文章地址 https://ieeexplore.ieee.org/document/6035728
Abstract
本文描述了 GenProg,一种用于修复现成遗留程序缺陷的自动化方法,无需正式规范、程序注释或特殊编码实践。 GenProg 使用遗传编程的扩展形式来进化保留所需功能但不易受给定缺陷影响的程序变体,使用现有测试套件对缺陷和所需功能进行编码。 结构差分算法和增量调试将此变体与原始程序之间的差异减少到最小程度的修复。 我们描述了该算法并报告了它在 16 个程序上成功的实验结果,总共 125 万行 C 代码和 120K 行模块代码,跨越 8 类缺陷,平均在 357 秒内。 我们定性和定量地分析生成的修复,以证明该过程有效地产生了修复缺陷的进化程序,不是脆弱的输入记忆,并且不会导致功能的严重退化。
1INTRODUCTION
软件质量是一个有害的问题。 成熟的软件项目被迫同时包含已知和未知的错误 [1],因为未解决的软件缺陷的数量通常超过可用于解决它们的资源 [2]。 软件维护,其中错误修复是主要组成部分 [3],[4],耗时且昂贵,占软件项目成本的 90% [5],总成本高达 美国每年 700 亿美元 [6]、[7]。 简而言之:错误无处不在,查找和修复它们是困难、耗时且手动的过程。 自动检测软件缺陷的技术包括入侵检测 [8]、模型检查和轻量级静态分析 [9]、[10] 和软件多样性方法 [11]、[12]。 然而,检测缺陷只是故事的一半:一旦发现缺陷,仍然必须修复缺陷。 随着软件部署的规模和缺陷报告频率的增加[13],必须自动解决修复问题的某些部分。
本文描述并评估了遗传程序修复(“GenProg”),这是一种使用现有测试用例自动为现成的遗留应用程序中的实际错误生成修复的技术。 我们关注 Rinard 等人。 [14] 将修复定义为由一个或多个代码更改组成的补丁,当应用于程序时,使其通过一组测试用例(通常包括所需行为的测试以及编码 漏洞)。 测试用例可以是人工编写的、取自回归测试套件、重现错误的步骤或自动生成的。 我们交替使用术语“修复”和“补丁”。 GenProg 不需要正式的规范、程序注释或特殊的编码实践。 GenProg 的方法是通用的,论文报告的结果表明 GenProg 可以成功修复几种类型的缺陷。 这与仅修复特定类型缺陷(例如缓冲区溢出[15]、[16])的相关方法形成对比。
GenProg 将具有缺陷和一组测试用例的程序作为输入。 GenProg 可以应用于完整的程序源或单个模块。 它使用遗传编程 (GP) 来搜索保留所需功能但不易受相关缺陷影响的程序变体。 GP 是一种受生物进化启发的随机搜索方法,它发现为特定任务定制的计算机程序 [17]、[18]。 GP 使用生物突变和交叉的计算类似物来生成新的程序变体,我们称之为变体。 用户定义的适应度函数评估每个变体; GenProg 使用输入的测试用例来评估适应度,选择适应度高的个体进行持续进化。 当这个 GP 过程产生一个变体时,它是成功的,该变体通过了对所需行为进行编码的所有测试,并且没有使那些编码错误的测试失败。 尽管 GP 已经解决了一系列令人印象深刻的问题(例如,[19]),但它以前没有被用于发展现成的遗留软件或修补现实世界的漏洞,尽管有各种针对自动错误修复的建议,例如, [20]
迄今为止,GP 努力的一个重大障碍是必须搜索潜在的无限空间才能找到正确的程序。 我们介绍了三个关键创新来解决这个长期存在的问题[21]。 首先,GenProg 在程序抽象语法树 (AST) 的语句级别运行,增加了搜索粒度。 其次,我们假设在一个区域包含错误的程序可能在其他地方实现正确的行为[22]。 因此,GenProg 仅使用程序本身的语句来修复错误,而不发明新代码。 最后,GenProg 将遗传运算符本地化为在失败的测试用例上执行的语句。 这第三点很关键:故障定位通常是一个难以解决的问题。 我们方法的可扩展性依赖于现有的、不完善的策略,并且存在不能总是被本地化的缺陷类别(例如,非确定性错误)。 然而,对于这里考虑的缺陷,我们发现这些选择充分减少了搜索空间,以允许自动修复一组不同的程序和错误。
GP 过程通常会在修复过程中引入不相关的更改或死代码。 GenProg 在后处理步骤中使用结构差异 [23] 和 delta 调试 [24] 来获得对原始程序的 1 最小更改集,以使其通过所有测试用例。 我们称这组为最终修复。
