- Abstract
- I. INTRODUCTION
- II. BACKGROUND
- III. AUTHORSHIP ANALYSIS AND SYSTEM OVERVIEW
- IV. AUTHORSHIP DECOUPLING
- V. AUTHORSHIP IDENTIFICATION
- VI. EVALUATION
- VII. THREATS TO VALIDITY
- IX. CONCLUSION
Abstract
摘要:作者身份识别是通过给定的代码对作者进行识别和分类的过程。 作者身份识别可用于广泛的软件领域,例如代码作者争议、抄袭检测、攻击者身份暴露。 除了遗留软件开发的固有挑战外,Android 中的框架编程和众包模式也大大增加了作者身份识别的难度。 更具体地说,广泛使用的第三方库和继承的组件(例如,类、方法和变量)稀释了整个 Android 应用程序中的主要代码,并模糊了不同作者编写的代码的界限。 然而,先前的研究并没有很好地解决这些挑战。 为此,我们设计了一种两阶段的方法,将 Android 应用的主要代码归属于特定的开发人员。 在第一阶段,我们提出了三种策略来识别应用程序中 Java 包之间的关系,包括上下文、语义和结构关系。 开发了一种包聚合算法来聚类所有由同一作者编写的高概率包。 在第二阶段,我们开发了三种类型的特征来捕捉作者的编码习惯和代码风格。 基于此,我们从其开发的 Android 应用程序中为作者生成指纹,并采用多种机器学习算法进行作者身份分类。 我们在三个数据集中评估我们的方法,这些数据集包含来自 257 个不同开发人员的 15,666 个应用程序,平均准确率达到 92.5%。 此外,我们在 2,900 个混淆应用程序上对其进行了测试,我们的方法可以对应用程序进行分类,准确率为 80.4%。
索引词——作者身份识别; 作者身份脱钩; 安卓应用; 封装关系图; 主要作者
I. INTRODUCTION
代码作者身份识别是一种确定特定代码的作者的通用技术。 它已广泛应用于多个领域,包括代码作者争议、抄袭检测 [1]、应用程序克隆检测 [2]、软件取证 [3] 和恶意软件分析 [4]、[5]。 以 Android 中的恶意软件分析 [6] 为例,由于自动代码生成技术 [7] 和大量可重用代码,制造和发展恶意软件的成本相对较低。 因此,当反恶意软件工具 [8]、[9] 无法有效捕获内部恶意行为时,手动分析这些恶意软件样本成为一项费力且乏味的任务。 通过作者身份识别,安全分析人员可以确定恶意软件的作者,并进一步推断所包含的恶意行为和攻击目标。
软件开发人员通常会根据可区分的编程习惯在代码中留下个人和可识别信息。 该信息是准确识别其作者的关键。 然而,由于数据集的稀缺性、不断发展的编程风格、代码混淆等原因,它非常具有挑战性[10]。 现代软件代码作者身份的研究可以追溯到 1980 年代,当时 Oman 和 Cook 使用印刷特征来区分 Pascal 程序 [11]。 随后,更多的文体特征被提取并用于作者身份识别。 源代码的词汇和句法特征,例如变量命名、布局样式和数据结构的使用,可以使代码的作者匿名化 [12]-[14]。 抽象语法树、控制流图和程序依赖图 [15]、[16] 等语义特征在作者身份识别中也很有效。 然而,由于开发模式不同,这些技术并不能完全应用于Android应用的作者归属。
Android应用是功能模块的组合,其代码由个人或团队按照开发规则编写。 因此,第一个挑战来自协作组的代码影响。 更具体地说,Android 应用程序可以团队开发,不同的模块可以由多个作者设计。 团队合作的所有遗产都冲淡了作者的编程风格。 第二个挑战是由于许多可重用的库来缓解开发难度[17]-[19]。 例如,开发人员倾向于使用广告库(例如 AdMob 和 Facebook)、社交网络(例如 Twitter 和微信)、okHttp 和 Google GSON 等开发库。 根据对 100 个 FDroid 应用的实证研究,我们发现其中只有 8% 是由开发者独立制作的,没有任何第三方库。 因此,第三方库的引入肯定会对作者身份识别产生负面影响。 最后,Android 应用程序在编译后没有完全保留源代码的词汇和句法特征,这是第三个挑战。 此外,在编译过程中使用 PROGUARD 会极大地混淆源代码。 研究 [20]、[21] 开创性地从 apk 文件中提取可识别的特征,如字符串、使用的数据结构以及方法和类的统计信息。 然而,它们都未能解决上述所有三个挑战。 因此,我们的目标是研究分段的应用程序代码而不是整个代码来解决挑战。
