文章地址 https://arxiv.org/abs/2106.09173
https://github.com/DynamicCodeSearch/COSAL
1. INTRODUCTION
代码到代码搜索描述了使用代码查询在存储库中搜索类似代码的任务。 由于语言之间的句法和语义差异,当查询和结果属于不同语言时,这项任务尤其具有挑战性。
- 代码迁移 C# -> C++
- 识别代码克隆
- 查找不同语言的代码翻译
- 程序修复
- 支持学生学习新的编程语言
大型在线代码存储库的日益突出和源代码的重复性 [48, 70] 导致存在大量跨语言的潜在相似代码,为代码到代码搜索提供了可行的平台。
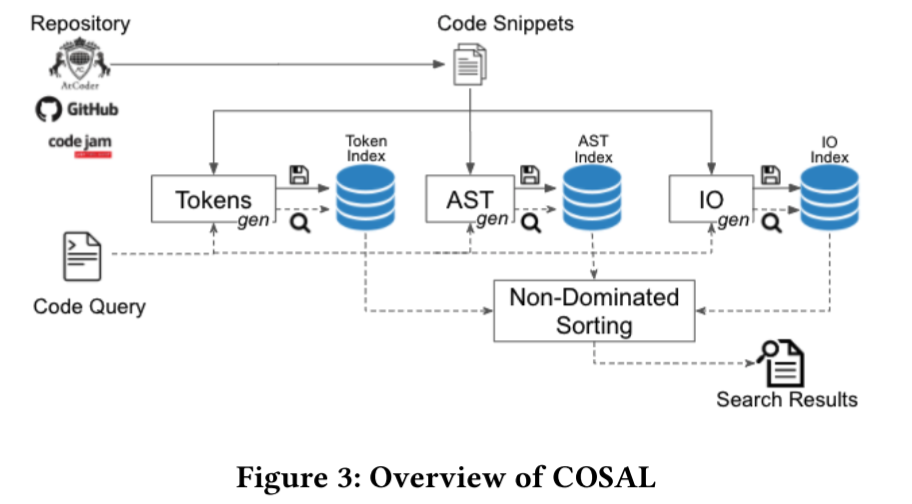
本文提出了第一种具有动态和静态相似性度量的跨语言代码到代码搜索方法。新颖之处在于将非支配排序(non-dominated sorting)[19] 应用于代码对代码搜索,允许静态和动态信息(无聚合)识别搜索结果。
- 静态分析:COSAL利用现有技术通过输入输出(IO)行为进行克隆检测[51]。
- 动态分析:使用基于令牌和基于AST的度量来补充动态分析。
数据集:
- 43,146 Java and Python files from AtCoder
- 55,499 Java files from BigCloneBench [79]
与现有方法对比:
- 代码搜索工具:FaCoY, GitHub
- 代码克隆检测:SLACC,CLCDSA
2. MOTIVATION

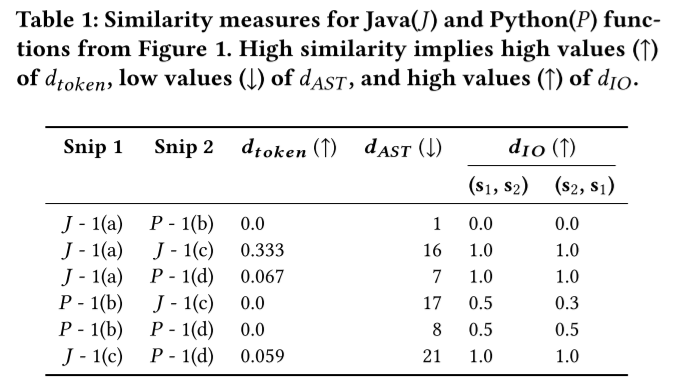
使用基于AST的方法来识别跨语言的相似代码时,1(a) 和1(b)将匹配。
使用基于IO相似性的动态方法时,1(a) 和 1(b) 将存在差异。
跨语言代码到代码搜索没有单一的最佳相似性度量。 它取决于多个不同的标准,这些标准不能适用于所有情况。 因此,我们需要一种代码到代码搜索技术,能够基于多个相似性度量进行搜索。 这可以通过将多个度量聚合为单个度量或通过串联使用所有度量来处理。
当将多个指标聚合成单一维度时,这种方法较为容易,但存在局限性。
- 如果目标之间是独立的或彼此弱相关,则对结果排名将会非常主观
- 聚合成单一维度时,细微差别将会丢失
非支配排名对跨多个独立搜索目标的搜索结果进行排序,而不将它们聚合。 我们选择了三个相似性度量来表示跨编程语言的上下文、结构和行为。 这些度量彼此之间存在弱相关和中度相关,在用于比较代码时呈现出非重叠的观点。 此外,非支配排名可以提供足够的信息来解释为什么一个结果以有意义的方式排名在另一个之上,这是聚合方法所缺乏的能力(例如,“1(a) 和 1(b) 具有更多的结构相似性”) )。 虽然我们不调查这项工作中解释的价值,但我们推测,当开发人员区分搜索结果并将其留待未来探索时,此类解释可能有用。
3. CODE-TO-CODE SEARCH ACROSS LANGUAGES
3.1 Token-based Search
上下文相似的代码片段通常使用相似的变量名称 [69]
- List java.util
- list Python builtin library
开发人员倾向于根据功能[33] 在注释中描述代码。 我们通过从源代码和注释中提取非语言特定的标记来推断上下文,如下所示
