致开源库呈指数级增长。
但是,众所周知,第三方库会在软件演进过程中引起问题。
第三方库可能存在可持续性失败(sustainability failures)[7]、[8]。 由于缺乏时间和兴趣、维护困难或被竞争对手取代,它们可能会被维护者抛弃[7]。
第三方库可能有许可限制(license restrictions)[9]、[10]。 如果项目在早期原型设计期间使用 GPL 许可的库,则必须在项目作为专有软件发布之前替换它。
由于缺乏功能、性能问题等,第三方库可能无法满足新的需求。
为了解决这些问题中的任何一个,软件项目必须用一些其他类似或功能等效的库(即目标库)替换一些已经使用的库(即源库)。 此类活动在相关文献中称为库迁移(library migration)[12]-[19]。
然而,找到好的目标库并在多个候选库之间进行选择通常并不容易, library migration 中存在的问题如下:
- 社区策划的列表,例如 awesome-java [22] 和 AlternativeTo [23] 通常没有信息量,并且包含低质量的库
- 博客文章和文章往往是基于意见的和过时的 [20]。
- 流行度和发布频率等易于访问的指标的用处有限,并且它们因领域而异[21]。
在实践中,行业项目往往依赖领域专家来制作迁移决策 [24],而开源项目仅在核心开发人员在讨论中达成共识时才迁移库 [15]。
在任何一种情况下,都不能保证迁移是合适的、具有成本效益的或对项目有益的。
为了应对这些挑战,研究人员提出了几种从现有软件数据中挖掘库迁移的方法 [12]、[14]、[17]。 其基本原理是,历史迁移实践为开发人员做出迁移决策提供了有价值的参考和指导,如果分析的软件语料足够大且质量足够高,则可以从中发现最佳决策。
他们的方法首先从大量项目中挖掘候选迁移规则,然后根据频率 [12] 或相关代码更改 [17] 过滤候选。 然而,由于两个原因,这些方法要么召回率低 ,要么精度低。
- 定义了全局过滤阈值,但并非对所有迁移场景都同样有效,因此难以达到性能平衡。
- 在过滤指标中不考虑有价值的信息源。
本文提出了一种新方法,用于从现有软件开发历史中自动推荐库迁移目标。 我们将这个问题表述为挖掘和排名问题,而不是挖掘和过滤,因为我们观察到相对排名位置不仅更重要,而且对度量和参数变化也更稳健。
- 给定一个源库,我们的方法首先从从大量软件开发历史语料库构建的依赖项更改序列中挖掘候选目标库。
- 据四个精心设计的指标组合对候选者进行排名:规则支持、消息支持、距离支持和 API 支持。
- 人工检查排名结果。
2. BACKGROUND
3. APPROACH
我们推荐库迁移的方法包括两个步骤,一个挖掘步骤和一个排名步骤。 我们首先描述如何为每个 dep seq 挖掘候选规则。 然后我们详细说明我们如何设计四个排名指标。 最后,我们描述了最终算法的置信度值、排名策略和伪代码。
3.1 Mining Candidate Rules
给定一个 library a,我们推荐算法的第一步是找到一组候选规则
其中 x 可能是一个可行的迁移目标。
由于其高覆盖率,我们遵循与 [14] 类似的过程来挖掘候选规则(candidate rules, Rc) (等式 7)。 由于已知会产生许多误报,我们将在度量计算期间专门考虑从同一修订版(等式 4 中的  )中挖掘出的候选规则。 我们还收集了每个候选规则 (a, b) 的所有相关配对修订(relevant revision pairs),定义为
)中挖掘出的候选规则。 我们还收集了每个候选规则 (a, b) 的所有相关配对修订(relevant revision pairs),定义为
3.2 Four Metrics for Ranking
3.2.1 Rule Support
对于每个候选规则 (a, b),我们将规则计数(Rule Count) RC(a, b) 定义为在同一修订版中删除 a 和添加 b 的次数
我们将 Rule Support RS(a, b) 定义为 Rule Count 除以 a 作为源库的所有候选规则的 Rule Count 的最大值,
3.2.2 Message Support
除了以 Rule Support 为特征的“隐式”基于频率的提示外,我们观察到由开发人员编写的随修订消息(例如提交消息或发行说明)提供的“显式知识”非常有价值。 因此,我们设计了以下启发式方法来确定修订对 (ri, rj) 是否似乎正在从 a 迁移到 b.
