Methodology
A Multi-Metric Ranking Approach for Library Migration Recommendations
MIGRATIONADVISOR WORKFLOW

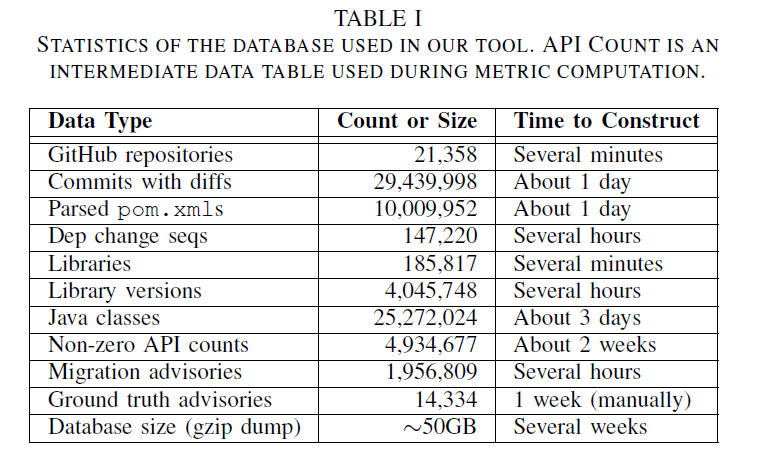
1. Data Preparation
选择 Java 和 Maven 来实现工具
选择 Libraries.io dataset (截止2020.1)收集 libraries and repositories,我们获得了 184,817 个不同 libraries 的列表(即 具有不同 group ID 和 artifact ID 的 Maven artifact)以及 21,358 个 Maven 管理的 non-fork GitHub repositories 列表(其中至少有 10 颗星和三个 pom.xml 更改)
对于每个 library ,从 Maven Central 检索其版本信息和其他元数据,从而产生 4,045,748 个不同的库版本。 对于每个版本,我们从 Maven Central 下载其对应的 JAR 文件(如果有),并从 JAR 文件中提取所有公共类。 对于每个类,它被转换成一个紧凑的 API 签名文档,该文档对其所有公共字段、方法和继承关系进行编码。文档存储在图书馆数据库中。 其他库元数据(例如版本、依赖项和描述)也存储在库数据库中以供进一步使用。
对于每个 GitHub repository,我们从 World of Code (相比于直接从 GitHub clone 并使用 git 分析相比,它为分析目的提供了更高的性能)中检索其所有版本控制数据(commits, trees, blobs)。 然后我们在此存储库中收集所有 pom.xml 文件及其所有历史版本。 对于每个 pom.xml 文件,我们遍历其所有历史版本并与之前的版本比较,提取这个版本中发生的依赖变化。 通过合并来自不同提交和分支的依赖更改,我们为每个 pom.xml 文件生成一个依赖更改序列,其中包含此 pom.xml 文件的所有库采用、删除和更新历史。
给定上述数据,最终的迁移顾问数据库由迁移目标推荐的多度量排序算法生成。

2. Data Consumption
数据消费组件,用作项目开发人员和维护人员的接口。 给定要迁移的源库,它应该提供来自咨询数据库的迁移建议的信息性和交互式演示。
对于当前的工具演示,它被实现为搜索引擎样式的 Web 服务,用户可以在其中搜索特定库的迁移目标。 给定一个搜索查询,Web 服务将从咨询数据库中检索所有目标库,按置信度值对它们进行排序,并将它们返回到一个分页表中,其中每个表条目展示一个目标库。 对于每个条目,用户还可以扩展条目以获取更详细的信息,包括库描述、主页、存储库链接和 GitHub 存储库/提交,这些信息可能已经从给定的源库迁移到此条目中的目标库。
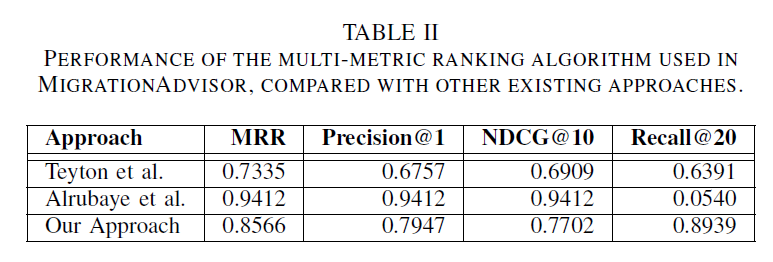
EVALUATION

若有收获,就点个赞吧
0 人点赞