在这项研究中,我们提出了一种称为 A3IDENT 的两阶段方法来识别 Android 应用程序的主要作者,其中包括作者身份解耦和作者身份识别。 主要作者是一名 Android 开发人员,他主要实现了所宣传的功能模型,即主模块 [22]。 在第一阶段,我们为给定的应用程序构建一个包关系图,并根据三个假设对可能由一个作者创建的所有包进行分组(参见第 IV 节)。 我们提出语义和结构相似性来量化应用程序包之间的距离。 这些包与 Louvain 模型 [23] 进一步聚合。 通过这种方式,我们可以确定主要作者创建的主要模块并解决第一个和第二个挑战。 在第二阶段,我们提取了三种样式特征,并摆脱了Android框架和混淆带来的问题,例如重载方法、标识符规则等(参见第五节)。 对于这些提取的特征,我们使用 word2vec [24] 来嵌入作者的个人资料。 最后,我们使用三种机器学习模型(即线性 SVM [25]、随机森林 [26] 和逻辑回归 [27])来确定测试应用程序的可能作者。 A3IDENT 在四个数据集上进行了广泛评估:F-Droid、良性软件、恶意软件和混淆应用程序。 实验结果表明,A3IDENT 的准确率分别达到了 96%、98.9%、82.7% 和 80.4%。 通过比较开源作者归属工具 APPAUTH [2],我们的方法在作者身份识别方面提高了 3.4%,准确度为 87.8%。 此外,我们确定了四种在应用程序开发和编译期间与主要代码混合的外部代码。 混淆应用程序的实验证明,我们的方法在针对混淆的作者身份识别方面保持了很高的准确性
贡献。 我们做出了以下贡献。
- 我们建议在 package 的粒度上进行作者身份解耦,以根据作者对相关代码进行分组,这在之前的 Android 研究中从未考虑过。 基于此,我们发现在编译过程中,apk文件中已经集成了几个类,例如配置类和第三方库。
- 对于作者身份识别,我们从主模块中提取了三种类型的特征,即 dex-level, lib-level, and manifest-level特征。 不同的是,我们消除了Android框架特征提取的影响,结合TF-IDF和word2vec技术来嵌入特征。 然后使用三个分类器来识别作者身份。
- 我们实现了一个自动化工具 A3IDENT,该工具在 257 位作者及其 15,666 个应用程序中进行了广泛评估。 作者身份解耦在 416 个 F-Droid 应用上达到 96.11% 的准确率,作者身份识别在整个集合上平均达到 92.5% 的准确率。 事实证明,我们的方法在处理混淆应用方面也很有效,准确率仅降低了 7.2%。
II. BACKGROUND
A. Android app Authorship
Android 开发人员将他们的源代码和其他资源文件(例如布局文件)编译成 Android 应用程序包 (APK) 并将其交付到 Android 平台。 一个apk文件包含AndroidManifest.xml、.dex、.arsc、res目录、META-INF目录等。需要开发者使用自己的证书对Android应用进行签名。 签名证书存储在“META-INF”文件夹中。 Android 签名保证应用程序的完整性并防止篡改和替换。 除了证书在 AOSP [28] 发布的 Android 源代码中暴露并且私钥以某种方式泄露 [29] 外,开发人员的证书是机密的,不能被其他人知道 [30]。 因此,使用相同证书签名的应用程序应该由同一开发人员创建。 作者身份识别研究源于文学领域,旨在根据作者独特的语言风格(如动词、词汇、句子长度)来识别有争议的文本的作者。 它在Android领域也非常重要。 例如,作者身份识别可以帮助确认对手在零日攻击或野外变体背后的身份。 通常,它会引出一组特征作为指纹来量化恶意软件作者的风格(例如,编程风格和命名约定)。 与其他软件系统不同,一个 apk 文件很可能由来自不同作者和编译的多段代码组成。 因此,我们必须将主要代码与外部代码分开。
B. Louvain model
Louvain 模型是一种基于多级模块化优化的图聚类算法,用于从大型网络中识别社区,我们将其用于作者身份解耦(参见第 IV-C 节)。 节点和节点之间的权重作为输入,Louvain 模型输出每个节点所属的集群。 给定一个加权图,它的目标是最大化由 Q 引导的模块化,如下 [23]: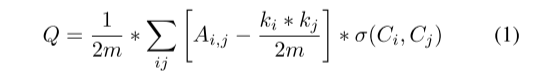
其中Q表示当前的模块化状态,Aij表示节点i和节点j之间的权重,ki表示与节点i相连的所有边的加权和,Ci是节点i的簇数,σ(Ci,Cj)表示 如果节点 i 和 j 在同一个簇中,则值为 1,否则值为 0。首先将每个节点视为一个独立的类别,Louvain 算法分为两步:
Step 1 遍历图的所有节点,将相似的节点归为一组,并进行标注,直到所有节点的集群不变。
Step 2 重新初始化图并将同一集群中的节点合并为超级节点。 超级节点包含一条自连接边,其权重是原始边中所有边的权重总和的两倍。 超级节点之间的权重是其连接节点位于不同簇的边的权重之和。 然后,重复第一步,直到模块化 Q 不变。
III. AUTHORSHIP ANALYSIS AND SYSTEM OVERVIEW
A. Component Analysis
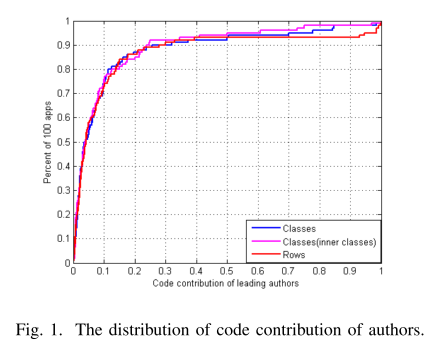
大量应用程序具有结构复杂性,分析 apk 的所有代码以进行作者归属是不现实的。 此外,由于是多模块开发,应用程序中的代码可能归属于个人或团队合作。 每个团队开发自己的模块代码,模块之间的耦合性差,模块内的聚合度高。 更糟糕的是,据观察作者编写的代码比例很小。 如图 1 所示,在从 FDroid 中随机抽取的 100 个应用程序中,该比例在大约 90% 的应用程序中不到 30%。 由于一些限制,LIBSCOUT [17] 和 LIBD [18] 只能从应用程序中检测到第三方库的子集。 因此,将混合代码归类到特定作者并非易事。 先前的研究 [20]、[21] 未能在他们的方法中考虑这种现象,尽管它们也取得了很好的效果
