Abstract
摘要:错误分类是软件维护的一项重要任务,尤其是在工业环境中,及时修复错误对客户体验至关重要。 此过程通常是手动完成的,并且通常需要大量时间。 在本文中,我们提出了一种基于机器学习的解决方案来有效地解决该问题。 我们认为,在工业环境中,将错误分配给软件组件(然后分配给负责任的开发人员)比直接分配给开发人员更合适。 因为开发人员可以改变他们在行业中的角色,他们可能不会像以前那样监督相同的软件模块。 我们还通过实验证明将错误分配给组件而不是开发人员会导致更高的准确性。 我们的解决方案基于从错误描述中提取的文本投影特征。 我们使用深度神经网络来训练分类模型。 所提出的解决方案基于使用多个数据集的广泛实验实现了最先进的性能。 此外,我们的解决方案在计算上是高效的,并且可以近乎实时地运行。
索引词——自动错误分类、机器学习、文本分类
I. INTRODUCTION
在软件开发过程中的任何时候都可能出现错误。 对于软件行业来说,及时修复错误至关重要。 确定错误的优先级并将其分配给正确的开发人员,也称为“错误分类”,对于错误修复过程是必不可少的。 目前错误分类是由人手动执行的。 例如,在我们的组织中,当客户服务团队发现错误时,他们会提交包含错误摘要和描述的错误报告,并将错误分配给相关的软件组件和/或开发人员。 该过程耗时且容易出错。 错误通常需要几天甚至几周才能到达合适的开发人员。 另一方面,不断增长的错误报告集合为我们提供了大量可供我们学习的历史数据。 因此,我们提出了一种机器学习解决方案,以减轻人为负担并加快错误分配过程。
在软件行业,人事变动(开发人员切换团队/离开公司)是不可避免的。 因此,开发人员可能不负责他/她过去处理的错误。 如果他/她改变角色,将相同类型的错误分配给开发人员可能是不正确的。 另一方面,一段代码不太可能从其原始软件组件中移出。 与代码相关的错误将属于同一组件。 此外,负责每个组件的开发人员/团队在业界都有很好的定义:我们知道哪些开发人员/团队当前正在维护该组件。 因此,如果我们能够识别出导致错误的根本原因的组件,我们就可以立即找到能够解决错误的开发人员。 底线是组件的开发人员信息可能已过时,但始终知道当前负责的开发人员。 因此,我们不是直接分配给单个开发人员,而是将每个错误分配给导致错误的组件。 然后,维护组件的开发人员可以解决该错误。
将错误分配给正确的组件并非易事。 复杂的工业软件产品中通常有大量(100 多个)组件。 学习这么多组件之间的交互并找出根本原因是非常具有挑战性的。 此外,错误描述存在巨大差异。 工业错误数据集通常跨越多年,包括来自具有各种报告和写作风格的无数人的输入。 此外,不同错误描述的长度差异很大,从几句话到数百句话不等。 错误分配者必须从各种描述中推断出信息,无论它们多么紧凑或冗长。
本文的主要贡献可归纳如下:
- 错误分类的有效解决方案。 它比现有方法运行得更快。 此外,它在相同数据集上比当前最先进的方法获得了更好的性能。
- 一种基于投影的特征,它比使用标准包生成的 LDA 系数产生更好的结果。
- 几乎所有现有的工作都直接预测开发人员进行错误分类。 我们建议进行组件预测,然后确定相关的开发人员。 我们详细解释了为什么这在工业环境中更合适。
- a)基于多年的真实数据,我们表明开发人员与软件模块(因此相关的错误)之间的关系随着时间的推移发生了明显的变化。 因此,开发人员的预测可能不可靠。
- b) 我们还通过比较实验证明组件预测比直接开发人员预测要准确得多。
II. MORE DISCUSSION ON DEVELOPER ASSIGNMENT FOR INDUSTRY APPLICATIONS
III. OUR SOLUTION
使用错误描述及其分配组件的历史数据,我们可以训练组件分类器并使用它来预测哪个组件对新错误负责。 我们的方法包括三个步骤: 1. 预处理错误描述。 2. 从处理后的文本中提取特征。 3. 使用基于提取的特征向量的深度神经网络 (DNN) 进行学习/分类。
A. Preprocessing
我们的方法使用两种类型的预处理:
1)。 每个错误描述的文本预处理,用于训练和测试阶段。 我们首先从错误描述中提取单词(所谓的标记化)并删除不提供信息的停用词,例如“I”、“are”和“that”。 然后我们使用词干算法 [1] 将每个单词简化为其根形式,类似于之前的工作 [2]。 将每个错误描述转换为词干列表,我们基于列表构建词频图。
