Abstract
摘要——开源软件 (OSS) 项目广泛采用的软件机器人支持开发人员开展多项活动,包括代码审查。 然而,与任何新技术的采用一样,机器人可能会影响群体动态。 由于了解和预测此类影响对于规划和管理很重要,因此我们研究了在采用代码审查机器人后几个活动指标如何变化。 我们对来自 GitHub 的 1,194 个软件项目采用了回归不连续设计。 我们的结果表明,采用代码审查机器人增加了每月合并拉取请求的数量,减少了每月非合并拉取请求,并减少了开发人员之间的沟通。 从业者和维护者可以利用我们的结果来理解甚至预测机器人对他们项目社交互动的影响。
索引词——软件机器人、GitHub 机器人、代码审查、开源软件、软件工程
I. INTRODUCTION
许多开源软件 (OSS) 项目将代码审查 code review 作为开发过程的重要组成部分 [1]。 代码审查是一种众所周知的软件质量保证实践 [2]。 在基于 pull-based 的开发模型中,项目维护人员仔细检查代码更改并与贡献者进行讨论,以了解和改进修改,然后再将它们集成到代码库中 [3]。 维护人员花在审查拉取请求上的时间是不可忽略的,并且会影响例如新贡献者的数量 [4] 和新人的引导 [5]。
在这种情况下,软件机器人通过充当用户和其他工具 [7] 之间的接口并减少维护者和贡献者的工作量,在代码审查过程 [6] 中发挥着重要作用。 完成以前仅由人类开发人员执行的任务,并在与人类同行相同的通信渠道中进行交互,机器人已成为代码审查对话中的新声音 [8]。 代码审查机器人指导贡献者在维护者对拉取请求进行分类之前提供必要的信息 [6]。
然而,众所周知,新技术的采用可能会带来与技术设计者和采用者的期望不同的后果 [9]。 许多旨在为用户服务的系统最终增加了新的负担。 先验期望技术发展产生的开发人员显着的性能改进可能会因事后意外的操作复杂性而措手不及 [10]。 因为,根据 Mulder 等人的说法。 [11],许多影响不是由新技术本身直接引起的,而是由它引发的人类行为的变化引起的,评估和讨论新技术对群体动力学的影响很重要,而这对于软件来说往往被忽视 机器人。
在代码审查过程中,机器人可能会以多种方式影响现有的项目活动。 例如,虽然项目维护者可能会将他们的精力用于其他活动,但机器人可能会提供糟糕的反馈 [6, 12],从而导致贡献者退出——事实上,众所周知,缺乏对拉取请求的反馈会阻碍进一步的贡献 [13]。
我们的目标是了解在采用代码审查机器人后 GitHub 项目的 PR 动态如何变化。 为了了解采用机器人后会发生什么,我们使用回归不连续性设计 [14] 对托管在 GitHub 上的 1194 个 OSS 项目中采用代码审查机器人的影响进行建模。 因此,我们的主要研究问题是:
RQ. How do pull request activities change after a code review bot is adopted in a project?
扩展 Wessel 等人的工作。 [6],我们调查项目活动指标的变化,例如合并和未合并的 PR 数量、评论数量、关闭PR 的时间以及每个 PR 的提交次数。 使用时间序列分析,我们考虑了机器人采用的纵向影响。 我们还更进一步,探索大量开源项目样本,并专注于了解特定机器人类别的影响。
分析统计模型,我们发现在代码审查机器人采用后,更多的 PR 被合并到代码库中,贡献者和维护者之间的沟通更少。 考虑到非合并 PR,在机器人采用后,项目每月的非合并 PR 更少,PR 拒绝速度更快。
在本文中,我们做出了以下贡献:
- 在采用代码审查机器人后识别项目活动指标的变化;
- 阐明引入机器人如何影响 OSS 项目。
这些贡献旨在帮助从业者和维护者了解机器人对项目的影响,尤其是避免他们认为不受欢迎的那些。 此外,我们的发现可能会指导开发人员在设计新机器人时考虑它们的影响。