受上述原因的推动,我们的目标是开发一种新的作者身份识别方法。 在作者身份识别之前,我们为所分析的应用程序建立包之间的关联,并将包划分为独立的模块。 在这些模块中,有一个模块包含MainActivity,可以通过查询AndroidManifet.xml轻松识别。 MainActivity作为Activity的入口,是Android App的核心类,通过函数调用、ICC等方式实现主要功能。因此,根据[22],该Activity所在的模块被视为Primary 由主要作者设计的模块,可用于作者身份识别。
B. System Overview
我们提出了一个具有两个主要阶段的框架 A3IDENT,以识别给定应用程序的主要模块,并生成与作者编程风格有关的表示,以进行作者归属。 图 2 展示了我们模型的概述。 给定一个应用程序,它按如下方式进行:
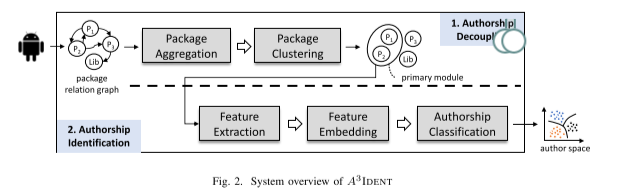
Authorship decoupling 我们将 Java packages 视为分析单元,并将它们划分为每个应用程序的不同模块。 我们根据调用关系、继承关系和 ICC 连接为给定应用创建包关系图。 我们使用包聚合对作者创建的所有包进行分组,并设计语义和结构相似性来计算每对包的权重。 最后,我们利用 Louvain 模型和包之间的关联权重将包划分为模块。 主模块可以根据MainActivity所在的位置来确定
Authorship identification 我们从应用程序的主要模块中提取三种类型的特征,并利用 TF-IDF 算法来识别这些特征的重要序列。 然后,我们基于 word2vec 模型形成特征向量,并选择三个机器学习模型作为监督分类器来预测潜在作者
Granularity of package.
在这项研究中,我们将包而不是类作为模块的原子单元,因为同一包下的类,尤其是具有多个级别的类,很可能是由同一作者编写的。 为了证明这一假设,我们从 F-Droid 数据集中提取了 100 个作者,并从每个作者中随机选择了一个应用程序。 然后,根据第四节的方法,进行作者身份与类粒度和包粒度的解耦。 表 I 显示了比较结果,可以看出作者身份在包粒度上的解耦比在类粒度下实现了更高的召回率、准确率和 F1 分数。 此外,它的成本仅为四分之一。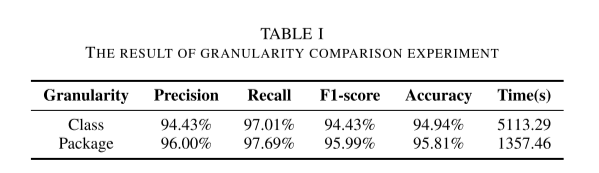
IV. AUTHORSHIP DECOUPLING
一个 Android 应用程序由几个功能独立的模块组成 [22]。 同样,该应用程序经常集成来自多个开发人员 [10]、[31] 的各种代码,包括第三方库、Android SDK 的完整性和重新打包的代码。 因此,我们提出作者身份解耦,将部分代码归属于特定的开发者。
A. Package Relation Graph
与功能解耦不同,作者身份解耦根据作者而不是功能来集群代码。 由于一位作者可以开发几个函数之间可能没有明确的语义关系(例如,调用关系),因此我们提出了几种粗粒度策略来区分不同作者开发的代码。 在不失一般性的情况下,我们提出了一个包关系图来表示一个 Android 应用程序,如下所示。
Definition 1:Android 应用可以表示为一个加权有向多图 G = (V, E, φ),其中 V 是应用中的包集,E 是 V 之间的边集,φ 是作者函数 φ(u) 代表包 u 的作者。
在图 G 中,我们使用一条边 e,其中 e = (u, v)∧u, v ∈ V,来表示两个包之间的语义关系。 这里我们考虑三种语义关系:调用关系。 如果从包 u 中的一个构造(例如,方法或变量)调用到包 v 中的另一个方法或变量,我们认为 u 和 v 之间存在调用关系; 继承关系。 如果 u 包中的一个类继承自 v 包中的另一个类,则说明 u 和 v 具有继承关系; 如果 u 中的一个组件类与 v 中的另一个类具有组件间通信,则 ICC 连接揭示了两个包 u 和 v 之间的一种连接类型。
B. Package Aggregation
为了对同一作者创建的所有包进行分组,我们在考虑应用程序开发时做出三个假设。 首先,在已知的第三方库中定义的包被认为归一个作者所有。 这是合理的,因为第三方库是由单个组织开发的,应该与应用程序中的主要模块分开。 其次,AndroidManifest 中定义的组件可能与一位作者有关。 AndroidManifest 定义了有关应用程序的所有基本信息,其中组件是用于底层应用程序功能的 Activity、Service、Broadcast Receiver 和 Content Provider。 因此,这些组件是由同一作者创建的可能性很大。 我们调查了数据集 F-Droid 中的 100 个应用程序,发现 89% 的应用程序在同一模块中具有组件。 第三,圆圈中的顶点可能是由一个作者创建的[32]。 一个应用程序中的作者拥有不对称的知识,因为第三方库的调用者知道库暴露的所有接口,但是,被调用者根本不知道调用者的接口。 