2)。 离线主题提取,仅在训练阶段使用。 我们从大量预处理文本(错误描述)的语料库开始,并删除非常罕见的单词,这些单词在整个语料库中出现的次数不到 3 次。 然后我们使用潜在狄利克雷分配(LDA)[3]来提取一些主题。 主题提取基于流行的 Gensim 包 [4]。 每个主题代表一个词的分布。 基于比较实验,我们根据经验将主题数设置为 500。
B. Feature extraction
LDA 之前已被 [5] 用于错误定位。 根据提取的主题,我们可以使用 Gensim 获得错误描述的主题概率分布,然后将此分布转换为特征向量。 但是,我们发现可以基于提取的主题构建更多的判别特征。 这个想法是将每个主题视为主题空间中的基础,在我们的例子中,主题空间有 500 个维度。 然后我们在主题空间中找到每个错误描述的坐标。 坐标的每个元素是通过将词频图投影到相应的基上得到的。 坐标向量,在我们的例子中是一个 500 维向量,被用作 bug 的特征向量。 算法 1 描述了构建特征向量的细节。 此特征提取步骤也用于训练和测试。
其中 D 是主题空间的维数,在我们的实验中 D = 500。 词频用哈希图表示,所以我们可以在 O(1) 时间内检查一个主题词是否出现在 H 中,从而保证了算法的速度。
现在我们使用一个玩具示例来说明预处理和算法 1 的工作原理:假设我们有一个错误描述“I have a dashboard failure!”。 经过预处理,标点和停用词被去除,我们得到一个词频图: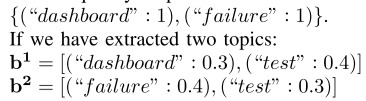
那么这个 bug 的特征向量将是 (0.6, 0.8)。对于另一个 bug 描述“I have a failure!”,特征向量将是 (0, 1)。 我们的解决方案中使用的特征向量具有更高的维度,并且对于构建分类器具有高度的判别性。
C. Learning Using Neural Network
为了了解特征向量与其相关的人类标签之间的关系,我们使用深度神经网络 (DNN) 模型。 在训练过程中,反向传播用于最小化训练误差,而预测和测试只需要前向传播。 在尝试了不同的网络结构后,我们采用了具有 4 个全连接层和 Rectified Linear Unit (ReLU) [6] 作为激活函数的 DNN; 它为我们的问题实现了偏差和方差之间的最佳权衡。 我们使用 PyTorch [7] 实现了神经网络。 基于类的加权应用于训练数据中的所有实例。 例如,某些组件类存在许多错误实例,因为它们正在不断开发中。 在训练神经网络时,我们为这些实例分配了较低的权重,因此它们不会压倒实例较少的类。
IV. EVALUATION
为了评估我们的方法,我们使用以前广泛使用的性能指标 [8]-[10]:准确率和召回率@K。 Recall@K 表示具有真实标签的测试用例出现在预测的前 K 个候选列表中的百分比。 准确率相当于recall@1,即仅检查第一个候选时正确预测的百分比。 我们所有的性能评估都基于 10 倍交叉验证。 尽管我们的方法是为组件预测而设计的,但我们也将其应用于训练开发者预测的模型,以便我们可以与基于开发者预测的现有工作进行比较。 我们的目标是回答以下研究问题:
- RQ1: Do the proposed projection-based features outperform the standard LDA-based features?
- RQ2: Is predicting components more reliable than predicting developers?
- RQ3: Is it really the case that there are significant developer changes in the industry?
- RQ4: How does the proposed approach compare with the state-of-the-art methods when predicting developers?