II. EXPLORATORY CASE STUDY
由于人们对采用代码审查机器人在拉取请求动态中的影响知之甚少,我们进行了探索性案例研究 [15, 16] 来制定假设以在我们的主要研究中进一步调查。
A. Case Study Method
为了进行我们的探索性案例研究,我们选择了两个我们知道使用代码审查机器人至少几年的项目:Julia 编程语言项目 1 和 CakePHP,2 PHP。 这两个项目都有流行且活跃的存储库——Julia 有超过 26.1k 星、3.8k 分叉、17k 拉请求和 46.4k 提交,而 CakePHP 有超过 8.1k 星、3.4k 分叉、8.6k 拉请求、40.9k 提交 ,并被 10k 个项目使用。 这两个项目都采用了一个名为 Codecov 的代码审查机器人,它在 2016 年 7 月向 Julia 项目和 2016 年 4 月向 CakePHP 发布了关于拉取请求的第一条评论
选择项目后,我们使用 GHTorrent 数据集 [17] 中可用的数据分析了机器人采用前一年和后一年的数据。 在此期间,Julia 和 CakePHP 采用的唯一机器人是 Codecov 机器人。 与之前的工作 [18] 类似,我们排除了机器人采用前后的 30 天,以避免在此期间造成的不稳定性的影响。 之后,考虑到机器人引入前后的 12 个月,我们将个人拉取请求数据汇总到每月期间。 我们根据以前的文献 [18, 19, 20] 选择月份时间范围。 所有指标都是根据拉取请求关闭/合并的月份汇总的。
我们考虑了 Wessel 等人在之前的工作中使用的相同活动指标。 [6]:
Merged/non-merged pull requests: 已合并或已关闭但未合并到项目中的每月贡献(拉取请求)的数量,计算每个时间范围内所有关闭的拉取请求。
Comments on merged/non-merged pull requests: 每月评论的中位数 - 不包括机器人评论 - 计算每个时间范围内所有合并和未合并的拉取请求。 我们使用中位数是因为分布是倾斜的
Time-to-merge/time-to-close pull requests 每月拉取请求延迟的中位数(以小时为单位),计算为拉取请求关闭时间与打开时间之间的差异。 中位数是使用每个时间范围内的所有合并和非合并拉取请求计算的。 我们使用中位数是因为分布是倾斜的
Commits ofmerged/non-merged pull requests 每个时间范围内所有合并和未合并的拉取请求计算的每月提交的中位数。 我们使用中位数是因为分布是倾斜的
我们进行了统计测试来比较活动指标。 机器人采用前后的分布。 由于样本很小,并且机器人介绍周围没有大量数据点,我们使用了非参数 Mann-WhitneyWilcoxon 检验 [21]。 在这种情况下,原假设 (H0) 是采用前和采用后的分布相同,而备择假设 (H1) 是这些分布不同。 我们还使用 Cliff 的 Delta [22] 来量化这些观察组之间的差异,而不是 p 值解释。 此外,我们检查了每个指标的月度分布,以寻找变化的迹象。
如前所述,案例研究帮助我们为主要研究制定假设,其中包括一千多个项目。 每当我们观察到我们在案例研究中分析的两个项目中的至少一个项目的指标发生变化时,我们都会提出假设
B. Case Study Results
两个项目的合并 PR 数量增加(Julia:p 值 0.0003,δ = -0.87;CakePHP:p 值 0.001,δ = -0.76),而两个项目的非合并 PR 减少(Julia:p 值 0.00007,δ = 0.87;CakePHP:p 值 0.00008,δ = 0.95)。 图 1 显示了两个项目在采用机器人之前和之后的每月合并和非合并拉取请求的数量,分别位于顶部和底部。 基于这些发现,我们假设:
H1.1 引入代码审查机器人后,每月合并拉取请求的数量增加。
