文章地址 http://qiyuhua.github.io/publications/icse2014-qi.pdf
ABSTRACT
自动程序修复最近受到了相当多的关注,并且已经提出了该研究领域的许多技术。 其中,两种基于基因编程的技术 GenProg 和 Par 已显示出可喜的结果。 特别是,在许多文献中,GenProg 已被用作检查新技术修复效果的基准技术。 尽管 GenProg 和 Par 在修复非平凡程序中的实际错误方面表现出强大的能力,但 GenProg 和 Par 可以在多大程度上受益于基因编程,用于指导补丁搜索过程,仍然是未知数。 为了解决这个问题,我们提出了一种新的使用随机搜索的自动修复技术,这通常被认为比遗传编程简单得多,并实现了一个名为 RSRepair 的原型工具。 对 7 个带有实际错误的 24 个版本的程序进行的实验表明,在大多数情况下 (23/24),RSRepair 在修复有效性(需要更少的补丁试验)和效率(需要更少的测试用例执行)方面都优于 GenProg, 证明随机搜索比遗传编程更强大。 根据实验结果,我们建议使用优化算法提出的每一种技术都应通过与随机搜索进行比较来检查其有效性。
1. INTRODUCTION
研究人员对自动化程序修复领域投入了相当多的关注[22,13,20],旨在在无需手动操作的情况下为故障感知程序自动生成补丁。 通过自动程序修复,可以在软件维护活动中节省大量资源成本,而补丁生成是一项必不可少的任务。 最近,研究人员提出了几种技术来自动化补丁生成过程[21、18、27、3、28、25、1、7、16]。
在这些技术中,一种特别有效的方法是基于基因编程的补丁生成技术。 分别在 ICSE 2009 和 ICSE 2013 中获得杰出奖项的 GenProg [40] 和 Par [18] 通过使用相同的遗传编程算法来指导补丁生成过程,显示出非常有希望的结果。 为了修复错误的程序,GenProg [40] 及其扩展 [23,21,38] 试图通过根据突变和交叉重用结构修改源代码,即语句添加、删除,在每一代中产生一组候选补丁 和替换,在程序的其他部分。 一旦候选补丁可用,GenProg 必须运行固定大小的测试用例来评估每个补丁的适用性,以促进下一代补丁的生成。 GenProg 迭代上述步骤,直到获得通过所有测试用例的某个有效补丁,或者当某个限制(即,经过太多时间或经过太多代)到达时。 Par 具有类似的补丁生成过程,但通过从人工编写的补丁中学习的修复模式生成候选补丁,而不是通过 GenProg 使用的代码重用。
GenProg 和 Par 提出的两个主要贡献是 1) 有效的变异操作(即 GenProg 的重用结构和 Par 的修复模式),以及 2) 使用遗传编程来指导补丁生成过程。 尽管 GenProg 和 Par 已显示出有希望的修复能力,但修复能力是基于基因编程的指导还是仅仅因为突变操作强大到足以容忍基因编程的不作为而获得的修复能力却鲜有研究。 如 [4, 15, 14] 中所述,我们可以认为遗传编程在指导修复过程方面是有效的,当且仅当遗传编程可以指导修复过程更快地搜索有效补丁,就需要更少的补丁试验而言 ,而不是随机搜索。
此外,与其他基于搜索的软件工程 (SBSE) [15, 14] 方法类似,遗传编程经常受到适应度评估导致的计算成本高昂的影响,这是用于区分更好和更差解决方案的必要活动。 在大多数情况下,适应度的计算(通过为每个候选补丁运行固定大小的测试用例)占据了整个修复过程的最大部分 [15, 23]。 因此,我们应该研究 GenProg 和 Par 使用的遗传编程是否可以足够快地引导补丁搜索以抵消适应度评估的成本,从而加快修复过程,即使最终证明遗传编程是有效的。
鉴于上述问题,我们构建了一个名为 RSRepair(Random-Search-based Repair)的新修复工具,它尝试使用与 GenProg 相同的变异操作来修复错误程序,但使用随机搜索而不是遗传编程来指导补丁生成 过程。 与需要适应度评估的遗传编程不同,GenProg 必须运行固定大小的测试用例来计算候选补丁的适应度,即使 GenProg 已经意识到补丁无效(即,补丁程序从未通过 一些测试用例),随机搜索没有这样的约束。 也就是说,一旦修补程序未能通过某个测试用例,RSRepair 会立即丢弃一个候选补丁。 因此,对于一个具体的补丁,RSRepair 可以花费更少的测试用例执行来检查其有效性。 此外,RSRepair 的第二个优势是 RSRepair 可以使用经典的测试用例优先级技术 [43, 30] 加快早期无效补丁识别的过程。 然而,将优先级技术应用于 GenProg 几乎没有意义,即使早期发现一些补丁无效,它仍然需要计算每个补丁的适应度。