因此,如果顶点 u 和 v 之间存在双向关系(即 u 和 v 在一个圆圈中),则很可能 u 和 v 是由同一作者创建的。 我们以一个名为“MinCal Widget”的应用程序为例。 它的包结构如图3所示。我们过滤掉第三方包“Landroid/”和“Landroidx/”,并用剩下的包生成一个有向图G。 那么,AndroidManifest 中声明的组件属于同一作者。 这个应用程序的所有组件都位于包“minimalcalendarwidget”和“activity”中,因此这两个包属于同一作者。 然后,我们寻找圈子,发现包“minimalcalendarwidget”、“activity”、“external”、“receiver”、“service”在同一个圈子里。 因此,这四个包是由同一作者生成的。
基于上述假设,我们执行一个算法(如算法 1)来聚合同一作者的包。
(第 1-2 行)一开始,我们为每个包分配一个唯一的 id 作为可区分的作者。
(第 3 行)我们识别此应用程序中包含的所有库,
(第 4-6 行)并处理同一作者中的库。
我们检索 AndroidManifest 中定义的所有组件,并从第 7 行到第 9 行为这些包重新分配相同的作者 ID。然后我们利用深度优先搜索算法在第 10-11 行找到图 G 中的所有圆圈 . 更具体地说,对于传递给函数 DFS CIRCLE DETECT 的最后一个节点 vn,我们遍历所有出边以检查是否有回溯边到以前访问过的节点。 如果找到,则检测到一个圆圈(第 14 行),我们确定一个圆圈中的所有包都是由同一作者创建的。 否则,在第 18 行执行递归过程。最后,为应用程序更新 φ。

C. Package Clustering
在前面的步骤中找到了部分相同作者的包。 但是仍然有一些包不能与假设粘在一起。 因此,我们在本节中对包进行聚类以应对其余部分。 为此,我们为图中的包裹之间的距离开发了两个权重。
Semantic Distance
由于两个包之间存在三种语义(即调用关系、继承关系和ICC连接)。 给定一条边 (u, v) ∧ φ(u) = φ(v),我们分别使用 nc_uv、nh_uv 和 ni_uv 来表示调用次数、继承情况和 ICC 链接。 因此,语义距离可以计算为: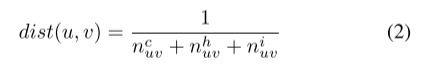
注意,dist(u, v) 被分配了 u 和 v 之间的最大值。对于关系图,我们使用 Floyd 算法 [33] 计算每两个包之间的最短路径,然后更新 dist(u, v) 与他们的弗洛伊德距离。 基于此,我们提出以下来表示 u 和 v 之间的相关性。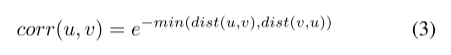
corr(u, v)的值越大,说明包u和包v的相关性越大。
Structural Distance
包结构也有助于作者身份解耦。 如图3所示,有两个包“cat.mvmike.minimalcalendarwidget.external”和“cat.mvmike.minimalcalendarwidget.status”。 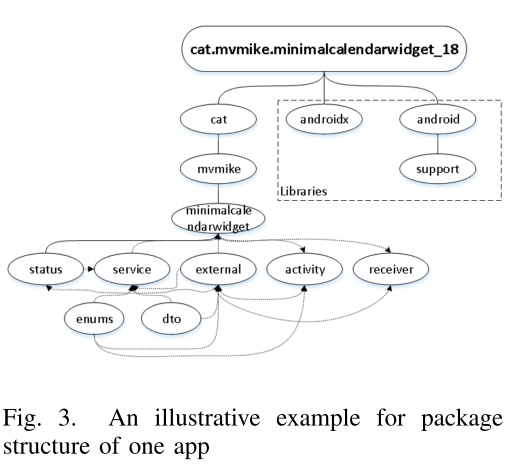
考虑到它们名字的长共同前缀,它们很可能是由同一作者创建的。 因此,我们提出了作者身份解耦的结构特征。 我们根据每两个包之间的最近共同父 (NCP) 计算结构相似性。 给定两个包 u 和 v,它们的结构相似性可以计算为: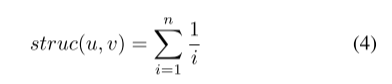
其中 n 是包 u 和 v 的 NCP 的深度。应用名称定义为根节点,其深度为 1。 注意,如果 u 是 v 的父级,则 u 和 v 的 NCP 是 u。
根据语义和结构的相似性,我们计算包 u 和 v 属于同一作者的归一化概率为: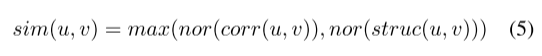
其中 nor(.) 是通过 Min-Max Feature Scaling 实现的归一化函数。 包之间的关联程度可以通过 sim(u, v) 计算。 为了评估其有效性,我们提出了另一种组合方法 α corr + (1 -α) struc,其中 α 表示两个相似性的比例。 我们从数据集 F-Droid 中随机选择了 100 个应用程序,并分别测量了作者身份解耦的准确性。 比较结果如图4所示,可以看出使用这些指标的最大值比参数化效果更好。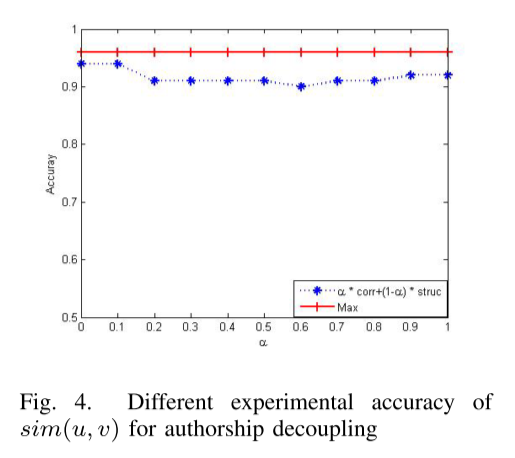
至此,我们得到了给定应用程序中包之间的相关权重。 给定两个包 u 和 v,如果 φ(v) = φ(u),则 u 和 v 之间的权重为 1,否则,u 和 v 之间的权重为 sim(u, v) 的值。 然后,我们使用 Louvain [23] 模型来表示应用程序中包之间的紧密度,并将包划分为不同的集群。 Louvain 将包裹及其相关权重作为输入,输出每个包裹所属的模块。 之后,我们选择activity所在的主模块作为主要作者设计的模块,然后识别主模块的代码作者身份。
V. AUTHORSHIP IDENTIFICATION
