背景
软件开发过程中及时修复错误至关重要,确定错误的优先级并将其分配给正确的开发人员,也称为“错误分类”。
- 例如,客户服务团队发现错误时,他们会提交包含错误摘要和描述的错误报告,并将错误分配给相关的软件组件或开发人员。 该过程耗时且容易出错。 错误通常需要几天甚至几周才能到达合适的开发人员
本文提出了一种机器学习解决方案,为减轻人为负担并加快错误分类过程。
方法论
- 预处理错误描述。
- 从处理后的文本中提取特征。
- 使用基于提取的特征向量的深度神经网络 (DNN) 进行学习/分类。
实验与评估设计
数据集
数据集A:时间跨度为12年的 71,829 个错误报告。报告包含 错误描述,项目组件 字段
数据集B: 时间跨度为5 年的 30,662 个 JIRA 错误报告。报告包含 错误描述,项目组件,开发人员 字段
其他研究工作中收集的数据集,包含错误描述,开发人员两个字段。
- “JDT”数据包含 1,465 个错误报告
- “Platform”数据包含 4,825 个错误报告;
- “Firefox”数据包含 13,667 个错误报告。
S.-R. Lee, M.-J. Heo, C.-G. Lee, M. Kim, and G. Jeong, Applying deep learning based automatic bug triager to industrial projects, ESEC-FSE, 2017
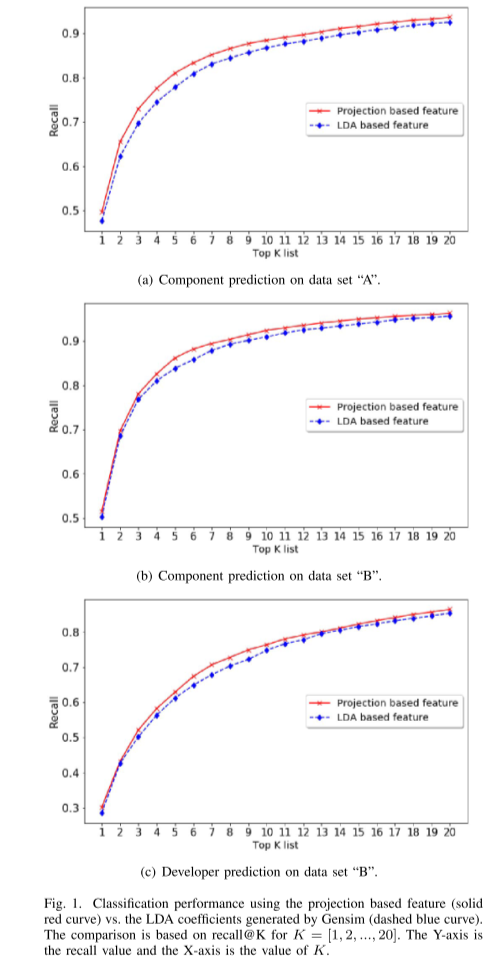
- 相对于基准(使用标准 LDA 系数),性能数字分别提高了 6%、2% 和 5%。
- 直接预测开发人员不如预测工业环境中的组件可靠。

若有收获,就点个赞吧
0 人点赞