实验结果表明,RSRepair 的性能远优于 GenProg。 在我们的实验中,我们通过运行 RSRepair 和 GenProg 来修复一组 7 个具有 24 个实际错误版本的非平凡程序,从而将它们进行了比较。 通过严格的统计分析,我们观察到 1)RSRepair 在大多数情况下,在找到有效补丁之前生成的候选补丁数量(NCP)要求较少,这表明使用的遗传编程算法具有更好的修复效果。 GenProg 的工作效果不佳,甚至误导了搜索过程,这证实了 Andrea Arcuri 和 Lionel Briand 在他们的 ICSE 2011 论文 [4,第 3 页] 中对 GenProg 使用的基因编程提出的关注,2) RSRepair 具有更高的修复效率 在修复过程中需要更少的测试用例执行
在我们早期的工作 [31] 中,我们通过有限的实验展示了我们的见解。 在本文中,我们将详细介绍我们的工作以及对更多实验规模的分析。 简而言之,本文做出以下贡献:
- 使用最简单的随机算法(即随机搜索)来实现称为 RSRepair(第 3 节)的修复工具,该工具的性能大多优于 GenProg,GenProg 是一种使用遗传编程指导补丁搜索的最先进的修复工具。
- 分析实验结果并讨论这些结果对一般自动化程序修复领域未来研究的影响(第 5 节和第 6 节)。
- 在自动化程序修复的有前途的研究领域中提出基于随机搜索的基线方法,该领域仍处于起步阶段。 我们建议应始终将高级修复方法与至少基线方法进行比较,以检查新方法的优势,这与 [4, 15, 14] 中提出的声明一致
2. BACKGROUND AND RELATEDWORK
2.1 Automated Program Repair
通常,自动程序修复包括三个步骤:
- 故障定位 [42、17]
- 补丁生成
- 补丁验证。
报告错误时,我们首先使用故障定位技术来识别导致错误的可疑错误代码片段。 一旦找到了错误的代码片段,就可以根据基于进化计算 [21, 3, 18] 或基于代码的合同 [37] 的特定修复规则,通过修改该代码片段来生成许多候选补丁。 当一个候选补丁已经产生时,回归测试,包括负面测试用例(重现故障)和正面测试用例(表征正常行为),通常用于验证产生的候选补丁的正确性。 上述过程可以一遍又一遍地迭代,直到找到一些有效的补丁。 通过所有这些测试用例的任何补丁都被认为是有效的。
自动化修复技术最近受到了相当多的研究关注。 在遗传编程的指导下,GenProg 具有修复程序的能力,无需任何规范,GenProg 通常被认为开辟了通用自动化程序修复的新研究领域 [26, 20],尽管更早存在(例如 [5, 2 ]) 以及关于该主题的并行工作 [6]。 AutoFix-E [37] 可以修复程序,但需要合同的前置和后置条件。 JAFF [3] 尝试使用进化方法自动纠正错误的 java 程序; JAFF 的修复效果没有报告在具有真正错误的真实软件上。 PHPRepair [35] 可以通过字符串约束解决自动修复 php 应用程序中的 HTML 生成错误。 根据从人工编写的补丁中学习的修复模板,Par [18] 已成功修复了现实世界 Java 程序中存在的许多错误。 SemFix [27] 尝试通过基于符号执行、约束求解和程序综合的语义分析来修复错误的 C 程序; 然而,由于语义分析可能导致计算成本高昂,SemFix 是否能很好地扩展到大型程序仍是未知数。
在这些技术中,GenProg 和 Par 这两种屡获殊荣的补丁生成技术展示了非常有希望的结果。 GenProg 和 Par 都使用相同的故障定位技术来定位错误语句,并使用遗传编程来指导补丁搜索,但在具体的变异操作上有所不同。 尽管他们的工作已经显示出有希望的结果,但有希望的结果是由遗传编程引起的还是仅仅因为使用的变异操作非常有效的问题仍然没有得到解决。
2.2 Genetic Programming and Random Search