首先,我们将 a 和 b 的名称拆分为可能提供信息的部分,因为开发人员经常使用缩写名称在这些消息中提及库。
对于 ri = rj ,我们检查它的消息是否表明准备开始从 a 迁移到 b。
对于 ri != rj ,我们检查 ri 的消息是否在提及 a 的同时说明了库 b 的引入,以及 rj 的消息是否说明了删除 a 作为清理。
例如,我们认为“迁移”、“替换”、“切换”等词暗示迁移。
其中 1 表示根据该启发性规制,当前 message 被认定为发生了迁移。
我们将 Message Count MC(a, b) 定义为修订对 (ri, rj) 的数量,其消息指示发生了从 a 到 b 的迁移,其中 b 添加到 ri 中,a 在 rj 中被删除

3.2.3 Distance Support
前两个指标没有考虑没有任何有意义消息的多版本迁移,但这种情况可能仍然很常见,因为并非所有开发人员都编写高质量的消息。 基于观察到大多数真实目标库是在源库移除附近引入的,我们设计了距离支持度量来惩罚经常出现在远处的候选库。 令 dis(ri, rj) 为修订版 ri 和 rj 之间的修订版数(如果 ri = rj 则为 0)。 我们将距离支持 DS(a, b) 定义为所有修订对 (ri, rj) ∈ Rev(a, b) 的平方反比距离的平均值:

3.2.4 API Support
库迁移的另一个重要信息来源是两个库之间执行的真实代码修改和 API 替换。 为了捕捉这一点,我们将 API Count AC(a, b) 定义为 Rev(a, b) 中的代码块数(hunk 是通过版本控制系统的 diff 算法提取的一组添加和删除的行。),其中 API(即对公共的引用)_添加了 b 的方法和字段并删除了 a 的 API。 然后,我们将 API 支持定义为

设置最小阈值的原因是为了在某些迁移规则未检测到 API 更改的情况下使 AS 更加健壮。 发生这种情况要么是因为代码更改与依赖项配置文件不同步执行,要么是因为某些库可以单独使用配置文件。 例如,从 ground truth(第 VB 节)手动分析 100 个迁移提交显示,45 个迁移提交不包含任何相关的 API 更改,其中 26 个提交仅修改 pom.xml 文件,12 个提交修改配置文件,其他修改 以一种库 API 不会在一个大块中共同更改的方式编写代码。
