Abstract
摘要:回归测试是软件开发和维护的关键部分。 它确保对现有软件的修改不会破坏现有的行为和功能。 关于回归测试的一个关键假设是它们的结果是确定性的:当在没有任何修改且具有相同配置的情况下执行时,它们要么总是失败,要么总是通过。 然而,在实践中,存在不确定的测试,称为片状测试。 不稳定的测试会导致测试运行的结果不可靠,并且会破坏软件开发工作流程。
在本文中,我们提出了一种新技术,可以在代码级别自动识别不稳定测试的根本原因的位置,以帮助开发人员调试和修复它们。 我们在 Google 的 428 个项目中研究了 Flaky 测试的技术。 根据我们的案例研究,该技术有助于以 82% 的准确率确定片状根本原因的位置。 此外,我们的研究表明,集成到适当的开发人员工作流程中、调试助手的简单性和全自动修复对于片状调试和修复工具的采用和可用性来说是至关重要的和首选的组件。
索引词——软件维护、诊断、调试辅助、调试器、跟踪、测试管理、易碎测试
I. INTRODUCTION
回归测试是软件开发的关键部分 [1]、[2]。 当开发人员向系统添加新功能时,他们会运行回归测试套件以确保他们当前的更改不会无意中更改现有功能。 如果回归测试套件中的所有测试都通过了代码更改,开发人员通常会认为测试结果是成功的并继续提交他们的更改。 但是,如果任何测试失败,他们通常会调查失败的原因 [3]。 因此,回归测试为开发人员提供了关于他们是否可以安全地提交更改的关键信号。 相同的信号通常用于开发工作流程下游的附加步骤,例如 在发布期间,只有在回归套件中的所有测试都通过时,才会推出新版本的系统。
重要的是,这个信号是一致的和确定性的,即如果测试套件在没有任何更改的情况下使用相同的配置参数执行,它们应该总是通过或总是失败。 不幸的是,测试套件中可能存在非确定性的,即所谓的片状 Flaky tests [4]-[9] 测试。 不稳定的测试是有问题的,因为它们会将噪声引入到执行测试套件 [10]-[12] 产生的信号中。
首先,不稳定的测试可能很难调试,因为它们是不确定的,因此在调试期间可能难以重现它们的行为。 其次,它们可能会导致开发人员因在不相关的代码更改上失败而浪费时间 [7]、[10]、[12]。 当开发人员更改代码、运行测试套件并观察故障时,他们通常会尝试对其进行调试以了解导致故障的原因。 如果失败是由于一个不稳定的测试,而不是他们的更改,那么调试时间就被浪费了。 这样的错误信号可能会导致许多开发人员不断浪费精力,他们更改代码导致执行包含不稳定测试的测试套件,尤其是在像 Google [3]、[12] 使用的大型单体代码库中。 第三,不稳定的测试会降低开发人员对测试套件的信任感,并可能掩盖实际的失败。 每当测试失败时,如果开发人员观察到该测试之前由于不稳定而失败,他们可能会忽略该执行的结果,并且实际上可能会忽略真正的失败并意外地将错误引入系统。
据报道,从业者和研究人员都报告说,在许多系统中都存在 Flaky tests 及其引起的问题。 根据罗等人最近发表的一项研究。 [11],据报道,在 Google 的持续集成 (CI) 系统( TAP [12]、[27])的测试执行过程中,所有测试失败的 4.56% 是由于 15 个月窗口内的不稳定测试造成的。 Herzig 和 Nagappan [16] 的另一项研究报告称,微软的 Windows 和 Dynamics 产品估计有 5% 的测试失败是由于不稳定的测试。 同样,Pivotal 开发人员估计,几乎一半的测试套件失败都涉及片状测试 [28],而 Labuschagne [24] 的另一项研究报告称,TravisCI 中 13% 的测试失败是由片状测试引起的。