在本节中,我们利用作者独特的写作风格从一组候选人中识别出最有可能成为特定工件的作者。 我们描述了如何提取特征、嵌入特征和进行预测。
A. Feature Extraction
特征提取是作者身份识别的关键部分,其目标是提取具有作者独特写作风格的特征。 代替传统的代码作者归属,我们不应该只从 .dex 文件中提取特征并考虑其他资源文件,例如 AndroidManifest.xml。 请注意,我们仅从第 IV 节中确定的主要模块中提取源代码特征,并排除 Android API 的影响。 为了更好地体现特征作为指纹的特征,我们分析的特征描述如下:
Dex-level features
.dex 文件包含一个应用程序的所有 Java/Kotlin 代码,我们提取了三种类型的字符串特征:标识符名称,包括类名、方法名和字段名。 为了消除Android框架的影响,我们不考虑重载方法,onCreate和onPause; 指令序列,这就是作者编写代码来实现其功能的方式。 值得一提的是,这是文字序列,而不是控制流图中的序列,因为它们保留了作者的编程习惯; Android API 的使用,在一定程度上揭示了作者对 Android 开发的熟悉程度和偏好。 例如,要建立 HTTP 连接,作者可以使用 Apache 提供的 HttpURLConnection 或 Apache HttpClient。
Manifest-level features
每个应用程序都包含一个 AndroidManifest.xml 文件,该文件定义了包名、组件、权限等。不同的组件用于不同的用途。 uses-feature 在运行时声明外部硬件或软件功能。 这些配置与应用程序的功能相关,作者在发布相同类型的应用程序时倾向于重复使用相同的设置。 因此,每个组件的命名都与作者的命名规则和提供的功能有关。 在这里,我们从 AndroidManifest.xml 中提取活动、提供者、服务、广播接收器和使用功能的名称。
Lib-level features
第三方库需要在运行时执行附加功能。 通常,所需功能有几个候选者。 例如,开发人员可以集成 AdMob 或 Unity Ads 来做广告,也可以集成 Google Analytics 或 Crashlytics 来诊断应用程序的崩溃。 第三方库的选择可以揭示应用作者的习惯和个性。
表二总结了用于作者身份识别的特征。 这些特征包含大量噪声,不适合分析大型数据集。 因此,我们使用 TFIDFVectorizer [34] 从字符串特征中提取词级字符串的关键序列。 TFIDFVectorizer 从三个来源构造 ngram 特征,即 API 调用、标识符名称和指令。 在dex级别的特征提取过程中,我们依次提取这三个特征,并用它来生成高频序列进行向量化。 然后我们为 TFIDFVectorizer 调整适当的超参数。 我们将最大特征设置为 50,最小 df 设置为 3,n-gram 范围从 3 到 5。这提供了准确性和处理时间之间的最佳折衷。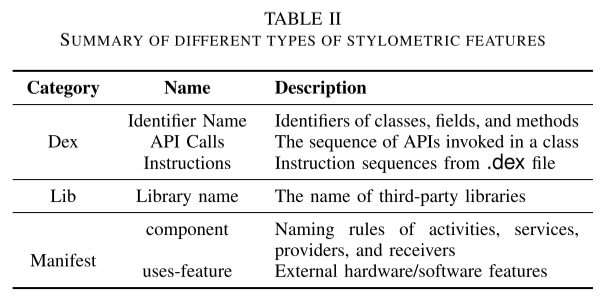
B. Feature Embedding
A3IDENT 使用 word2vec 模型来处理提取特征的文本向量化。 word2vec作为一种分布式表示,通过文本学习使用低维密集向量来表示词的语义信息,是衡量词之间相似度的一个很好的度量。 为了验证其有效性,我们在实验结果上比较了 CountVectorizer [34]、TFIDFVectorizer 和 word2vec 的准确性。 这三种方法是文本向量化的常用方法。 其中,CountVectorizer将单词转换成词频向量,然后统计每个单词出现的次数。 TFIDFVectorizer 将文本转换为 tf-idf 特征向量。 图 5 显示了这三种嵌入式技术的结果。 在本实验中,我们选择了 F-Droid、良性软件和 2,900 个恶意软件应用程序作为数据集,并提取了相同数量的 top-k 特征。 我们发现 word2vec 的性能比其他两种方法高一点。 因此,我们在本研究中选择 word2vec 进行特征嵌入。 最后,为了提高预测的准确性,我们将windows设置为3,min count为10,并将特征向量的最大列数设置为1000。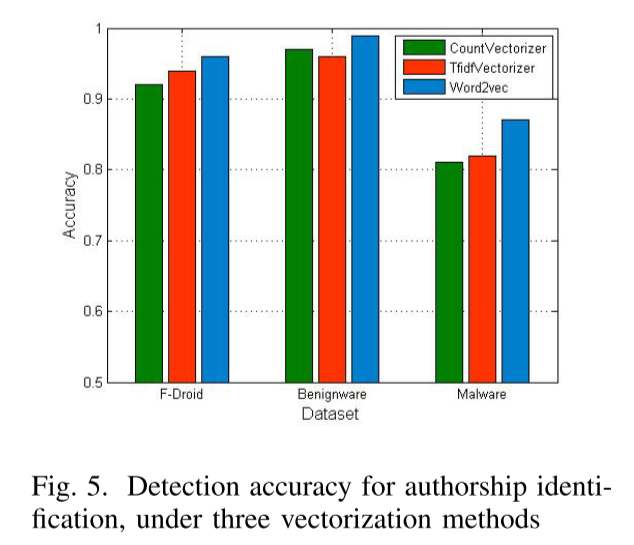
C. Authorship Classification
生成的开发者指纹用于作者预测。 前一阶段生成的特征向量作为输入数据,作者归属问题被视为监督学习分类问题,将未知的应用分类给对应的开发者。 作为比较,我们还为我们的分类任务研究并构建了三个典型的监督加工学习模型,并评估了它们的有效性。 由于我们的问题是典型的多分类问题,我们选择支持向量机(Linear SVM)、随机森林和逻辑回归来衡量每个机器学习分类器的性能。
VI. EVALUATION
在本节中,我们首先提出四个研究问题来回答,然后介绍实验设置。 我们旨在解决以下问题:
- RQ1. How effective is authorship decoupling, and what extraessential code resides in an apk file (see Section VI-B)?