3.3 Recommending Migration Targets
我们的推荐算法结合了上面介绍的四个指标来为所有候选规则生成一个最终的置信度值,使用一个简单的乘法如下
对于每个库查询 l ∈ Q,对应的候选规则按照这个置信度值从大到小排序。 如果某些候选规则的置信度值相同,我们进一步使用 RS 对其进行排序。 最后,推荐结果以及相关修订对,按每个库查询分组,返回供人工检查。
算法 1 提供了我们的迁移推荐算法的完整描述。
- 在初始化所需的数据结构后(第 1-5 行)
- 我们生成候选规则并在所有项目及其 dep seq 的一次迭代中积累用于度量计算的必要数据(第 6-14 行)
- 之后,通过所有候选规则的另一次迭代计算度量和置信度值(第 15-24 行)

4. IMPLEMENTATION
本节介绍了方法实现中的设计考虑,运行环境,数据集准备,API 指标的预处理。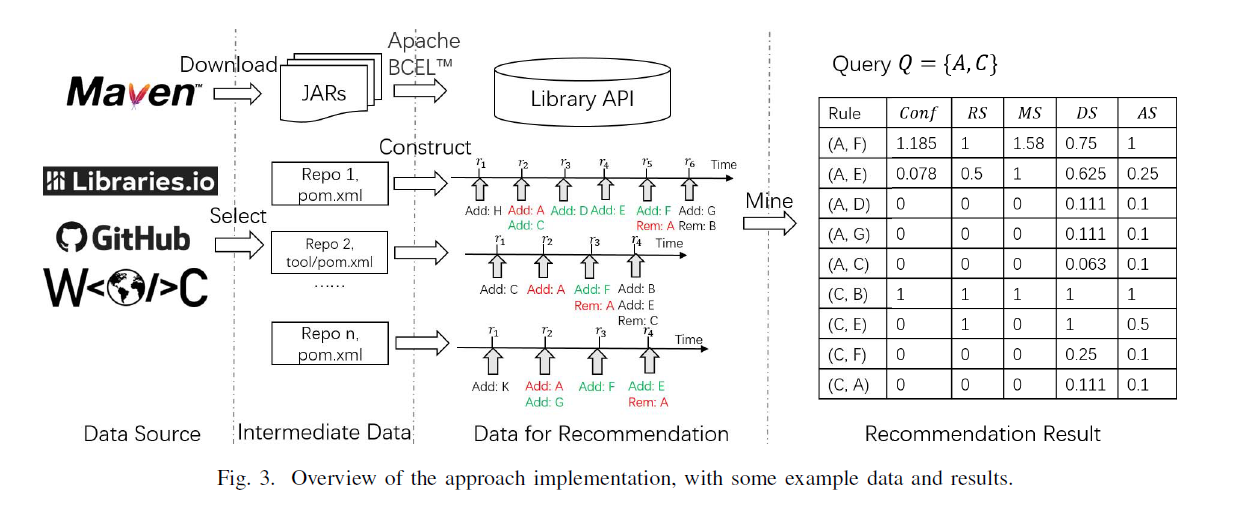
5. EVALUATION
在评估阶段,本文数据集准备
- 21,358 个 Java GitHub 存储库的版本控制数据,从它们的依赖配置文件(pom.xml)中提取了 147,220 个依赖更改序列。在 Maven Central 中收集 Maven artifacts,并为每个收集的 Maven artifacts 提取 API 信息。
我们将上述数据集合处理成两个真实数据集用于不同的评估目的。
第一个是采用以前的工作A study of library migrations in java 2014的数据集,并在我们收集的 21,358 个存储库中恢复(因为自其发布以来,当前情况可能发生了重大变化)。
- 获得 773 个迁移规则(190 个源库)的 ground truth。 我们使用 190 个源库作为我们方法的查询,它返回 243,152 条候选规则及其指标。
这组 ground truth 对其中的源库具有相当好的覆盖率,因此我们可以计算准确的性能指标并比较不同的方法。
第二个是从我们算法在 21,358 个存储库上的推荐结果中手动验证的,其中 480 个最流行的库作为查询。 我们使用这个数据集来验证我们的方法可以在新数据集上很好地泛化,并确认具有可比性能的真实词迁移。