- 根据文档 [18, 60] 删除特定于语言的关键字。 例如,Java 标记 public 和 static 以及 Python 标记 def 和 assert 都被删除。
- 根据通用的编码约定,去除一种语言中的常用词。 例如,在 Python 中,标记 self 经常用于表示类对象。
- 从英语词汇表[15]中去除常见的停用词,例如does和from。
- 拆分标记以解决特定于语言的命名法。 变量在Java中通常使用camelCase,在Python中使用snake_case。 它们分别分为{“camel”和“case”}和{“snake”和“case”}。
- 删除长度小于MIN_TOK_LEN 的token。
- 将所有标记转换为小写。
使用上述方法对代码存储库进行标记并存储在 ElasticSearch [29] 索引中。 对于用户的代码查询,在搜索索引中查找索引方法生成的标记,并使用标记相似距离 ( ) 返回最佳匹配结果。 该距离与 Jaccard Coefficient [59] 相同,定义如下:
) 返回最佳匹配结果。 该距离与 Jaccard Coefficient [59] 相同,定义如下:
 %22%20aria-hidden%3D%22true%22%3E%0A%20%3Cuse%20xlink%3Ahref%3D%22%23E1-MJMATHI-64%22%20x%3D%220%22%20y%3D%220%22%3E%3C%2Fuse%3E%0A%3Cg%20transform%3D%22translate(520%2C-150)%22%3E%0A%20%3Cuse%20transform%3D%22scale(0.707)%22%20xlink%3Ahref%3D%22%23E1-MJMATHI-74%22%20x%3D%220%22%20y%3D%220%22%3E%3C%2Fuse%3E%0A%20%3Cuse%20transform%3D%22scale(0.707)%22%20xlink%3Ahref%3D%22%23E1-MJMATHI-6F%22%20x%3D%22361%22%20y%3D%220%22%3E%3C%2Fuse%3E%0A%20%3Cuse%20transform%3D%22scale(0.707)%22%20xlink%3Ahref%3D%22%23E1-MJMATHI-6B%22%20x%3D%22847%22%20y%3D%220%22%3E%3C%2Fuse%3E%0A%20%3Cuse%20transform%3D%22scale(0.707)%22%20xlink%3Ahref%3D%22%23E1-MJMATHI-65%22%20x%3D%221368%22%20y%3D%220%22%3E%3C%2Fuse%3E%0A%20%3Cuse%20transform%3D%22scale(0.707)%22%20xlink%3Ahref%3D%22%23E1-MJMATHI-6E%22%20x%3D%221835%22%20y%3D%220%22%3E%3C%2Fuse%3E%0A%3C%2Fg%3E%0A%3C%2Fg%3E%0A%3C%2Fsvg%3E#card=math&code=d_%7Btoken%7D&id=Bx10U)的范围是 [0.0, 1.0]。 𝑑𝑡𝑜𝑘𝑒𝑛 的值越大,表示查询和结果之间的相似度越高。