遗传编程是众所周知的遗传算法的一种变体,旨在发现为特定任务量身定制的计算机程序。 与传统的遗传算法类似,遗传编程使用诸如选择、交叉和变异等遗传操作来进化其种群以获得一些更适应的解决方案[15]。 在自动化程序修复的研究领域,GenProg 是一种很有前途的自动化解决方案,旨在自动和通用地修补软件维护中的错误 [20]。 GenProg 使用遗传编程算法来指导补丁生成过程。 如 [15] 中所述,GenProg 在应用遗传编程之前需要实现两个关键要素:1)解决方案的表示和 2)适应度函数的定义。 对于表示问题,GenProg 将每个候选补丁表示为补丁程序的抽象语法树(AST)。 对于适应度函数,GenProg 使用测试用例来评估每个补丁的适应度,通过许多测试用例的适应度高的补丁被选择用于下一代继续进化。 也就是说,对于每个候选补丁,GenProg 必须运行固定大小的测试用例来计算适应度。
相比之下,随机搜索是 SBSE 文献中经常出现的最简单的搜索算法,它不使用适应度函数,因此不会产生适应度评估的成本。 事实上,GenProg 根据随机搜索算法产生了第一批候选补丁,遗传编程从第二代开始在 GenProg 上工作。 然而,Andrea Arcuri 和 Lionel Briand 发现 GenProg 经常在实际进化搜索开始工作之前,在第一个种群的随机初始化中搜索有效补丁。 他们怀疑 GenProg 使用的基因编程可能不会带来有希望的结果,因为当随机搜索可能产生类似结果时,补丁搜索问题可能很容易。 然而,在本文中,我们计划进一步研究 GenProg 使用的遗传编程是否比随机搜索具有更好的性能,当实际的进化搜索开始起作用时
2.3 Test Case Prioritization
如前所述,随机搜索是无指导的,因此不需要适应度评估。 特别是对于自动修复,对于随机搜索,一旦补丁被认为是无效的,就可以立即丢弃一个候选补丁。 虽然我们可以通过回归测试或正式规范来检查一个补丁是否有效,但回归测试最常使用,因为在实践中很少有正式规范可用。 在不需要适应度评估的情况下,我们可以通过最大化无效补丁检测率来加速补丁验证过程,这在测试用例优先级领域得到了很好的研究。
如 Rothermel 等人在 [34] 中所述,测试用例优先级问题可以定义如下:
在上述上下文中,PT 表示 T 的所有可能排序的集合; f 是一个转移函数,用于评估任何 PT 排序的奖励值。 事实上,f 定量地描述了优先级划分的目标,例如提高测试套件的故障检测率或以更快的速度增加被测系统中可覆盖代码的覆盖率。
测试用例优先级的技术相对成熟,在[43]中已经做了很多工作。 根据不同的覆盖标准,[34] 中提出了一系列优先级技术。 一些研究工作在时间感知测试用例优先级[44]的背景下评估了测试用例优先级的传统技术。 此外,还有很多工作集中在不同的粒度级别,例如功能级别[9]、系统模型[19]、块级别和方法级别[8]。 [43] 中列出了有关优先级技术的更多细节。
3. IMPLEMENTATION
我们已经实现了一个名为 RSRepair 的修复工具,它可以通过使用纯随机搜索算法为有故障的程序自动生成补丁。 RSRepair 还配备了一种经过调整的测试用例优先级技术,以加快补丁验证过程。 在本节中,我们首先描述 GenProg,这是一种用于自动 C 程序修复的最先进工具,我们在此基础上构建了 RSRepair。 然后,我们介绍 RSRepair 的实现细节。
3.1 Repair Algorithm for GenProg
GenProg2 能够在没有正式规范的情况下修复已部署的遗留 C 程序中的错误。 假设某些遗漏的重要功能可能出现在同一程序的另一个位置,GenProg 尝试使用遗传编程自动修复有缺陷的程序 [38]。 算法 1 [21] 给出了 GenProg 的补丁生成过程。
考虑一个带有一组测试用例 T 的错误程序 P,在第 1 行,GenProg 首先根据测试用例覆盖信息定位错误代码区域 Csub。 然后,第 2 行通过使用纯随机搜索独立地变异 Csub 的 PopSise 副本来初始化人口 Pop。 一旦 Pop 可用,通过 SampleFit 计算每个补丁 pt ∈ Pop 的适应度,从而得到适应度集 Fitnesses。 具有高适应度的补丁有更多的机会被选入下一代(第 5 行)以使用交叉(第 6 行)和变异(第 7 行)操作继续进化。 重复第 4-7 行,直到找到有效补丁成功通过 FullFitness 或某些预定限制已经过去。 有关 GenProg 的更多详细信息可以在 [21] 中找到。
3.2 Repair Algorithm for RSRepair