有不同的策略来处理不稳定的测试及其对开发人员工作流程的破坏。 一种常用的方法是使用相同的配置多次运行 flaky 测试,如果至少一次执行通过则声明它通过,如果所有运行失败则声明它失败。 Google 的 TAP 系统 [4]、[29]、[30] 使用了这种策略,并且几个开源测试框架通过各种策略支持类似的概念,例如在代码中对易碎测试进行注释,例如 Android [31] 中的 @FlakyTest,Spring [32] 中的 @Repeat,Jenkins [33] 中的 @RandomlyFails,Maven [34] 中的 rerunFailingTestsCount 属性。 然而,这并不理想,特别是对于大型代码库,因为它浪费机器资源,并且结果仍然可能很嘈杂,具体取决于“片状”测试的程度(即,具有高片状可能性的测试套件需要更多运行才能获得 通过运行)[35],[36]。
另一种策略是完全忽略易碎测试(例如 JUnit [37] 中的 @Ignore)或将已知易碎的测试分开到不同的测试套件,并将该测试套件的执行结果视为“可选”的各种 软件开发活动[4]。 然后,开发人员调查“可选”测试套件中的任何测试是否开始始终如一地通过,即它们现在是确定性的,并将它们移回原始测试套件。 这也不理想,因为它需要开发人员的手动工作,并且确定性失败测试可能会在可选测试套件中的其他片状测试中丢失,从而导致真正的失败被忽略。
这些策略有严重的缺点,并且解决了不稳定测试引入的问题,而不是解决根本原因。 尽快修复不稳定的测试以保持较高的开发速度并为软件开发和维护活动产生可靠的信号非常重要。 在本文中
- 我们提出了一种新的技术来自动识别代码中不稳定的根本原因的位置,
- 我们在一个工具中实现了这项技术,并将其部署在 Google 的多个产品的不稳定测试中,以通知开发人员导致该漏洞的代码位置,
- 我们在多个案例研究中评估该技术的成功,
- 我们报告我们对用户对工具和技术的感知和期望的学习。
II. INFRASTRUCTURE RELATED TO FLAKY TESTS AT GOOGLE
为了防止和避免在开发工作流程中不稳定测试的负面影响,谷歌已经开发了几个系统。 这些系统已集成在一起,以引起对开发人员工作流程中不稳定测试的关注。 下面我们讨论这些系统的一个相关子集。
- TAP 这是谷歌运行单元测试的 CI 系统 [12]、[27]。 TAP 在一天中以不同的版本连续运行测试。 开发人员可以将他们的测试标记为易碎的,TAP 会多次运行此类测试以检查是否至少可以获得一次通过运行 [38]。 如果是这样,则认为测试已通过。
- Flakiness Scorer 该系统为每个片状测试分配一个片状分数。 它从 TAP 获取与所有易碎测试执行相关的信息,最近的执行具有更大的权重。 然后,它会分配一个分数,表明这些测试在未来由于片状而失败的可能性有多大,并提供一个基于 Web 的用户界面来呈现该信息。 我们在下一节讨论的工具中使用片状分数
- Google Issue Tracker 这是 Google [39] 使用的问题跟踪系统。 开发人员可以选择检查他们是否有任何由 Flakiness Scorer 识别的不稳定测试。如果有,他们可以手动创建问题并将其分配给团队成员进行调试和识别不稳定的根本原因,如图 1 所示。 确定了根本原因并处理了不稳定的测试(例如,修复或完全删除),他们解决了问题。 在我们的一个案例研究中,我们通过自动评论他们创建的问题来通知开发人员如何调试/修复不稳定的测试
