1. INTRODUCTION
Fuzzing 是一种动态分析技术,用于查找软件中的错误和漏洞,通过将目标程序置于大量(可能是格式错误的)输入中来触发目标程序的崩溃。
基于变异(Mutation-based)的模糊测试通常使用一组初始的有效种子输入,通过随机变异生成新种子。
由于它们的简单性和易用性,基于变异的灰盒模糊器,如 AFL [74]、honggfuzz [64] 和 libFuzzer [61] 被广泛部署,并且在发现大量错误方面取得了巨大成功。 这一成功促使人们对改进模糊测试过程的各个方面进行了大量研究,包括变异策略 [39, 42]、能量分配策略 [15, 25] 和路径探索算法 [14, 73]。
然而,虽然研究人员经常注意到高质量输入种子的重要性及其对模糊器性能的影响 [37, 56, 58, 67],但很少有研究解决基于突变的模糊器的语料库优化设计和构建问题 [56, 58 ],并且没有人评估这些语料库在覆盖引导的基于突变的灰盒模糊测试中的精确影响。
本文贡献:
- 对模糊器评估和部署中使用的种子选择实践和语料库最小化技术的系统回顾。
- 新的语料库最小化工具 OptiMin,可生成最佳最小语料库(第 4 节)。
- 各种种子选择实践的定量评估和比较。
2. FUZZING
模糊器(fuzzer)生成测试用例的方法有两种:
- generation-based
- 基于生成的模糊器(例如 QuickFuzz [29]、Dharma [47] 和 CodeAlchemist [30])需要输入格式的规范/模型。 他们使用此规范来合成测试用例。
- mutation-based
- 基于变异的模糊器(例如 AFL [74]、honggfuzz [64] 和 libFuzzer [61])需要种子输入(例如文件、网络数据包和环境变量)的初始语料库来引导测试用例生成。 然后通过改变这个语料库中的输入来生成新的测试用例
3. SEED SELECTION PRACTICES
本文检查了 2018 年以来发表的另外 28 篇论文,看看这些建议(papers should be specific about how seeds are collected)是否被采纳。 表 1 总结了我们的发现。
3.1 In Experimental Evaluation
Unreported seeds. 未报告的种子。 三项研究没有提到他们的种子选择程序。
Benchmark and fuzzer-provided seeds。三项研究(Hawkeye、FuzzFactory 和 Entropic)评估了 Google Fuzzer Test Suite (FTS) [26] 上的模糊器,四篇论文(AFL-Sensitive、PTrix、Savior 和 EcoFuzz)使用了 AFL 提供的单例种子集。
Manually-constructed seeds 两篇论文(Redqeen 和 Grimoire)使用“一种由可打印 ASCII 集中的不同字符组成的不知情的通用种子”[9]。
Random seeds。五篇论文(MOpt、Superion、FuZZan、GreyOne 和 TortoiseFuzz)从 (a) 特定目标的开发人员提供的更大的种子语料库中随机选择种子,或 (b) 通过爬行互联网。
Empty seeds. 八篇论文使用空种子来引导模糊测试过程。
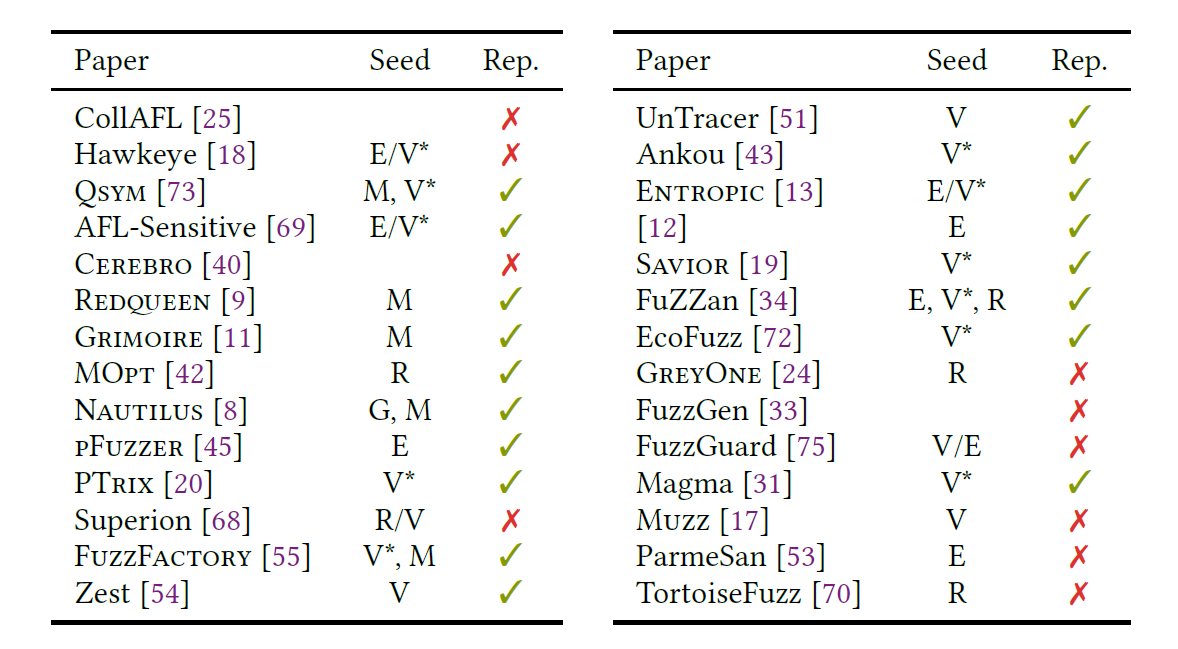
R : randomly sampled seeds;
M : manually constructed seeds;
G : automatically generated seed;
N : non-empty seed(s) with unknown validity;
V : the paper assumes the existence of valid seed(s), but with unknown provenance;
E : empty seeds;
blank : not mention
V* : validseed(s) with known provenance.
Rep : reproducible
总结:至少,模糊器评估必须报告用于引导模糊过程的种子集。 为确保可重复性,工件必须提供初始种子集(因为结果可能因所使用的种子而异)。 理想情况下,模糊器评估应该使用不同的初始种子语料库进行试验,以了解不同的初始种子如何影响模糊结果。
3.2 In Deployment
在工业规模部署模糊器时,必须从模糊队列中删除表现出冗余行为的种子,因为它们会导致浪费周期
4. CORPUS MINIMIZATION
5. EVALUATION
RQ1 How effective are corpus minimization tools at producing a minimal corpus? (Section 5.2)
RQ2 What effect does seed selection have on a fuzzer’s bug finding ability? Do fuzzers perform better when bootstrapped with (a) a small seed set (e.g., empty or singleton set), or (b) a large corpus of seeds, derived from an even larger collection corpus after applying a corpus minimization tool? (Section 5.3)
RQ3 How does seed selection affect code coverage? Does starting from a corpus that executes more instrumentation data points result in greater code coverage, or does a fuzzer’s mutation engine naturally achieve the same coverage (e.g., when starting from an empty seed)? (Section 5.4)
5.1 Methodology

若有收获,就点个赞吧
0 人点赞