H1.2 引入代码审查机器人后,每月非合并拉取请求的数量减少。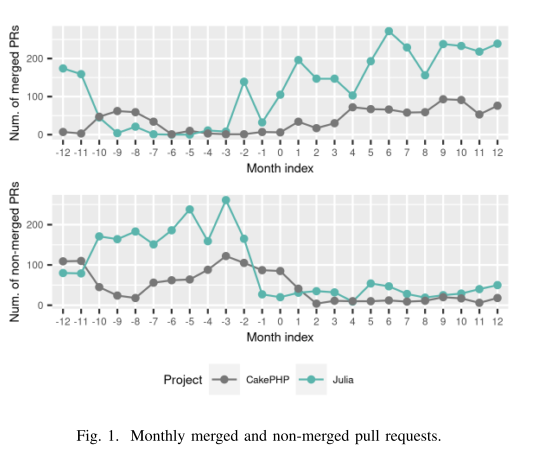
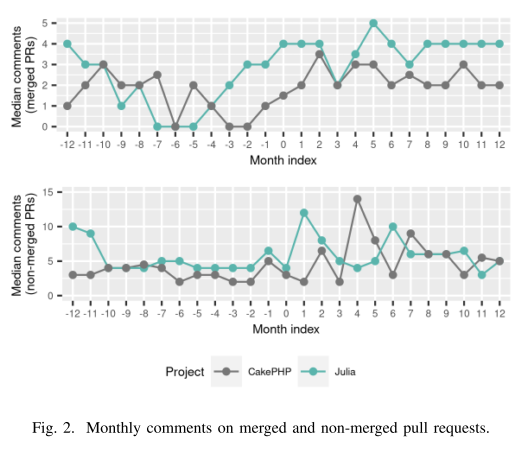
图 2 分别显示了合并和非合并拉取请求的每月评论中位数。 CakePHP 显示采用前和采用后分布之间的统计显着差异。 对于合并的拉取请求(p 值 = 0.01,δ = -0.56)以及具有较大影响大小的非合并请求(p 值 = 0.03,δ = -0.50),评论数量增加。 因此,我们假设:
H2.1 采用代码审查机器人与合并拉取请求的每月评论数量增加有关。
H2.2 采用代码审查机器人后,非合并拉取请求的每月评论数量增加。
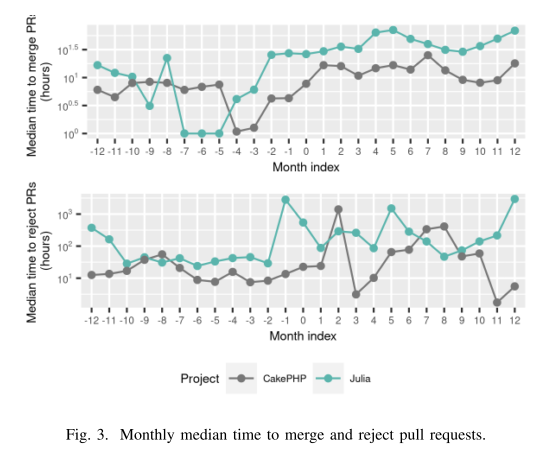
两个项目合并拉取请求的中位时间都增加了(Julia:p 值 0.0003,δ = -1.00;CakePHP:p 值 0.000001,δ = -0.98)。 考虑到非合并的拉取请求,采用前和采用后之间的差异仅对 Julia 具有统计意义。 对于这个项目,中位时间关闭拉取请求增加(p 值 0.00007),影响大小较大(δ = -0.65)。 分布如图 3 所示。因此,我们假设:
H3.1 引入代码审查机器人后,每月合并拉取请求的时间有所增加。
H3.2 在采用代码审查机器人后,每月拒绝拉取请求的时间有所增加。
调查每月提交的拉取请求数量(参见图 4),我们注意到采用前的中位数非常稳定,尤其是对于合并的拉取请求。 相比之下,采用后,我们观察到更多的差异。 差异仅对 CakePHP 具有统计学意义,合并拉取请求 (p-value=0.002, δ = -0.58) 和非合并拉取请求 (p-value=0.002, δ = -0.69) 的拉取请求提交数量增加 ) 具有较大的效应量。 基于此,我们提出:
H4.1 采用代码审查机器人后,每月提交合并拉取请求的数量有所增加。
H4.2 采用代码审查机器人后,非合并拉取请求的每月提交数量有所增加。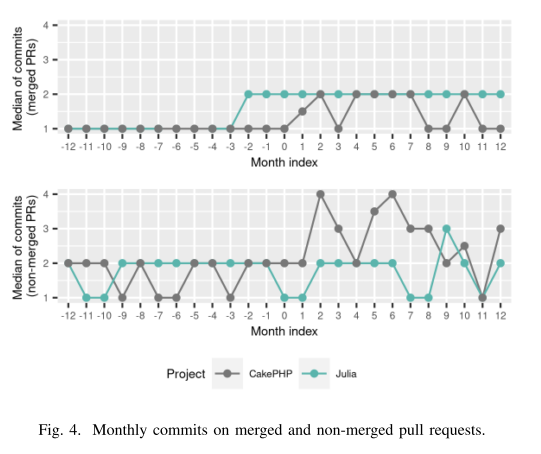
总之,与 Wessel 等人不同。 [6],我们观察到我们在两个项目中至少一个项目中调查的所有四个活动指标的统计显着差异。 基于这些观察,我们制定了假设以在我们的主要研究中进一步研究,包括大量项目并采用回归不连续设计。
III. MAIN STUDY DESIGN
下面,我们介绍主要研究的统计方法和数据收集程序。
A. Statistical Approach
考虑到案例研究中提出的假设,在我们的主要研究中,我们采用时间序列分析来解释机器人采用的纵向影响。 我们采用了回归不连续性设计 (RDD) [14, 23],该设计在过去 [18, 20] 中已应用于软件工程。 RDD 是一种用于对干预时和干预后很长时间内的不连续程度进行建模的技术。 该技术基于这样的假设,即如果干预不影响结果,则不会出现不连续性,并且结果将随着时间的推移是连续的 [24]。 RDD背后的统计模型是
其中 i 表示给定项目的观察结果。 为了模拟时间的流逝以及机器人的引入,我们包括三个额外的变量:时间、干预后的时间和干预。 时间变量以从每个项目(24 个月)的观察期开始到结束的时间 j 的月数来衡量。 干预变量是一个二进制值,用于指示时间 j 发生在采用事件之前(干预 = 0)还是之后(干预 = 1)。 干预后的时间变量计算自机器人采用以来在时间 j 的月数,并且该变量在采用之前设置为 0。
controlsi 变量可以分析机器人采用效果,而不是混淆影响因变量的效果。 对于干预前的观察,保持控制不变,所得回归线的斜率为 β,干预后为 β + δ。 干预效果的大小被衡量为干预时 yi 的两个回归值之间的差值等于 γ。