- RQ2. How effective of A3IDENT in authorship identification, and what is the improvement by authorship decoupling (see Section VI-C)?
- RQ3. How resilient is A3IDENT to obfuscation (see Section VI-D)?
- RQ4. Compared with APPAUTH, how effective is A3IDENT in identifying the author of a given app (see Sec-tion VI-E)?
A. Experimental Setup
Dataset
为了评估我们的方法,我们从各种来源收集了总共 32,968 个 Android 应用程序,如表 III 所示。 以下描述了我们如何收集这些应用程序: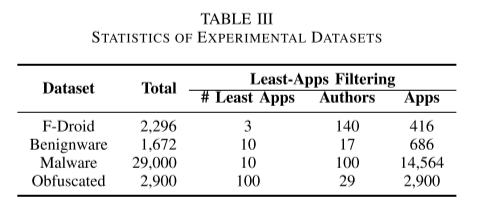
F-Droid 它是免费 Android 应用程序的开源存储库 [35]。 迄今为止,F-Droid 维护了数千个应用程序及其源代码。 我们通过其 API 总共获得了 2,296 个带有源代码的应用程序。
Benignware. 我们从 ANVA [36] 获得了 1,672 个列入白名单的应用程序。 ANVA 是一个行业联盟,负责监控、检测和响应网络威胁。 每年,它都会发布一份经过 11 家专业安全评估机构全面审查的 Android 应用程序白名单。
Malware 我们从外界(包括 Google Play [37]、ApkPure [38]、Anzhi [39] 等)收集了 29,000 个被 VIRUSTOTAL [40] 标记为恶意软件的 Android 应用程序。
Obfuscated Apps 我们选择了一些恶意软件样本,并通过 PROGUARD [41] 对每个作者的 10% 作为测试集进行混淆。 PROGUARD 用于字符串混淆和代码收缩。 该数据集用于评估我们的方法对混淆的弹性。
由于并非所有作者都创建了大量的应用程序(其中一些人只创建了一个应用程序),这增加了识别他们的编程风格的难度。 因此,我们采用最少应用程序策略,仅保留拥有至少 n 个应用程序的作者。 考虑到一位作者拥有的应用数量相对较低,我们将 F-Droid 数据集的 n 设置为 3。 对于其他三个数据集,n 设置为 10。此外,为了进行更准确的评估,我们丢弃了 8,691 个由公共证书 [30] 签名的应用程序,并在多个市场上发布了重复的应用程序。 因此,我们从 164 位作者那里获得 492 个应用程序用于数据集 F-Droid,从 17 位作者那里获得 686 个应用程序用于数据集 Benignware,从 100 位作者那里获得 14,564 个应用程序用于数据集恶意软件。 通过对 2,900 个恶意软件应用程序进行抽样创建混淆应用程序,每个作者包含 100 个应用程序
Implementation
我们在几个最先进的工具之上实施 A3IDENT。 Android应用的反编译主要依赖ANDROGUARD,用于提取作者特征、调用关系和继承关系。 ICC 连接是通过 IC3-DIALDROID [42] 提取的,我们将连接从 Java 类重新分配到它们所属的包中。 通过在 Python 库 SKLEARN [43] 和 GENSIM [44] 之上构建应用程序来完成分类任务。 所有评估实验均在 8 核 i7 Intel CPU 和 12GB RAM 的环境中进行。
Model configuration and metrics
对于不同的研究任务,我们根据 [45] 使用精度、召回率、F1 分数和准确率作为比较指标。 从 RQ2 到 RQ4,我们根据证书对作者进行分组并生成真实结果。 我们使用 A3IDENT 来生成预测结果。 我们使用 90% 的数据作为训练集,剩下的 10% 作为测试集。 对于每个实验,我们进行 10 倍交叉验证。
B. Authorship Decoupling Evaluation (RQ1)
由于 apk 文件包含来自一个或多个作者的代码,我们提出了一种作者身份解耦技术来区分主要代码与其他代码。 为了评估其有效性,我们首先从数据集 F-Droid 构建基本事实,然后检查我们的方法如何准确地解耦代码的作者身份。
Building the ground truth
由于 F-Droid 托管了数千个免费的 Android 应用程序和相应的源代码,我们检索源代码中的文件以建立作者身份解耦评估的基本事实。 实际上,给定应用程序的所有类都分为两部分,即主要作者生成的主要模块和包含其余类的非主要模块。
