MSR 2017 RefDiff: Detecting Refactorings in Version Histories
1. 背景
重构是一种众所周知的技术,可以改进系统的设计并实现其演进。 因此,了解代码更改中的重构活动是帮助研究人员了解软件演化的宝贵信息。
尽管存在能够自动检测重构的方法,但仍然存在一些阻碍其应用的问题。 具体而言,此类方法的准确率和召回率仍需要改进。 在本文中,我们尝试通过提出 RefDiff 来填补这一空白,RefDiff 是一种自动方法,可识别在系统版本历史记录中执行的重构。RefDiff 采用基于静态分析和代码相似性的启发式组合来检测 13 种众所周知的重构类型。
2. 方法设计
RefDiff 采用基于静态分析和代码相似性的启发式组合来检测系统的两个修订版之间的重构。 因此,RefDiff 将系统的两个版本作为输入,并输出找到的重构列表。
2.1 Source Code Analysis
在第一阶段,对系统的源代码进行解析和分析,以构建代表每个高级源代码实体的模型,例如types 、methods和fields。
- 建立两个模型来表示变化之前 (E) 和变化之后 (E) 的系统。
- 为了提高效率,只分析属于修改过的源文件(添加、删除或编辑)的代码实体。


2.2 Relationship Analysis
该算法的第二阶段关系分析包括在代码更改前后查找源代码实体之间的关系。
2.2.1 Matching Relationships
某些类型的关系将更改前的代码实体映射到更改后的代码实体。
匹配关系的其他示例是 remove , rename …
例如,如表一所示,在方法重构的评估中,将m1 和 m2 被认定为Rename Method类型的条件是:
- m1和m2的名称不同;
- m1和m2的所在的类之间应该存在匹配关系;
- 并且m1和m2之间的相似指数,用sim(m1;m2)表示,应该大于一个阈值。
只要这些条件成立,我们就会在潜在的重命名方法关系列表中添加三元组  .
.
查找实际关系的最后一步是从潜在关系列表中选择非冲突关系并将它们添加到图表中。 但是,一个代码实体不能涉及多个匹配关系。 因此,只能选择其中之一,我们使用的标准是选择相似度指数较高的三元组。
- 例如,列表中可能有两个潜在的重命名方法关系:
 和
和  , 因为 e1 不能重命名为 e2 和 e3,我们选择后者为最终的重构关系结果。
, 因为 e1 不能重命名为 e2 和 e3,我们选择后者为最终的重构关系结果。
2.2.2 Non-matching Relationships
在上一节中,我们讨论了一个实体不能涉及多个匹配关系,但此属性不适用于非匹配关系。
- 例如,假设开发人员从方法 m1 中提取了一些代码到新方法 m2 中,即应用了 Extract Method。 也有可能开发者将 m1 的另一部分提取到新方法 m3 中。
鉴于非匹配关系彼此不冲突,识别它们的算法更简单。
例如,识别 和
和  之间的Extract Method关系的条件是:
之间的Extract Method关系的条件是:
- 不应该存在
 使得
使得  (即新增 m2 );
(即新增 m2 ); - 应该存在一个方法
 使得
使得  (即 m1 没有被移除);
(即 m1 没有被移除); - y 应该调用 m2;
- 并且m2和m1之间的相似度指数simp(m2;m1),应该大于一个阈值。
除了 Extract Method,我们的方法还支持检测 Inline Method 和 Extract Supertype 关系
2.2.3 Computing Similarity
如前所述,我们查找关系的算法的一个关键要素是计算实体之间的相似性。
- 计算代码实体相似性的第一步是将它们的源代码表示为
a multiset (or bag) of tokens- 多重集是集合概念的概括,但它允许同一元素的多个实例。 元素的多重性是该元素在多重集中出现的次数。换句话说,m(t) 是多重集中元素 t 的多重性。 请注意,不在多重集中的元素的多重性为零。