A. Data Description
我们从我们的组织收集了两个大型错误数据集,分别匿名为“A”和“B”。 较小的数据集“B”包含从 5 年期间收集的 30,662 个 JIRA 错误报告。 每个错误报告都带有一个“描述”字段,以及分配给它的“组件”和“开发人员”字段。 有 487 名开发人员和 182 名活跃开发人员(他们至少修复了 10 个错误)。 组件数量为 159。另一个数据集“A”有 71,829 个错误报告,是从更长的 12 年时间段收集的。 但是,这个数据集只有“描述”和“组件”字段,没有“开发者”。 所以它只用于分量预测。 “A”中的组件数量为 199。我们还获得了 [10] 中作者的免费提供,他们从开源项目中收集的数据集:“JDT”数据包含 1,465 个错误报告; “平台”数据包含 4,825 个错误报告; 最大的“Firefox”数据包含 13,667 个错误报告。 所有三个数据集都包含两个字段:错误描述和分配错误的开发人员。
B. Feature Evaluation (RQ1)
我们做了三组实验:1)基于数据集“A”的成分预测; 2)基于数据集“B”的成分预测; 3)基于数据集“B”的开发者预测。 在每组实验中,我们将所提出的基于投影的特征的性能与基于使用 Gensim 获得的标准 LDA 系数的性能进行比较。 比较结果分别如图1(a)、图1(b)和图1(c)所示。 在所有实验中,所提出的特征都优于标准 LDA 系数。 在这些情况下,相对于原始数字(使用标准 LDA 系数),性能数字分别提高了 6%、2% 和 5%。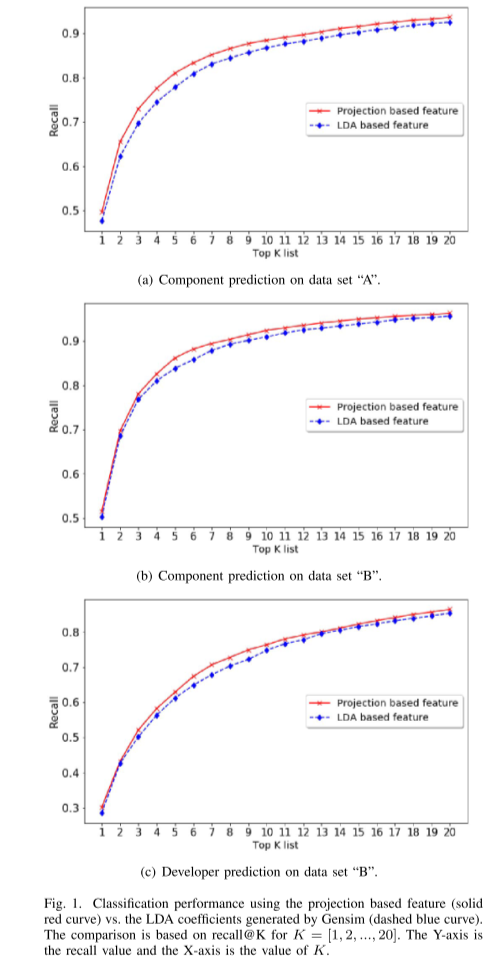
C. Triage Reliability Evaluation (RQ2)
我们在第二节中已经解释过,直接预测开发人员不如预测工业环境中的组件可靠,现在我们通过实验证实了这一假设。 数据集“B”非常适合此目的,因为它为每个错误都分配了组件和开发人员
我们应用我们的方法来训练两种模型,一种用于预测开发人员,一种用于预测组件。 在实验中,我们只考虑修复了至少 15 个 bug 的开发人员,这样的开发人员数量为 152。因此类(开发人员)的数量与组件预测的类(组件)的数量几乎相同。 通过这样做,我们消除了由类数差异引起的潜在偏差:通常类数越少,分类精度越高。 这已经在现有的工作中得到证明,例如 [10]、[11],其中基于活跃开发者的预测准确度明显优于基于所有开发者的预测准确度。 它还对不同论文报告的性能数字差异给出了一些解释:通常当算法在具有较少类数的数据集上测试时,会报告更好的数字。 这里的类可以是开发人员、团队或组件,具体取决于任务。 图 2 显示了性能比较。 基于分量预测的预测性能明显更好。 正如我们之前提到的,一旦确定了组件,就可以很容易地确定负责的开发人员。 虽然我们可以通过两种方式将开发人员分配给一个错误,但通过组件预测找到开发人员显然要可靠得多。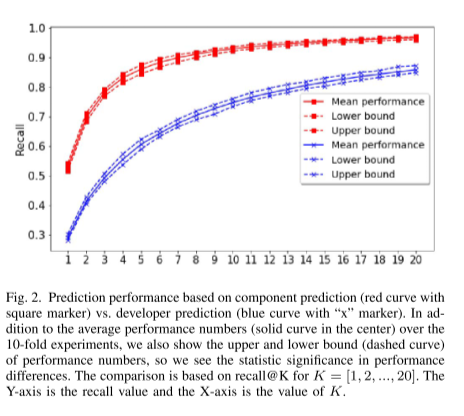