与我们之前的工作[30]类似,我们设计了 RSRepair 的修复算法,使用纯随机搜索算法结合测试用例优先级技术自动生成补丁,以提高修复效率。 算法 2 [30] 详细描述了修复算法。
给定一个错误程序 P 和测试用例 T,我们重构测试用例 T 以使 T 能够将每个测试用例 t ∈ T 映射到已被 t 杀死的候选补丁的数量。 这种重构背后的直觉是,被测试用例 t 杀死的候选补丁的数量至少部分地表明了 t 检测无效补丁的能力。 因此,我们应该优先考虑杀死更多无效补丁的测试用例,以最大限度地早期检测无效补丁。 请注意,在第 3 行 RSRepair 将 n0(一个负测试用例)的索引值初始化为 1,因为它具有自然的故障再现能力。
为了限制生成补丁的搜索空间,我们以与 GenProg 相同的方式定位 P 的错误代码区域 Csub。
搜索从通过 Mutate 操作生成一个补丁 pt 开始,通过修改 Csub 可以生成一个具体的补丁 pt。 请注意,由于随机算法的应用,多次调用 Mutate 产生的补丁可能不同。 第 8-20 行按顺序对 T 运行 P,并根据运行结果对测试用例 T 重新排序。 给定 T 的第 i 个测试用例,第 10 行调用函数 GetTestcase 来获取 T 的第 i 个元组 (tindex, index); 然后,函数 PatchValidation 针对 tindex 运行 P 由 pt 修补(第 11 行); 如果 tindex 检测到故障,则 RSRepair 通过使用 (tindex, index + 1) 更新元组 (tindex, index) 来记录故障(第 12 行),并通过调用函数 Prioritize 对每个测试用例 t ∈ T 重新排序 (第 13 行),它将测试用例 T 按索引的降序重新排序。 (如果多个测试用例具有相同的索引值,RSRepair 将它们随机排序。)如果 P 成功通过所有测试用例 T(第 16 行),则 RSRepair 认为找到了有效补丁(第 16 行),并立即终止修复过程 输出有效补丁(第 22 行)。
3.3 Implementation of RSRepair
根据算法2,我们通过修改用OCaml语言编写的GenProg来实现RSRepair。 具体来说,RSRepair 在算法 2 中使用了与算法 1 中的 GenProg 相同的函数实现,包括 FaultLocalization 和 Mutate。
RSRepair 使用在 GenProg 中实施的一种简单统计故障定位来确定故障定位。 假设否定测试用例访问的语句比其他语句更有可能出错,RSRepair 以如下方式计算每个语句的可疑值 sp:任何否定测试用例从未访问过的语句的 sp 值为 0; 仅由负测试用例访问的语句具有 1.0 的高值; 正负测试用例都访问过的语句被赋予中等值 0.1。 RSRepair 根据这些可疑值确定每个语句的概率; 一个语句的可疑值越大,该语句在补丁生成过程中被选中进行变异的机会就越大。
一旦选择了一些语句进行变异,RSRepair 将根据变异操作,即语句添加、删除和替换,随机变异这些语句,生成一个候选补丁。 这种突变已被证明在成功修复 [21] 中 105 个故障程序中的 55 个方面非常有效。
事实上,RSRepair 生成候选补丁的方式与第一代 GenProg 中随机生成补丁的方式相同,但在后续世代中没有适应度指导和交叉。 对于补丁验证过程,RSRepair 以算法 2 中描述的方式验证候选补丁。
4. EXPERIMENTAL DESIGN
为了检查 RSRepair 的性能,我们将它与 GenProg(一种最先进的自动程序修复工具)在 7 个主题程序和 24 个错误版本上进行了比较。 我们之所以选择 GenProg,是因为 GenProg 几乎是唯一可以修复现实世界中大规模 C 程序中的错误的最先进的自动修复工具。 尽管在论文 [18] Par 在 Java 基准测试中的性能优于 GenProg,但该论文也承认在 GenProg 使用的 C 基准测试中可能不具备性能优势。 更重要的是,与Par的源代码不公开不同,GenProg的源代码和实验基准都是公开的,便于RSRepair和GenProg之间的实验复制和比较。 此外,文献 [11] 和我们之前的工作 [32, 33] 也使用 GenProg 作为唯一工具进行相关实验。
4.1 Research Questions
RQ1:与 RSRepair 相比,GenProg 是否可以通过更少的补丁试验来搜索有效补丁?