我们通过以下公式定义 e1 和 e2 之间的相似度: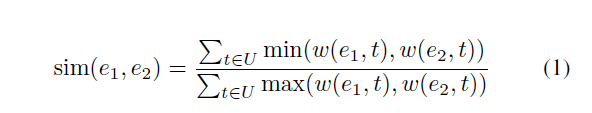
代码实体的令牌权重:我们的相似度函数基于权重函数  ,它表示代码实体 e 的t (token) 的重要性。 事实上,在区分代码元素方面,某些标记比其他标记更重要。
,它表示代码实体 e 的t (token) 的重要性。 事实上,在区分代码元素方面,某些标记比其他标记更重要。
- 例如,在图 1 中,所有三个方法都包含 return。 相比之下,只有一种方法(power)包含标记 Math。 因此,后者是比前者更好的方法之间相似性的指标。
为了考虑到这一点,我们采用了 TF-IDF 加权方案的变体,这是一种众所周知的信息检索技术。
- TF-IDF 是 Term Frequency–Inverse Document Frequency 的缩写形式,它反映了一个术语对文档集合中的文档的重要性。 在代码实体的上下文中,我们将标记视为术语,将方法(或类)的主体视为文档。
因此,权重函数公式如下:
 ,
,  的值随着
的值随着 增加而减少
增加而减少
非匹配关系的相似度:虽然前面介绍的相似度函数适用于计算两个实体的源代码是否相似,但在某些情况下,我们需要评估一个实体的源代码是否包含在另一个实体中。 这是 Extract Method,Inline Method 和 Extract Supertype 关系的情况。
该公式背后的基本原理是,当 e1 的标记多集是 e2 的标记多集的子集时,相似度最大,即,e1 中的所有标记都可以在 e2 中找到。 公式如下: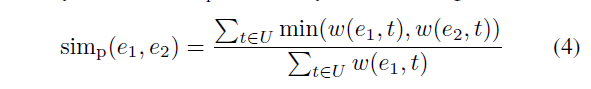
3. 实验评估
3.1 数据集
表 IV 中列出的存储库中的重构。 请注意,存储库包含相关的 Java 项目,例如 Google Guava、Spring Boot 和 OrientDB。表 IV 还提供了项目的简短描述以及每个存储库中 Java 代码的行数。
我们总共在评估数据集中包含了 448 个重构关系,涵盖了 12 种众所周知的重构类型。 
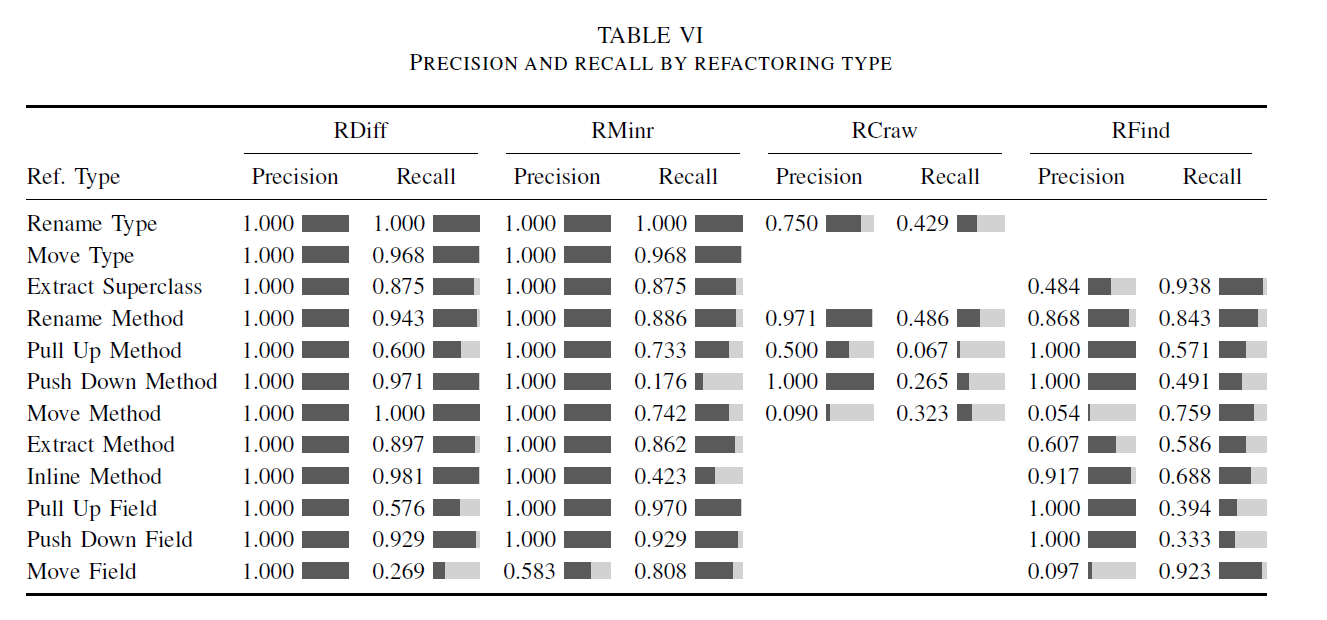
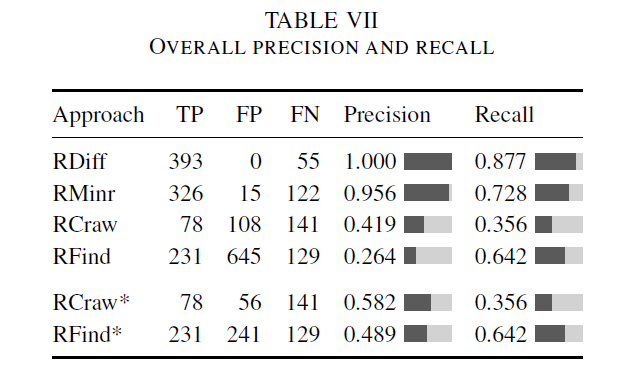
3.2 评估结果

若有收获,就点个赞吧
0 人点赞