D. Insight Into Developer Changes (RQ3)
在第二节中,我们还讨论了人员变动如何影响错误分类结果。 然而,如果事实上没有多少开发人员改变他们的角色并且大多数开发人员总是负责相同类型的错误,那么我们的论点就会被削弱。 因此,我们使用数据集“B”来查看组件和开发人员之间的关系,以便我们了解是否确实如此。 由于每个 bug 都有其指定的组件和开发人员,我们可以看到哪些开发人员修复了与软件组件相关的 bug,以及开发人员处理了哪些组件。
从图 3 中我们可以看到:大约 50% 的组件有超过 10 名开发人员为它们修复错误; 大约 25% 的组件有 20 多个错误修复程序。 所有这些开发人员不太可能同时在积极地开发组件,因为通常每个组件都由一个小团队(约 3 个开发人员)维护。 因此,如果我们看一个时间段,例如某个特定的月份,这些组件的大多数错误修复者实际上并没有积极地为这些组件修复错误。 因此,即使模型从历史数据中正确地了解到开发人员对一种类型的错误负责,测试时的预测也可能是错误的,因为他/她不再致力于它。
从图 4 中可以推断出类似的观察结果:超过 50% 的开发人员修复了至少 10 个组件的错误; 25% 的开发人员修复了至少 20 个组件的错误。 一个开发人员不太可能同时处理这么多组件。 因此很明显,许多开发人员在团队之间转移并处理不同类型的错误。 一旦转移,错误类型(他们过去修复的)将分配给接管工作的新开发人员。 因此,基本事实标签将是新开发人员。 如果学习模型将错误分配给这些转移的开发人员,尽管它从历史中正确学习,但不同意基本事实将被视为不正确。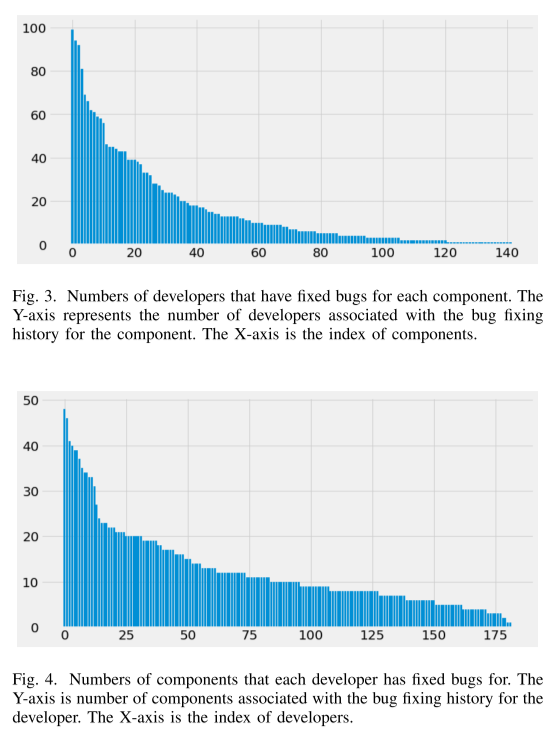
我们还进行了另一组实验:我们研究了关注更活跃的类(具有更多相关错误的开发人员/组件)的性能增益。
很明显,当基于更活跃的开发人员进行评估时,性能会更好:首先,这会移除没有足够数据进行培训的开发人员。 其次,这减少了类的数量,从而减少了出错的可能性。 但是,我们有兴趣量化这种关系。 我们再次使用数据集“B”,因为它同时具有开发人员和组件标签。 我们评估了原始数据和仅活动组件数据(具有至少 10 个错误修复记录的组件)的组件预测性能。 原始数据包含 159 个组件,而后者包含 96 个活动组件。 