- GenProg,一种使用 GP 自动为程序中的错误生成补丁的算法,经测试用例验证。 该算法包括用于将 GP 应用于该域的新颖且有效的表示和一组操作。 这是第一个展示使用 GP 来修复具有公开记录错误的真实、未注释程序规模的软件的工作。
- 实验结果表明,GenProg 可以有效修复 16 个 C 程序中的错误。 因为算法是随机的,我们报告每个程序平均超过 100 次试验的成功率。 对于每个程序,至少有一次试验发现成功修复,平均成功率从 7% 到 100% 不等。 在所有项目和所有试验中,我们报告的平均成功率为 77%。
- 实验结果表明,该算法可以修复来自多个域的程序中的多种类型的错误。 这些错误涵盖八种不同的缺陷类型:无限循环、分段错误、远程堆缓冲区溢出以注入代码、远程堆缓冲区溢出以覆盖变量、非溢出拒绝服务、本地堆栈缓冲区溢出、整数溢出和格式字符串漏洞。 基准程序包括 Unix 实用程序、服务器、媒体播放器、文本处理程序和游戏。 尽管 GenProg 直接在 120K 行程序或模块代码上运行,这 16 个基准测试总共超过 125 万行代码 (LOC)。
其中一些观点以前在这项工作的早期版本中提出 [25]、[26] 或为普通观众总结 [27]。 本文将这些结果扩展到包括:
- 新的维修。 以前的工作显示修复了 11 个程序,总计 63K 行代码和四类错误。我们展示了另外五个程序,并表明 GenProg 可以在整个程序的源代码以及模块级别上运行。 新的基准测试包括 120 万行新的源代码、6 万行已修复的新代码(模块或整个程序)和四种新类型的错误,显着增加了 GenProg 扩展到实际系统的能力。
- 闭环修复。 将 GenProg 与异常入侵检测集成的闭环修复系统的描述和概念验证评估。
- 维修质量。 使用指示性工作负载、模糊测试和变体错误诱导输入对所生产的维修质量进行部分评估,首先是手动的,然后是定量的。 我们的初步调查结果表明,修复不是对输入的脆弱记忆,而是在保留所需功能的同时解决缺陷。
2MOTIVATING EXAMPLE
3TECHNICAL APPROACH

图 2 给出了 GenProg 的伪代码。 GenProg 将包含缺陷和一组测试用例的源代码作为输入,其中包括一个测试缺陷的失败负测试用例和一组描述需求的通过正测试用例。 GP 维护着一组以树表示的程序变体。 每个变体都是原始缺陷程序的修改实例; 修改由变异和交叉操作生成,如第 3.2 节所述。 第 4 行对初始种群的调用使用变异算子根据输入程序和测试用例构建初始 GP 种群。 适应度函数评估每个人的适应度或合意度。 GenProg 使用输入测试用例来指导 GP 搜索(图 2 的第 1-3 行,第 3.1 节)以及评估适应度(第 3.3 节)。 GP 通过选择高适应度个体复制到下一代(第 9 行,第 3.2 节)并通过突变和交叉操作(第 13-15 行和第 10 行)引入变化来进行迭代。 重复此循环,直到实现目标(找到通过所有测试用例的变体)或消耗预定的资源限制。 最后,GenProg 最小化成功的变体(第 17 行,第 3.4 节)
3.1 Program Representation
GenProg 将每个变体(候选程序)表示为一对:
1. 包含程序中所有语句的抽象语法树。
2. 由程序语句列表组成的加权路径,每个语句都与基于该语句在各种测试用例执行跟踪中出现的权重相关联。
GenProg 使用现成的 CIL 工具包 [28] 生成程序 AST。 AST 以多个抽象或粒度级别表达程序结构。 GenProg 对 CIL 定义为语句的结构进行操作,其中包括所有赋值、函数调用、条件、块和循环结构。 GenProg 不会直接修改诸如“(1-2)”或“(!p)”之类的表达式,也不会直接修改诸如 break、continue 或 goto 之类的低级控制流指令。 这种基因型表示反映了表达能力和可扩展性之间的权衡。 由于对允许的程序修改的这些限制,GP 永远不会生成语法错误的程序(例如,它永远不会生成不平衡的括号)。 但是,它可以生成由于语义错误而无法编译的变体,例如,将变量的使用移出范围。
加权路径是一系列hstatement; weighti 对将变异算子约束到程序树的一个小的、可能相关的(更高权重的)子集。 不在加权路径上的语句(即权重为 0)永远不会被修改,尽管它们可能会被变异算子复制到加权路径中(参见第 3.2 节)。 每个新变体在其加权路径中具有与原始程序相同的对数和相同的权重序列。 这是交叉操作所必需的(如下所述)
