https://arxiv.org/abs/2002.03039
ABSTRACT
成功的跨语言克隆检测可以使研究人员和开发人员创建强大的语言迁移工具,在掌握了其他编程语言后促进学习其他编程语言,并促进代码片段在更广泛的代码库中的重用。 然而,识别跨语言克隆对克隆检测问题提出了特殊的挑战。 任意语言之间缺乏共同的底层表示意味着检测克隆需要以下解决方案之一:1) 跨每个目标语言复制的静态分析框架,注释匹配所有语言的语言特征,或 2) 动态分析框架,检测基于克隆的 关于运行时行为。 在这项工作中,我们证明了后一种解决方案的可行性,一种称为 SLACC 的动态分析方法,用于跨语言克隆检测。 与先前的克隆检测技术一样,我们使用输入/输出行为来匹配克隆,尽管我们通过放大输入数量和覆盖更多数据类型来克服先前工作的局限性; 因此,获得比先前尝试更好的集群。 由于集群是基于输入/输出行为生成的,因此 SLACC 支持跨语言克隆检测。 作为额外的挑战,我们针对静态类型语言 Java 和动态类型语言 Python。 与最近的 Java 克隆检测工具 HitoshiIO 相比,SLACC 检索的簇数是其 6 倍,并且具有更高的精度(86.7% 对 30.7%)。 这是第一个对动态类型语言执行克隆检测的工作(精度 = 87.3%),也是第一个跨缺乏通用底层表示的语言执行克隆检测的工作(精度 = 94.1%)。 它为实现可扩展语言迁移工具的更大目标迈出了第一步。
SIMION-BASED LANGUAGE-AGNOSTIC CODE-CLONE DETECTION
代码克隆可以大致分为四种类型 [36],如表 1 所述。类型 I、II 和 III 表示句法代码克隆,其中代码之间的相似性是根据代码结构来估计的。 另一方面,IV 型表示功能相似。 语法代码克隆检测技术对于跨语言代码克隆检测是不切实际的,因为它需要语言语法之间的显式映射。 这对于句法相似的语言(如 Java 和 C# [11])是可行的,但对于不同的语言(如 Java 和 Python)则困难得多。 另一方面,跨语言代码检测的语义方法 [33] 依赖于语言之间的大量训练示例,并再次在类似的编程语言上进行了测试。
我们提出了基于 Simion 的语言不可知代码克隆检测 (SLACC),这是一种基于冗余代码的大型存储库的可用性的代码相似性语义方法 [2]。 而不是使用预定义映射 API 翻译规则 [5, 11],或使用嵌入式 API 翻译 [4, 33],SLACC 使用 IO 示例根据其行为对代码进行聚类。 此外,它放宽了跨编程语言的数据类型界限,这有助于将动态类型代码片段(例如 Python)与静态类型代码片段(例如 Java)一起聚类。
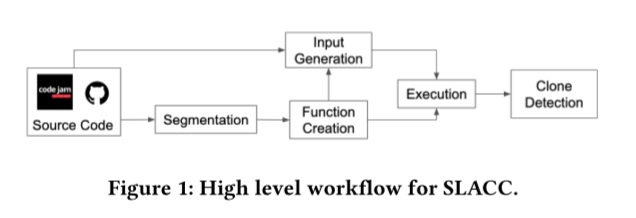
在 SLACC 中,我们建立在 EQMiner [20] 开创的思想之上,使用分割和随机测试进行克隆检测。 SLACC 从识别大型代码库中的片段开始,并涉及图 1 中描述的多步骤过程,该过程从 a) 将代码库分割成称为片段的较小代码片段,b) 从片段创建函数,c) 函数的输入生成,d) 函数的执行,以及 e) 基于聚类函数参数和执行结果的克隆检测。
1. Segmentation
在第一阶段,来自项目中所有源文件的代码被分解为更小的代码片段,称为片段。 阈值 MIN_STMT 或更多的连续语句块被分组到一个片段中。
语句块可以是
- Declaration Statement. e.g., int x;
- Assignment Statement e.g., x = 5;
- Block Statement e.g., static {x = 10;}
- Loop statements. e.g., for, while, do-while
- Conditional statements. e.g., if, if-else-if, switch,
- Try Statement. e.g., try, try-catch
算法 1 说明了分割阶段。 对于函数的 AST AF,该算法对 AST 中的所有节点执行前序遍历(第 5 行),然后使用滑动窗口提取大小大于最小段大小 MIN_STMT 的段(第 12-13 行) )。 此外,对于像 Block、Loop、Conditional 和 Try 这样在其嵌套范围内具有语句的语句,算法会在它们上递归调用(第 14-15 行)。
2. Function Creation
接下来,片段被转换为可执行函数。 本节介绍如何推断参数、返回变量和类型。
推断参数和返回变量。 我们采用类似于 Su 等人使用的数据流分析。 [40]。 对于每个方法,潜在的返回变量被标识为在代码片段范围内定义或修改的变量。 如果变量的最后定义是常量值,则该变量将从潜在返回变量集中删除。 参数是 1) 使用但未在代码段范围内定义的变量,以及 2) 未声明为类的公共静态变量的变量。 对于片段中的每个潜在返回变量,都会创建一个函数。