%22%20aria-hidden%3D%22true%22%3E%0A%20%3Cuse%20xlink%3Ahref%3D%22%23E1-MJMATHI-64%22%20x%3D%220%22%20y%3D%220%22%3E%3C%2Fuse%3E%0A%3Cg%20transform%3D%22translate(520%2C-150)%22%3E%0A%20%3Cuse%20transform%3D%22scale(0.707)%22%20xlink%3Ahref%3D%22%23E1-MJMATHI-74%22%20x%3D%220%22%20y%3D%220%22%3E%3C%2Fuse%3E%0A%20%3Cuse%20transform%3D%22scale(0.707)%22%20xlink%3Ahref%3D%22%23E1-MJMATHI-6F%22%20x%3D%22361%22%20y%3D%220%22%3E%3C%2Fuse%3E%0A%20%3Cuse%20transform%3D%22scale(0.707)%22%20xlink%3Ahref%3D%22%23E1-MJMATHI-6B%22%20x%3D%22847%22%20y%3D%220%22%3E%3C%2Fuse%3E%0A%20%3Cuse%20transform%3D%22scale(0.707)%22%20xlink%3Ahref%3D%22%23E1-MJMATHI-65%22%20x%3D%221368%22%20y%3D%220%22%3E%3C%2Fuse%3E%0A%20%3Cuse%20transform%3D%22scale(0.707)%22%20xlink%3Ahref%3D%22%23E1-MJMATHI-6E%22%20x%3D%221835%22%20y%3D%220%22%3E%3C%2Fuse%3E%0A%3C%2Fg%3E%0A%3C%2Fg%3E%0A%3C%2Fsvg%3E#card=math&code=d_%7Btoken%7D&id=Bx10U)的范围是 [0.0, 1.0]。 𝑑𝑡𝑜𝑘𝑒𝑛 的值越大,表示查询和结果之间的相似度越高。
在许多情况下,基于令牌的分析无法产生理想的结果。 它依赖于自我描述的片段; 变量名、函数名、使用的库和注释的选择都会影响结果.
并非所有代码片段都遵循直观的命名约定。 例如,在 1(c) 中,程序员选择了非常通用的名称。 尽管如此,我们在第 6.1 节中表明,与全文搜索相比,我们的标记化方法会产生更精确的结果。
3.2 AST-based Search
用于跨语言比较的基于树的表示具有挑战性,因为没有包含不同语言句法特征的通用 AST 表示。 传统的 AST 解析器,如 ANTLR [61]、JavaParser [83]、python-ast [65] 模块使用不同的语法来表示相似的特征。
例如,JavaParser 中的函数节点表示为 MethodDeclaration,而 python-ast 解析器将节点表示为 FunctionDef。 因此,要比较不同语言的 AST,需要每对编程语言之间的映射方案。 为了更好地扩展到其他编程语言,我们为通用 AST 构建了一个解析器。 通过将 Java 和 Python 的 AST 映射到通用 AST,我们可以在这些语言之间进行比较(有关可扩展性的讨论,请参见第 7.3.2 节)。 通用 AST 是基于我们的直觉和选择的语言,可能会有更有效或更高效的表示。