在接下来的部分中,我们将第一个真实数据集称为 GT2014,将第二个称为 GT2020
5.1 RQ1: How effective is RS, MS, DS, and AS in identifying real migration targets?
为了回答 RQ1,我们分别绘制了之前研究工作[12] 的置信度值、四个指标和我们方法的最终置信度值的生存函数。
我们可以在图 4 中观察到,真实规则对于所有指标通常具有显着更高的生存概率,表明每个指标的有效性。 我们还可以观察到,任何过滤阈值 x 都会导致显着的基本事实损失或许多其他候选规则由于其数量大得多而无法生存。 因此,尽管每个指标都有效,但我们得出结论,任何基于过滤的方法本质上都是无效的,我们应该利用相对排名位置而不是绝对指标值来从大量候选者中选择迁移规则。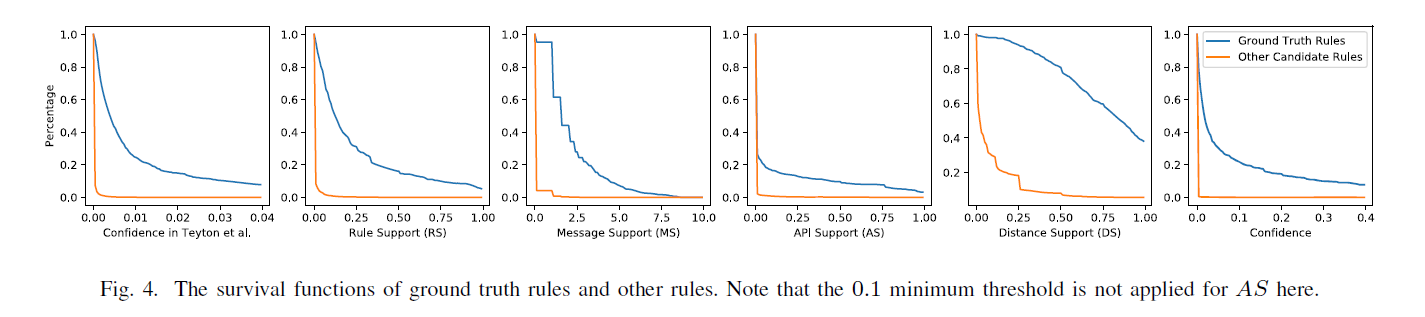
5.2 RQ2: What is the performance of our approach, compared with baselines and existing approaches?
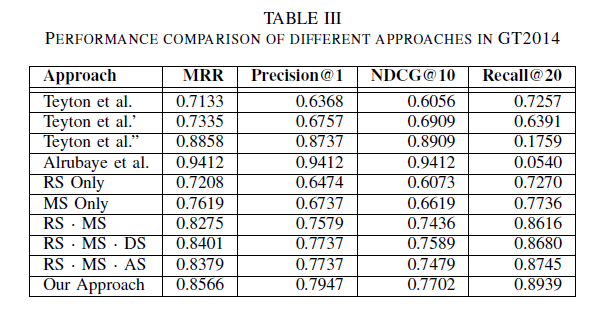
Mean Reciprocal Rank (MRR) 平均倒数秩被定义为所有查询的第一个真实规则的秩的乘法倒数的平均值,它的范围在 [0, 1] 之间,较高的值意味着用户可以更快地看到每个查询的第一个真实值:


Normalized Discounted Cumulative Gain (NDCG) 归一化贴现累积增益 (NDCG) 衡量排名结果偏离理想结果的程度,其范围在 [0, 1] 中,其中 1 表示与理想的 top-k 排名结果完美匹配,0 表示最差。
• Teyton et al. [12]: Use  (Equation 6) for ranking.
(Equation 6) for ranking.
• Teyton et al.’ [12]: Keep rules  ≥ 0.002 and rank.
≥ 0.002 and rank.
• Teyton et al.” [12]: Keep rules  ≥ 0.015 and rank.
≥ 0.015 and rank.
• Alrubaye et al. [17]: Filter out RS < 0.6 or AC = 0.
• RS Only: Use only RS for ranking.
• MS Only: Use only MS for ranking.
• RS · MS: Use RS ·MS for ranking.
• RS · MS · DS: Use RS ·MS · DS for ranking.
• RS · MS · AS: Use RS ·MS · AS for ranking.
为了证明我们方法的通用性,我们使用 GT2020 进一步计算了 231 个查询的质量指标。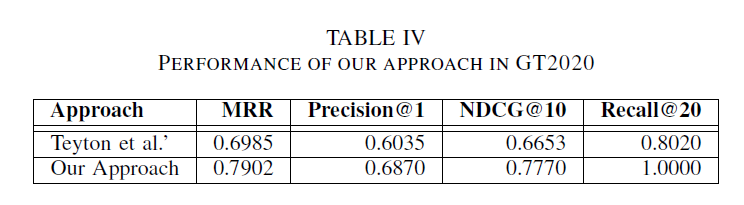

若有收获,就点个赞吧
0 人点赞
