TSE 2020 RefDiff 2.0: A Multi-language Refactoring Detection Tool
https://github.com/aserg-ufmg/RefDiff
1. 概述
本篇文献的主要贡献:
- 我们在之前的工作 RefDiff 1.0 中提出的重构检测方法的主要扩展,其中包括重新设计其核心以使用独立于语言的模型和改进的检测启发式方法。
- 我们方法的公开可用实现,具有对 Java、C 和 JavaScript 的开箱即用支持。
- 使用在实际 Java 开源项目中执行的大规模重构数据集对 RefDiff 的精度和召回率进行评估,并将其与 RMiner(一种用于检测 Java 中重构的最先进工具)进行比较。 作为此评估的副产品,我们还使用我们的工具发现的新重构实例扩展了数据集。
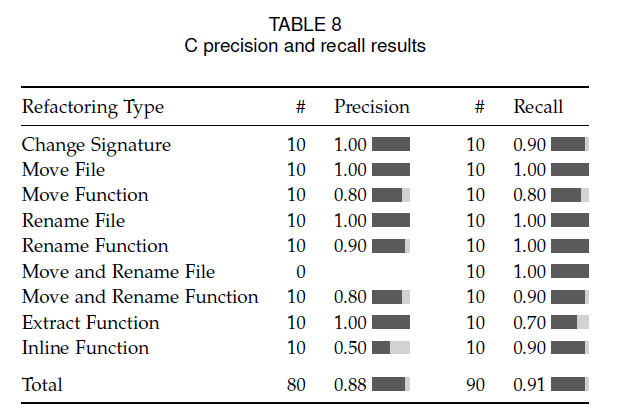
- 对 C 和 JavaScript 开源项目中 RefDiff 的准确率和召回率进行了评估。
2. 方法设计
2.1 Phase 1: Source Code Analysis
这个阶段的目标是计算一个代表系统源代码的语言独立模型,我们从现在开始将其表示为代码结构树(CST, Code Structure Tree)。
CST 是一种类似于抽象语法树 (AST) 的树状结构。 然而,在这种表示中,我们只对包含代码区域的粗粒度代码元素(例如,类和函数)感兴趣,并且可能被系统其他部分的标识符引用。
为了构建 CST,我们需要解析源代码,为目标编程语言生成 AST,并提取必要的信息。 因此,哪种类型的 AST 节点成为 CST 节点的决定取决于编程语言。
例如,在 Java 中,我们将类、枚举、接口和方法表示为 CST 节点。 相反,不表示局部变量。 然而,重要的是要注意 CST 节点的粒度决定了我们能够找到的关系的粒度,例如,如果我们在 CST 中表示方法,我们只能找到方法之间的关系。表 1 列出了我们方法的当前实现支持的每种编程语言的 CST 中表示的 AST 节点类型。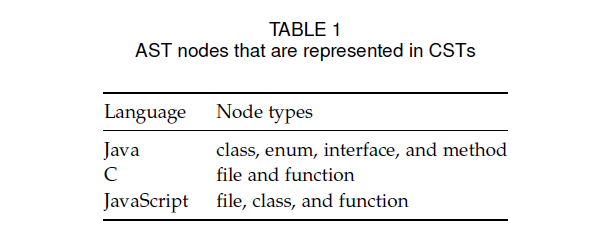
CST 构建过程
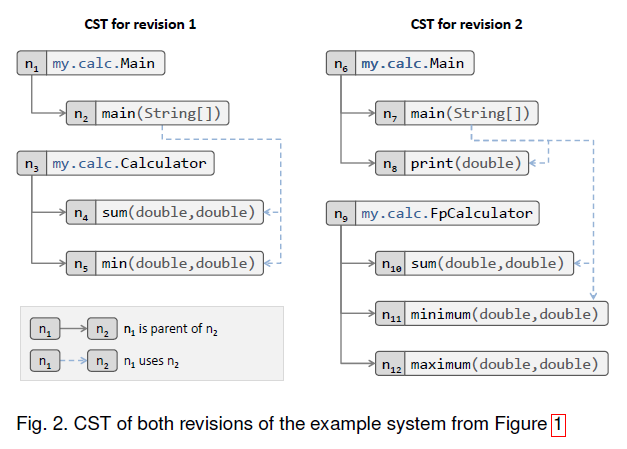