性能比较如图 5(a) 所示。 我们还评估了活跃开发者(至少有 10 条错误修复记录)和非常活跃的开发者(至少有 50 条错误修复记录)的开发者预测性能。 我们使用这些数据集得出可比较数量的开发人员和组件。 活跃开发者数量为 182,非常活跃开发者数量为 93。在这种情况下,类大小减少的百分比大于组件预测的百分比,但准确率(recall@1)的提升较小。 有趣的是,开发人员预测的性能改进随着 K 的增大而变得更大(recall@K)
这些观察再次验证了我们的论点,即开发人员的预测不适合工业环境。 准确性的有限改进表明更难确定确切的 ground truth 开发人员:预测的开发人员可能是修复相同 bug 的替代开发人员(不是 ground truth 标签),或者开发人员已经离开。 另一方面,K 越大,它就越有可能包含所有可能的开发人员(包括替代错误修复者),因此性能提高得更多。 对于组件预测的情况,虽然类减少不那么显着,但准确率提高更多,性能提高最终饱和而不是继续上升。 我们还在图 5(c) 中展示了活跃开发者和所有开发者之间的比较,因此我们可以从使用相同阈值(均为 10)选择数据类别的角度来比较开发者预测和组件预测。 趋势与图 5(b) 中的趋势相似。 尽管类的数量显着减少,但性能提升相对较小,这意味着很难确定真正的开发人员。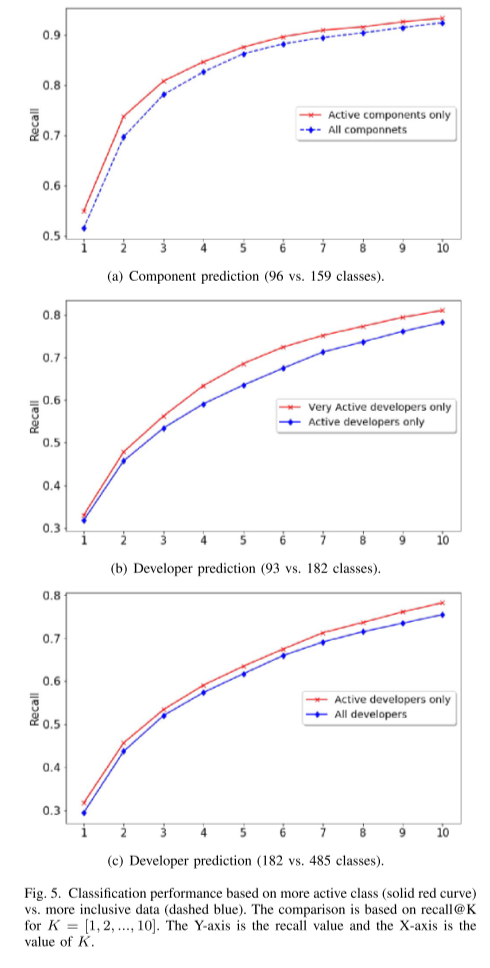
E. Comparison With Existing Approaches (RQ4)
除了显示通过组件预测进行错误分类比开发人员预测更可靠之外,我们还想检查所提出的方法与最先进的方法相比如何。 最近关于工业错误分类的两篇论文是 [9] 和 [10]。 琼森等人。 [9] 在拥有 15k 错误报告和 67 个团队的最大数据集上实现了 50% 的准确率,而 Lee 等人。 [10] 在他们最大的公开可用的“Firefox”数据集上报告了 30.5% 的准确率,其中包含大约 14k 的错误报告和 142 名活跃的开发人员。 所有这些性能数据都是使用 10 倍交叉验证获得的。 虽然不在同一个数据集上,但我们可以看到 [9] 通过预测团队而不是开发人员获得了更好的准确性。 因为就他们维护的代码而言,开发人员比团队更频繁地更改。 较少的类可能是提高准确性的另一个因素。
组件和团队预测密切相关,因为我们可以确定负责该组件的团队。 通过组件预测,我们在原始“B”数据集(包含 159 个组件的 30k 错误报告)上获得了 51%,在 96 个活动组件数据上获得了 55%。 由于我们没有使用与 [9] 和 [10] 相同的数据集进行试验,因此我们无法得出明确的结论。 尽管如此,这些数字优于 [9] 中报告的 50% 准确度,而且我们的数据集更全面,类别也更多。