- Critique 这是 Google [40] 的基于 Web 的代码审查工具。 当开发人员更改代码时,他们会通过修改创建更改,并将其发送给其他开发人员进行审查。 在发送审查后,一些自动化工具和回归测试会在代码的更改版本上运行,以通过在代码的相关部分或整个更改本身上显示通知来帮助所有者和审查者提出建议和修复。 如果更改的所有者发现这些分析中的任何一个没有帮助,他们可以通过单击“无用”按钮来提供反馈。 在我们的一个案例研究中,我们通知开发人员有关易碎测试以及如何调试/修复它们。
III. FLAKINESS DEBUGGER
在本节中,我们将介绍一种新技术,该技术可以自动识别不稳定测试的根本原因的位置,解释实现该技术的工具,并通过将其集成到开发人员的日常工作流程中来讨论其在 Google 上的部署。
A. Non-Determinism and Flakiness
测试中的不确定性有很多原因,例如 并发和测试顺序依赖性 [6]、[11]、[38]。 在本文中,我们的目标不是将片状类型分类到分类中,区分片状是在测试代码中还是系统代码中,或者找到任何特定类型的片状测试的根本原因。 相反,我们建议在测试或系统代码中为任何不稳定的测试找到不稳定的位置,并向开发人员显示报告以帮助调试。 由于开发人员是他们自己代码的领域专家,我们让他们根据报告确定和修复根本原因。
清单 1 显示了在本文的讨论中使用的一个工作示例。 在清单 1 中,getRandomZeroOrOne() 在内部使用另一个随机数生成器生成一个 0 或 1 的随机数。 第 8 - 13 行之间的代码存在不确定性。假设 R 是一个良好的均匀随机数生成器,getRandomZeroOrOne() 预计分别在大约 50% 的时间返回 0 或 1。 在清单 2 中,testGetRandomZeroOrOne() 通过断言它始终返回 0 来测试清单 1 中的 getRandomZeroOrOne() 的功能。这个测试预计有 50% 的时间会失败,这使它成为一个不稳定的测试。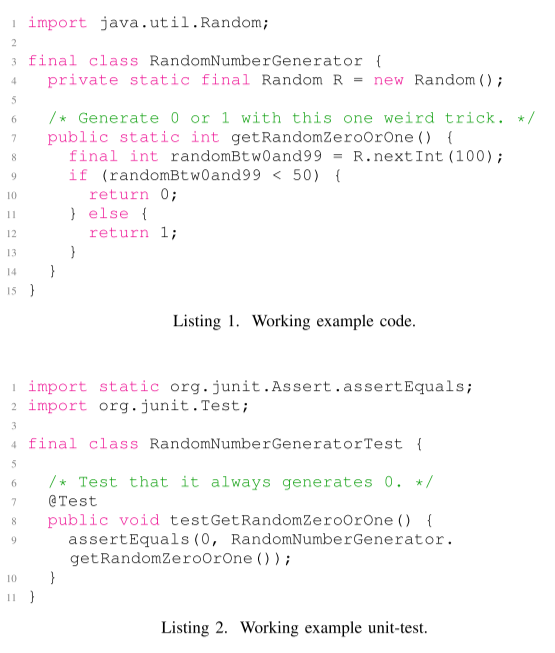
Google 的所有 Flaky 测试的完整列表由 Flakiness Scorer 确定和知晓。
B. Divergence
在本节中,我们提出了新的 DIVERGENCE 算法来识别代码中首次出现片状的位置。 该算法将每个失败运行的执行跟踪与所有通过运行进行比较,以找到失败运行的控制流与任何通过运行的第一个分歧点,即从未观察到失败运行的控制流的点。 一个通过的运行,在算法 1 中描述。 DIVERGENCE 接受一个测试列表 t 以及它们相应的通过和失败的执行。 对于失败的执行 f,我们找到传递的执行 p,它与 f 具有最长的公共前缀,并提取公共行和 f 和 p 之间的第一个分歧行。 我们为每个不稳定的测试存储这些信息。

例如,考虑清单 2 中的方法 testGetRandomZeroOrOne() 执行多次以获得通过运行和失败运行。 图 2 显示了该不稳定测试的示例执行,左侧为通过运行,右侧为失败运行。 getRandomZeroOrOne() 中的第 7 - 9 行对于通过和失败的运行都是通用的。 通过运行的第 10 行和失败运行的第 12 行是执行之间的分歧点。
DIVERGENCE 算法建议向开发人员显示共同线以及通过和失败运行的第一个分歧点,以帮助他们了解首先引入片状的位置。 在第一个分歧点之后,控制流中还有进一步的分歧,但这些分歧被忽略了,因为它们没有像第一个分歧点那样添加更多有价值的信息。
C. Finding Divergence for Flaky Tests
我们在 Google 实施了一个使用 DIVERGENCE 的工具,称为 FLakiness Debugger (FD)。 FD 采取了几个步骤来为 Google 的许多产品组的测试找出片状的根本原因,算法 2 对此进行了总结。