考虑到我们对代码审查机器人对拉取请求数量、评论数量、拉取请求关闭时间和拉取请求提交数量的每月趋势的影响感兴趣,所有这些都合并 和非合并的拉取请求,我们拟合了八个模型(2 个案例 x 4 个变量)。 为了平衡假阳性和假阴性,我们使用 Benjamini 和 Hochberg [25] 的方法应用多次校正后报告校正后的 p 值。 我们使用 R 包 lmerTest [26] 将 RDD 模型实现为混合效应线性回归。
为了捕捉项目间和语言间的可变性,我们将项目名称和编程语言建模为随机效应 [27]。 通过将这些特征建模为随机效应,我们可以解释和解释跨项目或编程语言观察到的不同行为 [18]。 我们使用边际 (R2) 评估模型拟合
在混合效应回归中,用于对干预建模的变量以及其他固定效应在所有项目中汇总,从而产生可用于解释的系数。 这些回归系数的解释支持对干预及其影响(如果有的话)的讨论。因此,我们报告了回归中的显着系数 (p < 0.05) 及其方差,使用 ANOVA 获得。 此外,我们对具有高方差的固定效应和因变量进行对数变换 [29]。 我们还考虑了多重共线性,不包括方差膨胀因子 (VIF) 高于 5 [29] 的任何固定效应。
B. Data Collection
1) Candidate projects 为了识别托管在 GitHub 上的开源软件项目,这些项目在某个时候采用了代码审查机器人,我们查询了 GHTorrent 数据集 [17] 并过滤了其中至少一个拉取请求评论由所识别的代码审查机器人之一提出的项目 韦塞尔等人。 [6]。 按照赵等人使用的方法。 [18] 为了组装一个时间序列,我们只考虑那些在机器人采用之前和之后至少活跃一年的项目。 我们发现 4, 767 个项目至少采用了一个代码审查机器人。 对于每个项目,我们收集了所有合并和非合并拉取请求的数据。
2) Aggregating projects variables 与探索性案例研究(见第二部分)类似,我们在每月的时间范围内汇总了项目数据,并收集了我们预计会受到机器人引入影响的四个变量:合并和非合并拉取请求的数量、中位数 评论数、关闭拉取请求的中位数时间和提交数的中位数。 所有这些变量都是根据在一个时间范围内合并和未合并的拉取请求计算的
我们还使用 GHTorrent 数据集收集了六个控制变量[17]
Project name 项目名称,用于在 GitHub 上标识项目。 我们考虑到不同的项目可能导致不同的贡献模式这一事实。
Programming language 由 GitHub 自动确定和提供的主要项目编程语言。 我们认为使用不同编程语言的项目可能会导致不同的活动和贡献模式
Time since the first pull request
Total number of pull request authors
Total number of commits
Number of pull requests opened
3) Filtering the final dataset 在排除不稳定时期(采用前后 30 天)后,我们检查了数据集,发现 223 个项目没有任何所研究的机器人撰写的评论。 我们手动检查了其中 30% 的案例,并得出结论,某些项目仅在测试期间添加了机器人,然后将其禁用。 我们从数据集中删除了这 223 个项目。
我们还检查了候选项目的活动水平,因为 GitHub 上的许多项目都处于非活动状态 [30]。 我们从我们的数据集项目中排除了在机器人采用前后一年期间没有至少六个月持续拉取请求活动的项目。 应用此过滤器后,剩下一组 1, 740 个 GitHub 软件项目。 为了确保我们分别观察每个机器人的影响,我们还从我们的数据集中排除了采用多个研究机器人的 78 个项目和使用非代码审查机器人的 196 个项目。 此外,我们检查了候选项目上机器人的活动水平。 我们排除了过去四个月内没有收到任何评论的 272 个项目。 应用所有过滤器后,剩下 1、194 个 GitHub 软件项目。 表 I 显示了每个机器人的项目数量。 所有这四个机器人都在拉取请求上执行类似的任务——为拉取请求提供关于代码覆盖率的评论。