Step 1 我们首先使用 ANDROGUARD 反编译一个 APK 文件以获取其类和 MainActivity。 请注意,我们不考虑内部类,例如 Test$1.class。
Step 2 我们利用“settings.gradle”来确定MainActivity所在的主模块,然后我们得到主模块中包含的类。 在 Android 项目中,settings.gradle 是子项目的配置文件,其目标是管理多个模块。 每个模块名称对应于它的根目录。 我们可以遍历所有 .java 和 .kt 文件以确定它们属于哪个模块。
Step 3 最后,我们将未出现在主模块中的类分类为非主模块。 此外,我们检查是否有任何类未编译到 .dex 文件类中。 这是合理的,因为一些测试代码已保留在已发布的源代码中,这可能会对我们的基本事实的可靠性产生负面影响。
基于上述方法,我们构建了 416 个 F-Droid 应用的 ground truth,用于作者身份解耦。
Result analysis
在作者身份解耦之后,我们得到了主要的模块和它包含的类。 其余的类被合并到非主模块中。 因此,它可以被视为给定应用程序的二元分类。 我们使用指标(例如精度)来评估每个应用程序的包解耦性能,然后计算所有应用程序的平均值作为平均指标。 此外,我们重新实现了 PIGGYAPP [22],它提供了一种基于类继承、方法调用等的模块解耦方法。比较结果如表 IV 所示。 与 PIGGYAPP 相比,我们的模型得到了更好的结果,例如准确率提高了 14.93%,F1-score 提高了 18.93%。 改进源于本研究中采用的更高质量的特征,特别是结构和语义的相似性。 这些特性在模块解耦中被证明是有效的。 除了作者归属,作者解耦还可用于代码抄袭、功能分类和应用版本检测,同时减少噪声干扰。
另外,在排除内部类干扰的前提下,我们对比了源码和apk文件中同一个包的类,注意APK包的类并不都存在于源码中。 这些类来自以下四个来源:
Auto generation 在编译期间,Android 应用会自动生成类 R、BR 和 BuildConfig。 文件 R 和 BR 记录了资源信息。 BuildConfig 文件记录了 build.gradle 的配置信息。
Lambda expression Java 8 引入了 Lambda 表达式,这是一种表示行为的紧凑方式。 它的使用减少了模板代码,使数据流处理逻辑清晰。 这些生成的 .class 文件在 apk 文件中找到,但在源代码中不存在。 例如,在分析应用程序“app.fedilab.nitterizeme 9”时,我们发现了一系列类似“Lapp/fedilab/lite/helper/-$$Lambda…”的类
Classes generated by the author instructions 编写代码时,开发者可以在语句中定义一个新的类或从互联网上传类到指定的包,例如new STTFragment()。 这些文件可能与开发人员无关
Different modules with the same package 同一个包可能包含不同的模块类。 以应用程序“com.termoneplus 324”为例,它包含三个模块——samples、term和libtermexec。 但是,模块 term 和 libtermexec 具有相同的包“Lcom/termoneplus”。 当Android工程编译成APK时,这两个模块的包下的类虽然不属于同一个模块,但会被打包到同一个包中。
图 6 描绘了上述四种原因的比例。 作者指令生成的类是作者身份解耦错误的最重要因素,占 64%。 在未来的研究中,我们应该消除这四个类别对作者身份识别的噪声影响。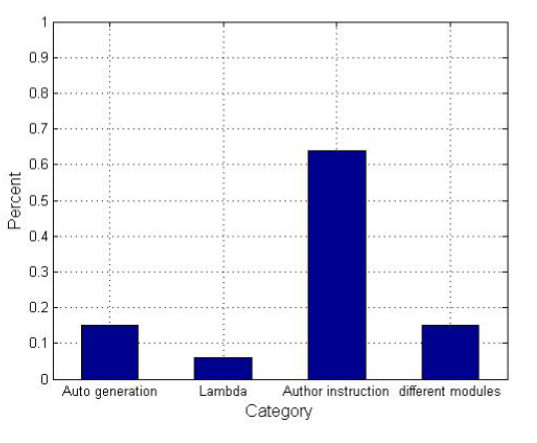
C. Authorship Identification Evaluation (RQ2)
在本节中,我们评估 A3IDENT 在识别特定代码段的作者方面是否有效。
Result Analysis
我们使用 F-Droid、良性软件和恶意软件数据集来评估作者身份识别的准确性。 如表 V 所示,对于这三个数据集,我们得到的准确率分别约为 96%、98.9%、82.7%。 总体而言,我们的模型在作者身份识别方面提供了高精度结果。 我们还比较了三种监督机器学习模型在作者身份识别中的表现。 我们发现三个分类器的准确率是相似的。 线性 SVM 在平均准确率方面取得了微弱的领先优势,但运行时间比其他两个分类器要长得多。 随机森林和逻辑回归在运行时间和有效性方面更适合我们的模型。 此外,在查看数据集 F-Droid 中应用程序的包名称和版本时,我们注意到结果更像是检测同一应用程序的不同版本。 相当高的准确性使 A3IDENT 能够有效地检测高度相似的代码,例如抄袭检测。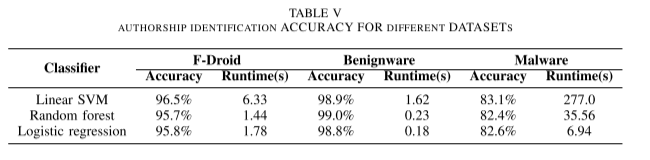