推断类型。 在静态类型语言的情况下,参数类型和返回值可以通过静态代码分析来推断。 对于动态类型语言,参数可以采用多种类型的输入参数。 这增加了生成的参数的可能值(参见第 3.3 节)以识别其行为。 在许多情况下,可以通过解析代码并在其上下文中查找常量变量 [7] 来推断参数的可能类型。 这种技术已用于推断其他动态语言(如 JavaScript [18])中的类型。在编译时无法推断参数类型的情况下,分配了泛型类型(即,对于 a),允许参数采用参数生成中使用的任何原始类型(第 3.3 节)。
将对象返回类型转换为函数。 如果一个片段返回一个对象,该对象被简化为多个返回的函数,它的每个非私人成员都是独立的。 例如,在图 2 中,func_s 的返回类型为 Shape。 形状有两个成员,长度和宽度。 因此,func_s 被分解为两个函数,func_l 和 func_w,它们独立地返回形状对象的长度和宽度。 请注意,没有创建第三个 height 函数,因为它是私有成员。
置换参数顺序。 对于每个片段,我们根据参数的输入生成不同的排列,因为顺序对于捕获函数行为很重要。 考虑图 3 中的两个函数; 第一个函数使用除法 (/) 运算符将 a 与 b 相除,而第二个函数使用减法 (-) 运算符递归地将被除数与除数相除。 对于输入 (5, 2),这两个函数将分别产生值 2 和 0。 但是如果第二个函数的参数被反转,它会产生相同的输出 2。因此,对于每个函数,我们在参数的不同排列中创建重复项,ARGS,导致 |ARGS|! 不同的功能。 为了限制这种爆炸空间的创建,我们为分析中包含的每个函数的参数数量设置了上限 (ARGS_MAX)。
3. Input Generation
执行创建的函数需要一组输入。 在此之后,执行聚类。
输入创建。 输入是基于参数类型生成的,并使用受灰盒测试 [23] 和多模态分布( multi-modal distribution) [20] 启发的自定义输入生成器。 首先,解析源代码并确定每种类型的常量。 接下来,为在常数处具有峰值的每种类型声明多模态分布。 最后,从这个多模态分布中采样每种类型的值。 我们的实验为每个函数创建了 256 个输入,如第 6.1 节所述。
存储。 对于具有相同参数类型的每个函数,必须使用一组公共输入来比较它们。 这是使用数据库和输入生成器来确保的。 生成器用于为给定的参数类型创建示例输入并存储在数据库中。 对于参数具有相同签名的后续函数,将重用存储的输入值。
支持的参数类型。 SLACC 目前支持四种类型的参数。
(1) 基本类型。 对参数类型的多模态分布进行采样以生成输入。 这包括整数(和长整数、短整数)、浮点数(和双精度数)、字符、布尔值和字符串。
(2) 对象。 对象被递归扩展为具有基本类型的构造函数; 为这些基本类型生成输入。
(3) 数组。 使用整数输入生成器生成随机数组大小。 对于数组中的每个元素,都会根据数组类型(基本类型或对象)生成一个值。
(4) 文件:文件作为字符串的共享资源池存储在数据库中。 如果提供了种子文件,它会随机变异并作为字符串存储在数据库中。 在没有种子的情况下,来自多模态分布的常数被采样并存储为字符串。 对于具有文件类型(或其扩展名)的参数,使用存储的字符串创建临时(终止时删除)文件对象。
类型大小限制。 比较代码片段需要跨编程语言兼容大小的类型。 例如,Java 有 4 个整数数据类型 byte、short、int 和 long,它们分别占据 1、2、4 和 8 个字节的大小。 另一方面,Python 有两种整数数据类型:相当于 Java 中的 long 数据类型的 int 和具有无限长度的 long。 因此,我们在为不同语言的函数生成输入时做了一个限制:输入是从两种编程语言中较小的边界生成的。 例如,对于具有 int 的 Java 和 Python 函数,输入是在 Java 的边界内生成的
4. Execution
在下一阶段,在生成的输入集上执行创建的函数,并存储随后的返回值。 每个函数都被分配了一个 TL 秒的执行时间限制,之后会引发超时异常。 当存在无限循环时,这种情况最常发生,例如 while(true) 当循环不变量是参数时。 函数的每次执行都在一个独立的线程上运行。 随后,存储在输入集上执行的函数的返回值、运行时间和异常。
5. Clone Detection
SLACC 的最后一个阶段是识别克隆,其中执行的函数在它们的输入和输出上聚集。 SLACC 使用基于代表性的分区策略 [36, 40] 来对执行的函数进行聚类。
相似性度量。 在这项工作中,如果对于任何给定的输入,函数对返回相同的输出,则这对函数在语义上具有最高的相似性。 两个函数之间的相似性度量计算为方法返回相同输出值的输入数量除以输入数量,与 Jaccard 指数相同。 这会在两个函数之间创建一个相似度值,范围为 [0.0, 1.0],其中 1.0 是最高的。