IV. MAIN STUDY RESULTS
在本节中,我们从四个维度讨论采用代码审查机器人对项目活动的影响:(i) 接受和拒绝的拉取请求,(ii) 沟通,(iii) 拉取请求解决效率,以及 (iv) 修改工作。
A. Effects in Merged and Non-merged Pull Requests
我们首先调查采用机器人对合并和非合并拉取请求数量的影响。 从探索性案例研究中,我们假设代码审查机器人的使用与每月合并拉取请求数量的增加和每月非合并拉取请求数量的减少有关。 我们拟合了两个混合效应 RDD 模型,如第 III-A 节所述。 对于这些模型,每月合并/非合并拉取请求的数量是因变量。 表二总结了这两个 RDD 模型的结果。 除了模型系数外,该表还显示了平方和,并解释了每个变量的方差。
分析合并拉取请求的模型,我们发现固定效果部分很好地拟合了数据(R2 m = 0.68)。 然而,考虑到 R2 c = 0.75,项目间和语言间也出现可变性。 在固定效应中,我们观察到每月拉取请求的数量解释了模型中的大部分可变性。 正如预期的那样,这表明收到更多贡献的项目往往有更多合并的拉取请求,而其他变量保持不变。
此外,时间序列预测器的统计显着性表明,代码审查机器人的采用影响了合并拉取请求数量的趋势。 我们注意到采用前的增长趋势; 在采用时存在统计上显着的不连续性; 采用后的积极趋势表明合并拉取请求的数量增长得更快。
与之前的模型类似,非合并拉取请求模型的固定效应部分很好地拟合了数据(R2 0.67),尽管随机效应解释了相当多的可变性(R2 m = c = 0.74)。 我们注意到关于固定效果的类似结果:收到更多贡献的项目往往有更多未合并的拉取请求。 该模型的所有时间序列预测变量都具有统计显着性,表明采用代码审查机器人对审查和接受拉取请求的时间产生了可衡量的影响。 我们注意到采用前的下降趋势,采用时的统计显着不连续性,采用后采用前的下降趋势略有加速
因此,基于合并和非合并拉取请求的模型,我们确认 H1.1 和 H1.2。
总体而言,采用代码审查机器人后,每月合并的拉取请求更多,每月的非合并拉取请求更少。
B. Effects in Communication
平均而言,在采用代码审查机器人后,每月关于合并拉取请求的沟通较少。 但是,非合并拉取请求的每月通信不会随着时间的推移而改变。
C. Effects in Pull Request Resolution Efficiency
采用代码审查机器人后,维护人员平均需要更少的时间来审查和拒绝拉取请求。 但是,在代码审查机器人采用后,审查和接受拉取请求所需的时间不会改变。
D. Effects in Commits
采用代码审查机器人后,合并和未合并的拉取请求的拉取请求提交中位数的月度趋势不会改变。
VIII. CONCLUSION
在这项工作中,我们对采用机器人支持代码审查过程对拉取请求的影响进行了探索性实证调查。 虽然 OSS 社区已经提出并采用了几个代码审查机器人,但在评估实践状态方面所做的工作相对较少。 为了了解对实践的影响,我们对托管在 GitHub 上的 1、194 个开源项目的数据进行了统计分析。 通过围绕引入代码审查机器人对数据进行建模,我们注意到合并拉取请求和非合并拉取请求的不同结果。 我们看到,在采用代码审查机器人后,项目每月合并拉取请求的数量增加了,维护者和贡献者之间的沟通需要更少。 同时,代码审查机器人可以引导项目拒绝更少的拉取请求。 从业者和开源维护者可以使用我们的结果来了解引入代码审查机器人如何影响群体动态,设计对策以避免不良影响。 未来的工作包括对采用机器人的影响进行定性调查,以及扩展我们对其他类型的机器人、活动指标和社交编码平台的分析。

若有收获,就点个赞吧
0 人点赞