为了更全面地评估模型,我们选择随机森林来比较基于主模块和整个 apk 的作者身份识别性能(没有作者身份解耦)。 表VI描述了比较的结果。 A3IDENT 对数据集 F-Droid、良性软件和恶意软件样本的准确率分别为 95.7%、99.0% 和 87.4%。 据观察,作者身份解耦使数据集 F-Droid 的准确度提高了 4.6%,但对良性软件和 2,900 个恶意软件样本仅提高了 1.2% 和 1.4%。 相似的准确性可能归因于同一作者为一个模块创建了许多应用程序,而没有第三方库。 此外,结果也可能是由于应用程序之间的代码克隆造成的。 我们调查了 10 位创建至少 10 个应用程序的作者,发现 12% 的应用程序具有相似的代码结构。 此外,我们进一步评估了作者数量对作者身份识别的影响。 为此,我们使用了包含 29 位作者的混淆数据集。 每个作者拥有相同数量的应用,这排除了不同作者拥有不同数量的应用对结果的干扰。 实验结果如图7所示。我们发现作者身份的准确性随着作者数量的增加而略有下降。 总体而言,准确性没有显着变化。 这个结果表明我们的模型不受作者数量的干扰,具有很强的稳定性。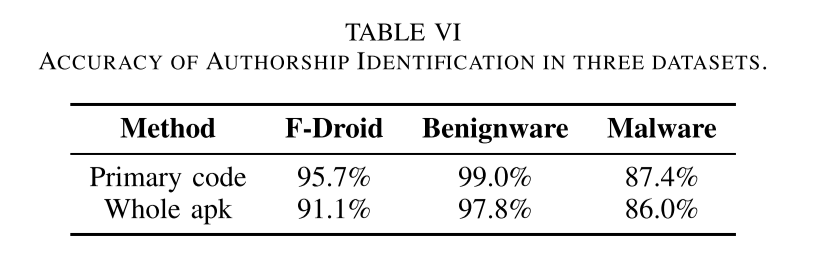
D. Obfuscation-resilient Analysis (RQ3)
在本节中,我们评估 A3IDENT 是否能够抵御 Android 应用程序中的混淆。 考虑到有效性和运行时间,我们选择随机森林对混淆数据集进行对比实验。 对于这个数据集,我们随机选择 90% 作为训练集,剩下的 10% 作为每个作者的测试集。 对于测试集,我们使用 PROGUARD 来混淆应用程序。 PROGUARD 可以通过三个步骤来混淆 Android 应用程序。 最初,删除未使用的代码(例如,未使用的方法和变量)以缩小代码的大小。 然后,执行 Java 字节码优化。 最后,它执行名称混淆,即通过将变量、类和方法重命名为简短、随机、无意义的词来混淆代码。 请注意,我们不会对 Android API 进行混淆处理。 混淆后,我们将混淆后的应用程序和它们的非混淆应用程序分别作为测试集,并测量由此产生的作者身份识别准确性。
Result analysis.
表七显示了混淆和非混淆测试集的实验结果,准确率分别为 87.6% 和 80.4%。 与非混淆应用程序相比,混淆应用程序的准确性略有下降,但不显着。 那是因为清单级别的功能没有被混淆。 此外,我们调查了五个应用程序及其混淆应用程序。 我们比较了每对应用程序的指令序列,发现它们受代码混淆的影响较小。 结果表明,A3IDENT 对代码混淆具有一定的抵抗力。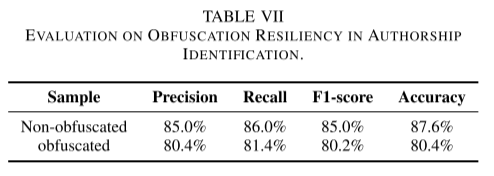
E. Comparison with APPAUTH (RQ4)
为了更全面地验证 A3IDENT 的性能,我们在作者归属方面将其与 APPAUTH 进行了比较。 APPAUTH 是一个安卓作者身份检测器和一种基于学习的新颖方法,用于预测应用程序克隆的作者身份。 我们选择一个包含 2,900 个非混淆应用程序的数据集,然后依次使用这两个工具。 表 VIII 显示了 APPAUTH 和 A3IDENT 的性能。 与 APPAUTH 相比,我们的方法在识别方面提高了 3.4%,准确率为 87.8%。 因此,我们的两阶段方法在 Android 作者归属中被证明是有效的。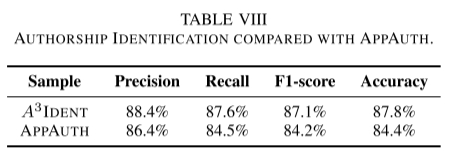
VII. THREATS TO VALIDITY
IX. CONCLUSION
在本文中,我们提出了 A3IDENT 方法,该方法包括两个步骤来进行作者归属。 首先,我们通过将包关系图和集群包构建到不同的模块中来进行作者身份解耦。 以这种方式,主模块可以进一步由入口点活动所在的位置确定。 在作者身份识别过程中,我们提炼了三类特征,保留了应用作者的风格特征,同时去除了 Android 框架的印记。 使用嵌入算法和三种类型的机器学习算法来识别给定应用程序的主要作者。 我们的方法已经在四个数据集中进行了评估,结果表明 A3IDENT 可以有效地识别作者身份,线性 SVM 的平均准确率为 92.8%,随机森林的平均准确率为 92.4%,逻辑回归的平均准确率为 92.4%。 它还证明 A3IDENT 在混淆代码上仍然有效。 与开源作者归属工具相比,我们的方法使作者身份识别的准确性提高了 3.4%。

若有收获,就点个赞吧
0 人点赞