首先,要让 FD 用于项目的易碎测试,它需要由项目的所有者启用。 FD 找到所有启用它的项目 P,并识别它们的测试 TP。
其次,对于 TP 中的所有测试,FD 会查询 Flakiness Scorer 以检查其中哪些测试是不稳定的,称为 TF,以及它们的易碎性分数是多少。 在高层次上,对于给定的测试 t,Flakiness Scorer 通过检查 TAP [38] 在执行过程中最近剥落的次数来计算 t 的剥落分数 f(t)。 使用这个分数,如果 f(t) < M,FD 会跳过 t,其中 M 是一个片状阈值,可防止运行很少片状的测试,并且会使用太多资源来获得至少一次失败的运行。 我们设置 M = 0.1。
第三,FD 检测测试 t 和拥有 t 的同一团队拥有的相应非测试代码。 这不包括上游拥有的任何代码(例如,清单 2 中的 assertEquals 和清单 1 中的 java.util.Random 没有被检测),因为开发人员想要理解和调试他们自己的代码,并且通常忽略上游依赖项中的代码。 然后,FD 总共执行了 E 次测试,并为通过和失败的测试执行收集动态执行跟踪。 我们设置 E = 50。
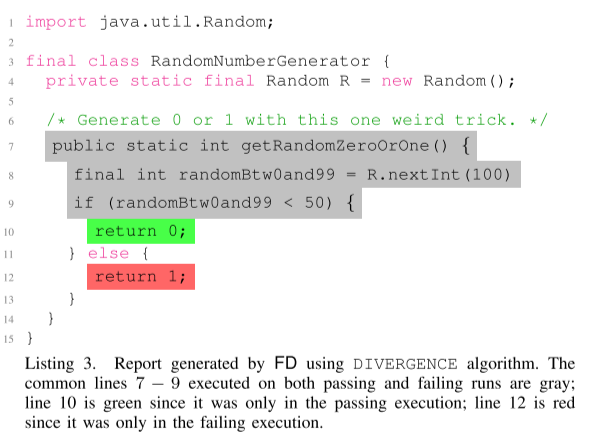
最后,使用 DIVERGENCE 算法找到共同点和分歧点,如图 2 所示,并将其存储在后端数据库中,其中包含指向稍后显示给开发人员的 html 报告的链接,如清单 3 所示。启用后,FD 无需执行 开发人员的任何操作,准备报告,存储和缓存它们。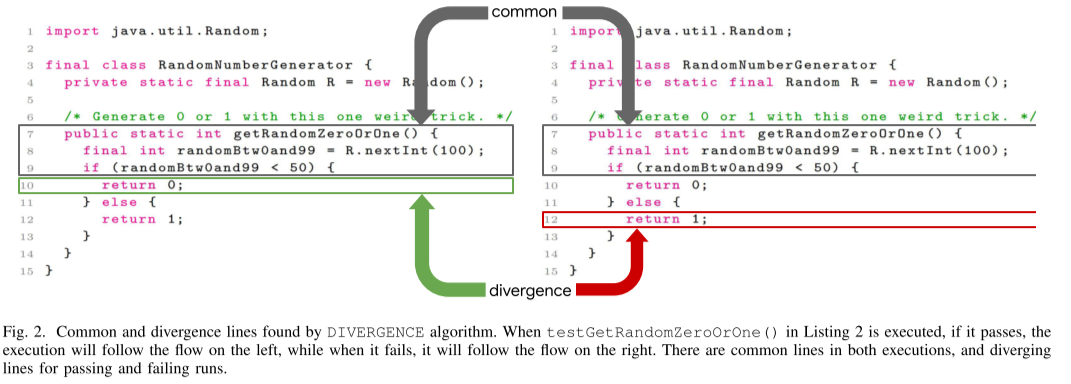
IV. CASE STUDIES AND DISCUSSION
为了评估 FD 的有效性,我们进行了几个案例研究。 所有这些案例研究都涉及关于易碎测试的 FD 报告,类似于清单 3 中所示的报告。FD 使用 Google 的内部动态执行跟踪技术,但有一定的局限性:
- 它仅适用于完成执行时间少于特定时间限制的测试,以防止执行跟踪变得过大。
- 它限制了收集的执行跟踪的总大小,以防止使用过多的资源。
- 它只支持C++ 和Java。
由于这些限制,再加上 DIVERGENCE 中使用的限制 M(来自第 III-C 节),我们仅针对 Google 上所有不稳定测试的子集提供 FD 报告。
A. Case Study 1: Usefulness of FD Reports
在这项研究中,我们发现总共有 83 个关于易碎测试的历史问题(如图 1 所示)已通过一个或多个代码更改标记为该问题的修复程序得到解决,并且 FD 会针对这些问题生成报告 . 其中 39 个测试使用 C++,44 个使用 Java。 这些问题从未收到 FD 的任何反馈,即所有问题都已由开发人员手动调查和修复。 然后,我们在这些不稳定的测试中运行 FD,它们被确定为不稳定的版本。 然后我们要求两名不属于这 83 个问题所属团队的开发人员仅独立检查 FD 报告(他们无权访问问题报告或原始团队如何解决每个问题) ,并根据该报告分三类预测片状的根本原因:
- 1) Useful-Exact (UE):不稳定是由于 FD 报告指向的确切行,可以通过更改这些行来修复。
- 2) Useful-Relevant (UR):Flakiness 与 FD 报告指向的行相关,但应在代码中的另一个位置进行修复(例如,问题是由于 RPC 超时,FD 指向 RPC 调用站点 ,解决方法是增加在另一个文件中定义为常量的超时时间)。
- 3) Not-Useful(NU):FD 报告不确定、难以理解或无用。