为了构建加权路径,我们应用了一个转换,为每个语句分配一个唯一编号,并在每次执行语句时插入代码以记录事件(访问)(图 2 的第 1-2 行)。 从列表中删除重复的语句:也就是说,我们不假设经常访问的语句(例如,在循环中)可能是一个好的修复站点。 但是,我们确实尊重语句顺序(由第一次访问语句确定),因此加权路径是一个序列,而不是一个集合。 在负测试用例执行期间访问的任何语句都是修复的候选者,其初始权重设置为 1.0。 所有其他语句的权重为 0.0,并且从未修改过。 通过更改也由正测试用例执行的语句的权重,进一步修改负测试用例执行路径上语句的初始权重。 目标是将修改偏向于可能影响不良行为的源代码部分,同时避免那些影响良好行为的部分。 设置权重ðPathNegT; 图 2 第 3 行的 PathPosTÞ 将在至少一个正测试用例期间访问的每个路径语句的权重设置为参数 WPath。 选择 WPath ¼ 0 通过从路径中删除它来防止修改正测试用例期间访问的任何语句; 我们发现 WPath ¼ 0:01 等值通常在实践中效果更好。
加权路径用于定位故障。 这种故障定位策略很简单,而且绝不是最先进的,但已经在我们的基准程序中发挥了作用。 我们没有声称在故障定位方面有任何新的结果,而是将其视为我们可以使用相对现成的方法的优势。 路径加权对于修复我们研究过的大多数程序是必要的:没有它,搜索空间通常太大而无法有效搜索。 然而,自动和手动修复的有效故障定位仍然是一个困难和未解决的问题,并且存在某些类型的故障仍然难以定位到不可能定位。 我们预计 GenProg 将随着故障定位的进步而改进,并将技术的扩展留给使用更复杂的定位方法作为未来的工作。
3.2 Selection and Genetic Operators
Selection。 图 2 第 6-9 行的代码实现了 GenProg 选择单个变体复制到下一代的过程。 GenProg 丢弃适应度为 0 的个体(未编译或未通过测试用例的变体),并将剩余部分放在第 6 行的 Viable 中。然后它使用选择策略从上一次迭代中选择 pop size=2 的新一代成员 ; 这些个体成为新的交配池。 我们使用了随机通用抽样 [29],其中每个人的选择概率与其相对适应度 f 成正比,以及锦标赛选择 [30],其中随机选择人口的小子集(锦标赛)和最 为下一代选择合适的子集成员。 重复这个过程,直到选择了新的种群。 两种选择技术在我们的应用程序中产生相似的结果。 两个 GP 算子,突变和交叉,从这个交配池中创建新的变体。

Mutation 图 3 显示了变异算子的高级伪代码。 突变沿着加权路径(第 1 行)改变任何特定语句的可能性很小。 PathP 中的变化状态反映在其相应的 AST P 中。一个语句以等于其权重的概率发生突变,每个个体的最大突变数由全局突变率(参数 Wmut,在我们的实验中设置为 0.06 和 0.03;参见 第 5.1 节)。 第 2 行使用这些概率来确定语句是否会发生变异。
在遗传算法中,变异操作通常涉及单个位翻转或简单的符号替换。 因为我们的原始单元是语句,所以我们的变异算子更复杂,包括删除(整个语句被删除)、插入(在它之后插入另一个语句)或与另一个语句的交换。 我们以均匀随机概率从这些选项中进行选择(第 3 行)。 在插入或交换的情况下,第二条语句 stmtj 从程序中的任何位置(第 5 行和第 8 行)均匀随机选择,而不仅仅是沿着加权路径; 语句的权重不会影响它被选为候选修复的概率。 这反映了我们对相关变化的直觉:缺少空检查的程序可能在某处包含一个,但不一定在否定路径上。 在交换中,stmti 被 stmtj 替换,同时 stmtj 被 stmti 替换。 我们通过将 stmti 转换为包含 stmti 后跟 stmtj 的块语句来插入。 在当前的实现中,stmtj 在插入时不会被修改,尽管我们注意到如果插入引用范围外变量的代码,中间变体可能无法编译。 删除将 stmti 转换为空块语句; 因此,可以在以后的变异操作中修改已删除的语句。
在所有情况下,新语句保留旧语句权重以保持程序变体之间的统一路径长度和权重的不变性,并且因为插入和交换的语句可能不是来自加权路径(因此可能没有自己的初始权重) .