使用 Zhang-Sasha 算法 [90] (𝑑𝐴𝑆𝑇) 计算 AST 之间的相似性。 该算法计算在二次时间内将一个有序标记树转换为另一个有序标记树所需的最小编辑次数。 𝑑𝐴𝑆𝑇 的范围是 [0, ∞)。 𝑑𝐴𝑆𝑇 的越低,相关性越高。
3.3 Input-Output based Search
COSAL 中的动态搜索,是由基于它们的 IO 关系的聚类代码执行的。
为了确定两段代码之间的 IO 关系,我们使用 SLACC [51],这是一种公开可用的基于 IO 的跨语言代码克隆检测工具。 SLACC 将代码分割成大小大于 MIN_STMTS 的可执行片段,并在使用灰盒策略生成的 ARGS_MAX 参数上执行。 然后使用基于函数的输入和输出的相似性度量(𝑠𝑖𝑚)对执行的函数进行聚类。 考虑一个查询 𝑞 和一个潜在的搜索结果 𝑠。 令 𝑄 和 𝑆 分别是 SLACC 从𝑞 和 𝑠 中识别的段落集。 我们将 IO 相似度定义为:

值 𝑑𝐼𝑂 的范围是 [0.0, 1.0]。 较高的相似度对应于较高的 𝑑𝐼𝑂 值。
3.4 Non-Dominated Ranking
Non-Dominated Ranking 是 NSGAII [19] 的一个组成部分,对具有多个指标(不聚合)的结果进行排序。
COSAL 使用此算法根据 𝑑𝑡𝑜𝑘𝑒𝑛 、 𝑑𝐴𝑆𝑇 和 𝑑𝐼𝑂 对搜索结果进行排名。 我们注意到,这项工作中考虑的相似性度量指标是弱相关的,如第 7.2 节所述,使其成为合适的算法选择。 本文在新的上下文中使用该算法; 这是第一个使用非支配排序进行代码到代码搜索的工作。
- 单个搜索:对于一个查询,使用每个相似性度量(𝑑𝑡𝑜𝑘𝑒𝑛 , 𝑑𝐴𝑆𝑇 和 𝑑𝐼𝑂)独立获取前 TOP_N 个搜索结果。
- 合并:合并单个搜索结果,从而删除搜索结果的重复实例。
- 排序:NSGA-II [19] 通过测量一个结果对另一个结果的支配地位对合并的结果进行排序。
如果 𝑠 在任何目标上不比 𝑡 差,并且至少在一个目标上优于 𝑡,则称搜索结果 𝑠 支配搜索结果 𝑡。 在平局的情况下,我们选择具有最接近最佳值的主要目标的结果。
例如,考虑以下 𝑠 和 𝑡 之间关系的场景,以及三个假设的相似性度量,𝑑𝐴、𝑑𝐵 和 𝑑𝐶,其中较高的值意味着较高的相似性: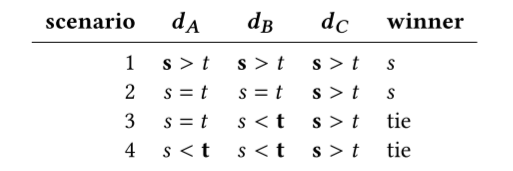
通过查看每个相似性度量更好的搜索结果,然后与最佳值(通常为 1 或 0,取决于高值还是低值表示更好的相似性)进行比较,可以打破平局。
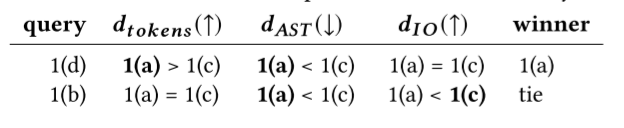
片段 𝑠 上相似性度量 (𝑋) 的归一化距离计算:
我们注意到,可以相对容易地添加表征其他代码关系的相似性度量,例如软件度量 [9, 62]。 非支配排名保留了每个目标的独立性,并且没有需要调整的权重; 见第 7.3.3 节。
4. RESEARCH QUESTIONS
RQ1:与这些搜索相似性度量的任何子集或聚合相比,使用令牌、AST 和 IO 的非支配排名是否会为跨语言代码到代码搜索产生更好的结果?
RQ2:与最新的公共代码搜索工具相比,COSAL 在跨语言代码到代码搜索中的效果如何?
RQ3:与最先进的技术相比,COSAL 在语言内代码到代码搜索中的效果如何?
RQ4:COSAL 能否有效检测跨语言代码克隆?