考虑第 2 节中的函数 interleave、fancy_interleave 和有关 a = [2,3]fancy_interleave(a,b) = [2,4] 和 valid_interleave 的值。 b = [4],我们交错(a,b) = [2,4,3],并且valid_interleave(a,b) = [2,4,3]。 函数 interleave 和 valid_interleave 是相似的,因为它们对于相同的输入具有相同的输出,但 interleave 和 Fantasy_interleave 不相似。 相反,对于 a = [2,3] 和 b = [4,5],所有三个函数都将返回相同的输出 [2,4,3,5]。 基于这两个输入,interleave和fancy_interleave的相似度为0.5,interleave和valid_interleave的相似度为1.0,fancy_interleave和valid_interleave的相似度为0.5。 对许多这样的输入 a 和 b 重复这个过程,以计算每对函数之间的相似性分数。 仅当函数具有相同数量的参数和可转换参数类型时才进行比较。 例如,考虑四个函数 f1(int a, String b)、f2(long a, File b)、f3(File a, String b) 和 f4(String a)。 函数 f1 和 f2 可以进行比较,因为 int 可以转换为 long 值。 但是它们不能与 f3 进行比较,因为基本类型不能转换为 File。 同样,由于参数数量的不同,f1、f2 和 f3 无法与 f4 进行比较。
聚类。 通过测量函数与添加到集群的第一个函数(称为代表)的相似性,将函数与集群进行比较。 算法 2 中简要描述了聚类算法。首先初始化一个空的聚类集(第 4 行)。 每个函数(第 5 行)与每个集群(第 6 行)进行比较。 如果代表(第 7 行)与函数之间的相似性大于预定义的相似性阈值 SIM_T(第 8 行),则将该函数添加到聚类中(第 9 行)。 如果该函数不属于任何集群(第 11 行),则为该函数创建一个单例集群(第 12 行)并将函数设置为集群的代表(第 13 行)。 将单例集群添加到集群集中(第 14 行)
EVALUATION
1. Research Questions
- How effective is SLACC on semantic clone detection in static typed languages?
- How effective is SLACC on semantic clone detection in dynamic typed languages?
- How effective is SLACC at cross-language semantic clone detection?
2. DATA
我们对来自Google Code Jam(GCJ)存储库的四个问题以及它们在Java和Python中的有效提交进行了验证。GCJ是由谷歌主办的一年一度的在线编码竞赛,参赛者将解决所提供的编程问题,并将其解决方案提交给谷歌进行测试。通过谷歌测试的提交被认为是有效的,并在网上发布。我们使用2011年至20142年第五轮GCJ的第一道题。有关问题和提交材料的详细信息见表2。总体而言,我们考虑了247个项目;170来自Java,77来自Python。170份JavaGCJ提交包含885个方法和19188个Java函数。77 Python提交包含301个方法和17215个Python函数。该项目的代码、项目和执行脚本可以在我们的GitHub存储库中找到[28]。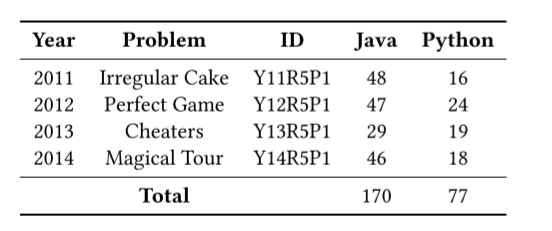
3. Experimental Setup
实验在16节点集群上运行,每个节点都有一个4核AMD opteron处理器和32GB DDR3 1333 ECC DRAM。我们的实验有四个超参数
- 片段的最小大小(MIN_STMT-Section 3.1):我们将其设置为2以捕获具有有趣行为的片段。
- 最大参数数(ARG_MAX-第3.2节):该值设置为5。因此,如果一个代码段有5个以上的参数,则会从实验中忽略它。
- 执行次数(第3.4节):我们使用256个生成的输入执行每个代码段(第3.3节);有关此选择的详细信息,请参见第6.1节。
- 相似性阈值(SIM_T-第3.5节):我们在实验中将其设置为1.0。这意味着只有当两个函数为所有输入生成相同的输出时,它们才被视为克隆。
4. Baselines
- HitoshiIO
- Automated AST Comparison
- Manual Cross-language AST Comparison.

若有收获,就点个赞吧
0 人点赞