Crossover. 图 4 显示了交叉算子的高级伪代码。 Crossover 将一个变体的“第一部分”与另一个变体的“第二部分”结合起来,创造出结合了来自两个父母的信息的后代变体。 交叉率是 1.0——种群中每个幸存的变体都经历了交叉,尽管一个变体在每一代的一次这样的操作中只会是父代。 只有沿着加权路径的语句被交叉。 我们沿着路径(第 1 行)选择一个截止点,并在截止点之后交换所有语句。 我们已经对其他交叉算子进行了实验(例如,由路径权重产生偏差的交叉和与原始程序的交叉),并发现它们给出的结果与此处显示的单点交叉相似。
3.3 Fitness Function
适应度函数评估程序变体的可接受性。 适应度为搜索提供了终止标准,并指导下一代变体的选择。 我们的适应度函数在测试用例级别编码软件需求:负面测试用例编码要修复的故障,而正面测试用例编码不能牺牲的功能。 我们将变体的 AST 编译为可执行程序,然后记录可执行文件通过了哪些测试用例。 每个成功的阳性测试都由全局参数 WPoT 加权; 每个成功的否定测试都由全局参数 WNegT 加权。 因此,适应度函数只是加权和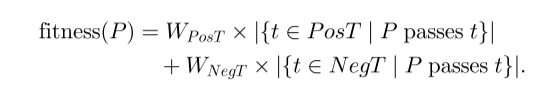
权重 WPosT 和 WNegT 应该是正的; 我们在第 5 节中给出具体值。不能编译的变体适应度为零。 为了完全安全,测试用例评估可以在虚拟机或类似的沙箱中运行,但会超时。 由于测试用例验证了修复的正确性,因此测试套件的选择是一个重要的考虑因素。
3.4 Repair Minimization
当 GP 发现通过所有测试用例的主要修复时,搜索成功终止。 由于变异和交叉算法的随机性,初级修复通常包含比修复程序所需的至少一个数量级的更改,从而使修复难以检查正确性。 因此,GenProg 将初级修复最小化以生成最终修复,以标准差异格式的编辑列表表示。 与此类补丁相关的缺陷更有可能得到解决[31]。
GenProg 通过考虑主要修复和原始程序之间的每个差异并丢弃不影响修复在任何测试用例上的行为的每个差异来执行最小化。 标准差异补丁编码具体的,而不是抽象的语法。 由于具体语法的最小化效率低下,我们采用了 DIFFX XML 差分算法 [23] 来处理 CIL AST。 修改后的 DIFFX 生成树结构编辑操作的列表,例如“移动以节点 X 为根的子树成为节点 Z 的第 Y 个子树”。 这种编码通常比相应的差异补丁更短,并且应用基于树的编辑的一部分永远不会导致语法错误的程序,这两者都使得这些补丁更容易最小化。
最小化过程找到初始修复编辑的子集,在不导致程序失败测试用例(1-最小子集)的情况下,不能从中删除更多元素。 对初始编辑列表的所有子集进行暴力搜索是不可行的。 相反,我们使用 delta 调试 [24] 来有效地计算一个最小子集,即 Oðn2Þ 最坏情况 [32]。 这组最小化的更改是最终修复。 DIFFX 编辑可以自动转换为标准差异补丁,可以自动应用到系统或提交给开发人员进行检查。 在本文中,补丁大小以 Unix 差异补丁的行数报告,而不是 DIFFX 操作。
4REPAIR DESCRIPTIONS

若有收获,就点个赞吧
0 人点赞