5. STUDY
5.1 Data
- AtCoder (AtC)
- BigCloneBench (BCB)
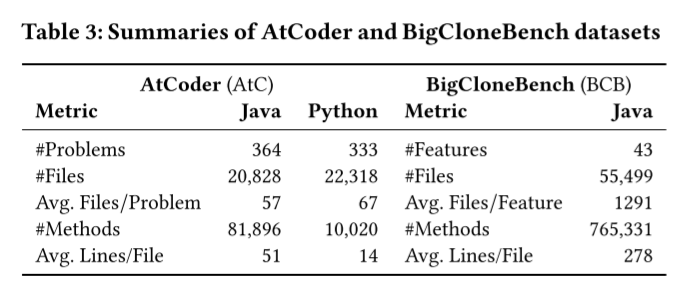
5.2 Baselines
我们通过搜索相同的数据集将 COSAL 与其他每个工具进行比较。 对于 RQ3 和 RQ4,我们使用工具的 GitHub 存储库中的源代码进行实验。
RQ2
- Text Search
- 开发人员通常使用 Google 搜索进行代码搜索 [75]。 文本查询可以采用关键字、预期代码或引发的异常的形式。 在我们的研究中,谷歌在等待六周后未能索引我们的代码库。 因此,我们转向使用 ElasticSearch [29] 的自定义全文搜索,它接收代码片段,标记代码并基于 Lucene 的实用评分引擎 [6] 识别结果。 在本研究中,每个 Java 和 Python 文件都被添加到 ElasticSearch 索引中,并使用 ElasticSearch 编程搜索 API 进行搜索。
- GitHub Search
- GitHub 搜索引擎是基于 IR 的代码存储库搜索模型,包括问题、拉取请求、文档和代码数据 [81]。 使用 GitHub 上的内置代码搜索,可以在整个 GitHub 中全局搜索代码,或者在特定存储库或组织内搜索代码。 我们将数据集中的 Java 和 Python 文件添加到单个 GitHub 存储库中,并使用 GitHub 搜索 API [80] 在存储库中进行搜索。
RQ3
- FaCoY
- FaCoY [40] 是一种基于 Java 的代码到代码搜索工具,它使用来自 StackOverflow 问答帖子的相关关键字的查询交替方法。 可以修改 FaCoY 以将其搜索数据库从问答帖子更改为自定义数据集。 在我们的实验中,我们将搜索重定向到来自 AtCoder 和 BigCloneBench 数据集的代码库。 与 FaCoY 评估中的实验类似,与研究工具进行比较时,FaCoY 在我们的基线中不使用 StackOverflow
RQ4
- ASTLearner
- Perez 和 Chiba 开发了一种半监督跨语言句法克隆检测方法,我们称之为 ASTLearner [63]。 它使用一个skip-gram模型和一个基于LSTM的编码器。 编码使用负采样来训练前馈神经网络分类器来识别克隆。 如果分类器分数大于 0.5,则 ASTLearner 将代码视为克隆
- CLCDSA
- 跨语言代码克隆检测 [56] (CLCDSA),使用语法特征和 API 文档来检测 Java、Python 和 C# 中的跨语言克隆。 从 AST 中提取了 9 个特征; API 调用相似性是使用 API 文档和 Word2Vec [54] 模型学习的。 向量化特征使用大量训练重新配置的 Siamese 架构 [8]的标记数据。 CLCDSA 使用余弦相似度检测克隆; 最好的 F1 分数是在相似性阈值为 0.5 时。
- SLACC
- 基于 Simion 的语言不可知代码克隆 [51] (SLACC),使用 IO 行为来识别克隆。 它还用于 COSAL 中的动态相似性。 在这里,我们使用 SLACC 作为其原始上下文中的基线,即克隆检测。 我们对 SLACC 的作者设置的超参数使用相同的值:MIN_STMTS 设置为 1; ARGS_MAX 设置为 256; SIM_T 设置为 1.0
5.3 Metrics

若有收获,就点个赞吧
0 人点赞