表 I 总结了开发人员的回应。两个开发人员将相同的 FD 报告标记为 NU,同意他们认为有用的报告(UE + UR),但不同意 7 FD 报告的潜在修复分类。 我们调查了这些报告,发现两个开发人员的分类都是正确的,因为可能有几种方法可以修复不稳定的测试。 例如,在清单 4 中,可以在 ItemStore 中使用一个保留顺序的 Map 实现,或者可以将 testGetItems 更改为断言无序集合的相等性。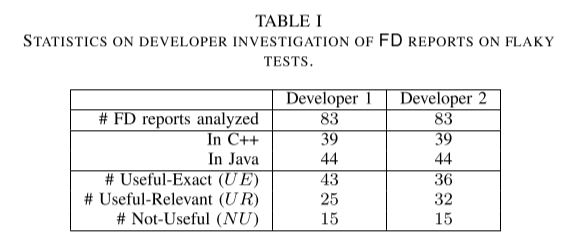
在收集了两位开发人员的回复后,我们将他们的预测与开发人员在每个问题报告中提交的原始修复进行了比较。 我们的调查开发人员将 FD 报告标记为有用 (UE+UR) 的所有 68 个问题的修复都根据他们的至少一项预测得到修复,即 FD 报告在 81.93% 的案例中预测修复是有用的。
此外,在研究结束时,在查看了他们标记为 NU 的剩余 15 个问题的实际修复后,我们确定其中 4 个报告指向的代码位置可能是相关的 (UR),如果他们有更多的经验 使用 FD 生成的报告和项目的代码库。 其余 11 份报告用于执行时间较长的测试,并且由于时间限制而被测试运行者终止,因此 FD 指向的位置根据终止时间而有所不同,即它们在 FD 报告中似乎是随机的/无关的, 即使有经验的 FD 用户仍然可以理解生成的报告可能与终止有关。
最后,我们向两位开发者询问了他们对 FD 报告的体验,并收到了以下回复。
。。。
根据这些反馈,我们得出结论,即使报告并不太复杂,开发人员在第一次看到它们时可能难以解释它们。 可以根据不同行中涉及的代码片段来识别某些片状的根本原因,例如 Map 上的 for 循环可能指向 Map 保持顺序的假设,并且明确地阐明它对开发人员是有益的。 开发人员更喜欢自动化,也就是说,与其帮助调试易碎的测试,不如使用工具自动修复它们会更有益。
B. Case Study 2: Critique Notifications
C. Case Study 3: Google Issue Tracker Comments
D. Case Study 4: Usability of FD Reports
VII. CONCLUSION
回归测试是软件开发的关键部分。 回归测试套件中存在的不稳定测试会严重破坏一些软件开发活动。 因此,让开发人员快速修复它们很重要。
先前的工作研究了现有的软件系统,表明存在常见类别的片状测试,其中一些片状测试可以自动检测,而某些特定类型的片状测试,例如依赖于顺序的片状测试,可以自动修复
我们提出了 DIVERGENCE,这是一种新技术,可以自动识别片状测试的根本原因的位置。 我们在工具 FD 中实施并部署了这项技术,在 Google 的几个产品的片状测试中进行,并进行案例研究以评估其成功和有用性。
我们对 FD 对 83 个固定片状测试的准确性的评估表明,与开发人员提交的实际修复相比,它可以以 81.93% 的准确度指向涉及片状的相关代码的位置。 在另一项研究中,我们观察到开发人员没有动力去修复与其当前代码更改无关的不稳定测试,而是更愿意在专门的维护时间窗口内修复此类测试,例如修复。 在另一项研究中,我们将 FD 报告添加为对未决问题的评论,并观察到开发人员对将 FD 报告集成到他们的工作流程中持积极态度。 最后,我们对像 FD 这样的工具的开发人员的期望和看法的评估表明,一些开发人员发现报告难以理解,一些人希望该工具能够自动修复片状问题,而其他开发人员发现它有助于调试和修复他们的片状问题 测试,并希望报告通过提供有关片状类型和潜在修复的建议来走得更远。

若有收获,就点个赞吧
0 人点赞