尽管 CST 的构建是一个特定于语言的过程,该对于整个重构检测方法而言,与语言无关,并且仅依赖于 CST 中编码的信息。 通过这种方式,人们可以仅通过实现源代码分析模块来扩展我们的方法以使用不同的编程语言。 为了演示此功能,我们提供了三种编程语言的实现:Java、C 和 JavaScript。
2.2 Phase 2: Relationship Analysis

2.3 Code Similarity
2.3.1 Name similarity
除了依赖于代码相似度,我们的算法还依赖于步骤 3 中的函数 nameSim(n1; n2)。该函数表示代码元素名称 n1 和 n2 之间的相似度。
为了计算 nameSim,我们首先将 n1 和 n2 的标识符分解成它们的组成词。
- 具体来说,我们拆分驼峰案例(例如, myIdentifier )或蛇案例模式(例如, my_identifier )。
- 例如, SomeLong_Name 产生三个术语: Some 、 Long 和 Name 。 然后,我们使用与 sim 相同的公式计算 nameSim,但在这种情况下,每个多组标记都包含构成 n1 和 n2 标识符的项。
2.3.2 Extract similarity
虽然之前介绍的相似度函数 sim 适用于计算两个代码元素是否相似,但不适合评估一个代码元素是否从另一个元素中提取出来,因为它们的源代码整体上可能有显着差异。
为了不那么容易受到这个问题的影响,我们提取关系的相似性索引依赖于以下假设:来自 e2 主体的代码应该主要包含在从 e1 中删除的代码中。
2.3.3 Inline similarity
计算内联关系的相似性索引类似于 Extract 相似性索引。 如果代码元素 e1 被内联到代码元素 e2 中,我们预计 e1 主体中的代码应该主要包含在添加到 e2 的代码中。
3. 实验评估
3.1 数据集
来自文献Accurate and efficient refactoring detection in commit history.icse 2018.
该 oracle 包含 3,188 个手动验证的重构实例,在 185 个开源项目的 538 个提交中检测到,涵盖 15 种重构类型。
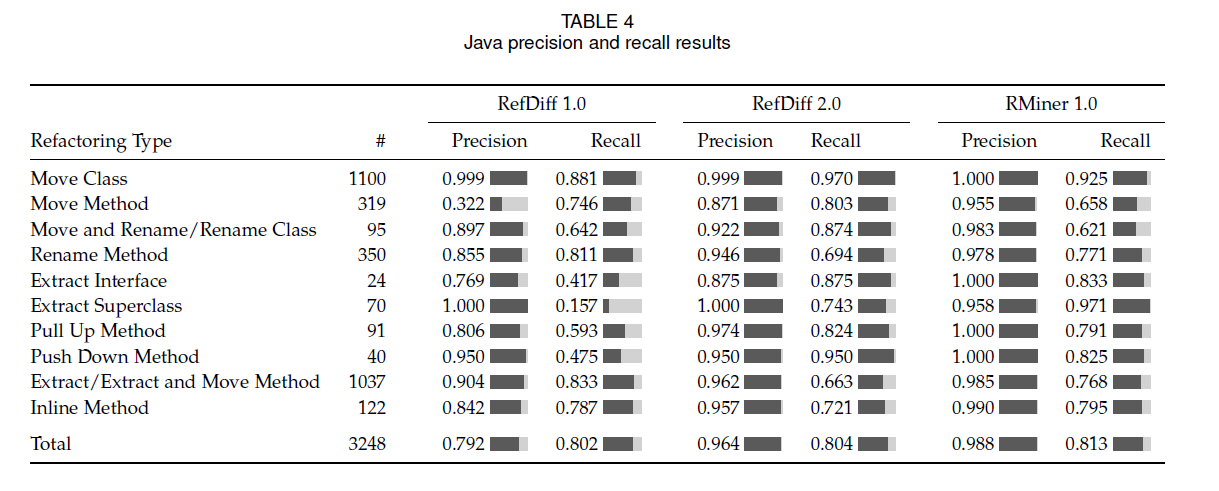
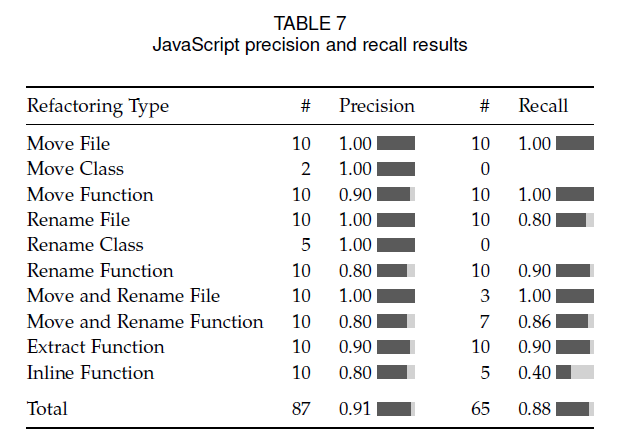
3.2 评估结果

若有收获,就点个赞吧
0 人点赞