我们还将我们的解决方案应用于 [10] 提供的数据集。 与[10]中报道的比较结果分别见表一、表二和表三。 在“JDT”数据集上,我们在与所有开发人员进行测试时获得了相似的性能水平,尽管在仅与活跃开发人员进行测试时,这个数字略低(1% ∼ 4%)。 在 3 倍大的“Platform”数据集上,我们在这两种情况下都取得了较好的性能,提高了 3% ∼ 8%。 此外,我们的结果在最大的“Firefox”数据集上要好得多。 与最先进的方法相比,在较大数据集上的卓越性能清楚地证明了我们的方法的有效性。 图 6、图 7 和 8 显示了更详细的性能数据,recall@[1,2,…, 20]。 请注意,我们在处理“JDT”和“平台”数据集时使用了 3 层网络,同时保持其他设置不变。 这两个数据集的错误报告数量要少得多(均低于 5k),并且很容易过度拟合。 所以我们采用了一个更简单的网络(通过从我们的原始网络中移除一个隐藏层)来减少过度拟合。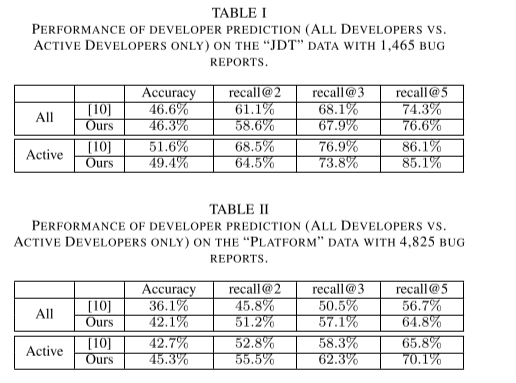
除了我们获得的有希望的性能数据外,我们的解决方案非常有效。 根据我们的实验,使用配备 Intel i7 2.5G CPU 和 16GB 内存的笔记本电脑,预测接近实时,平均运行时间为 0.8 秒。 据我们所知,没有其他方法可以在一秒钟内运行。
V. THREATS TO VALIDITY
VII. CONCLUSION AND FUTURE WORK
错误分类是软件开发和维护的一项关键但具有挑战性的任务。 在本文中,我们提出了一种基于机器学习的解决方案来有效地解决该问题。 我们基于错误描述构建特征向量。 特征向量基于词频在主题空间上的投影。 它帮助我们获得比使用基于流行的 Gensim 包的标准 LDA 模型更高的性能。 基于提取的特征向量,我们使用深度神经网络进行学习和预测。 根据我们的大型私人数据集,我们的绩效数字与报告的结果相当或更好。 我们还在以前工作使用的公共数据集上实现了更高的准确性。 此外,我们的解决方案几乎实时运行,执行时间不到一秒,这是我们所知最快的解决方案。 基于提议的解决方案,我们为组织中的用户构建了一个几乎实时运行的错误分类服务。 它已经过广泛的测试并收到了积极的反馈。
为了进一步提高其性能,我们正在考虑将基于位置的方法与我们的工作相结合,如 [25] 中所建议的那样。 我们还计划整合其他有效的方法(这样就不会增加太多额外的运行时间),例如 [10]。 通过堆叠不同方法的 [26] 输出,我们期望可以获得更好的性能。

若有收获,就点个赞吧
0 人点赞