直观地说,遗传编程是一种高级搜索算法,应该优于纯随机搜索(最简单的搜索算法),因为借助适应度函数可以更快地找到更高质量的解决方案。 然而,直觉是建立在这样的假设之上的,即适应度函数至少可以部分区分更好和更差的解决方案,并确定候选解决方案与最优或接近最优解决方案的接近程度。 一个较差的适应度函数不能使搜索过程受益,甚至会产生负面效果。 特别是对于 GenProg,每个候选补丁的适应度是通过计算通过测试用例的加权数量来计算的; 该数字用于衡量候选补丁与有效补丁的接近程度。 尽管最近的一些系列论文 [40, 23, 21, 38, 10, 22] 已经介绍了 GenProg 的一些有希望的结果,但是有希望的结果是基于遗传编程的指导还是仅仅因为变异操作的问题 强大到足以容忍使用的适应度函数的不准确性从未被研究过。
鉴于这个问题,RQ1 询问 GenProg 使用的基因编程是否能很好地有利于有效补丁的生成。 Andrea Arcuri 和 Lionel Briand [4] 指出,搜索算法应始终与至少随机搜索进行比较,以检查搜索算法的执行情况,这可以通过比较搜索算法和随机搜索之间的工作量来衡量 . 正如 Mark Harman 在 [15] 中所描述的,这项工作通常是通过计算在搜索过程中执行的适应度评估(即补丁试验)的数量来衡量的。 数字越小,搜索算法越好。 然而,在最近分别在 ICSE 2012 和 ICSE 2013 上发表的关于 GenProg [21] 和 Par [18] 的工作中,我们仍然没有发现遗传编程和随机搜索之间的努力比较。 从这个意义上说,RQ1 是对这些工作的补充。
RQ2:GenProg 在成功修复过程中需要更少的测试用例执行 (NTCE) 次数方面是否比 RSRepair 更快地找到有效补丁?
与 SBSE 的其他启发式算法(例如爬山和模拟退火)一样,使用遗传编程有好处也有代价。 好处是在适应度函数的帮助下需要更少的补丁试验(如果使用的适应度函数运行良好)。 代价是遗传编程的试错性质需要在搜索过程中进行大量的适应度评估; 适应度评估可能会在计算上变得昂贵并且占据搜索过程的总体计算成本的最大部分 [15]。 遗传规划算法的有效实现应该有效地扩大收益以抵消评估成本,并进一步降低搜索过程中的整体时间成本。
特别是对于 GenProg,它通过计算通过测试用例的加权数量来计算每个候选补丁的适应度,测试用例执行通常占用整个修复过程中最大的时间成本 [23,图 8],尤其是在安全方面 - 配备许多测试用例的关键程序。 为简化起见,我们可以在找到有效补丁时使用 NTCE 测量 GenProg 的效率 [39]。 与随机搜索相比,GenProg 使用的遗传编程只有在遗传编程带来的收益(在早期找到有效补丁的数量较少的补丁试验方面)具有平衡适应度成本的能力时,才能被认为是有效的。 评估,由基因编程本身引起。 不过,GenProg 使用的基因编程能否达到平衡,目前还不得而知。 RQ2 旨在回答这个问题。
4.2 Subject Programs
我们选择在 GenProg 的最新工作 [21] 中使用的主题 C 程序作为实验基准 3,每个基准都带有历史版本中存在的真实错误。 我们仅对 GenProg 在 [21] 中成功修复的程序版本进行了实验。 对于fbc程序版本,我们在尝试编译程序时遇到了编译问题。 为简单起见,我们还排除了通过修改不少于两个源文件(即.c文件)可以成功修复的故障版本(包括1个lighttpd版本和2个libtiff版本),因为要制作CIL必须做额外的工作 ,一个可以将 C 程序转换为 AST 的工具,GenProg 和 RSRepair 都可以使用,可以很好地处理多源文件。
对于带有超过 4,000 个测试用例的 php 程序,仅验证一个已修补的程序通常需要几分钟,导致修复过程非常耗时。 因此,如果我们对所有的 php 程序版本进行实验,实验评估所花费的时间过多是不可避免的(参见 [21,表 II]); 在论文 [21] 中,亚马逊的 EC2 云计算基础设施(包括 10 个并行试验)用于实验评估。 考虑到昂贵的测试计算,我们随机选择了一个有缺陷的 php 版本,尽管这些 php 版本附带了许多测试用例,这会给 GenProg 带来昂贵的适应度评估成本,但会给 RSRepair 带来更多优势。 对于gmp、python、gzip和wireshark,只有一个版本被GenProg在[21]中成功修复过; 我们在我们的主题课程中选择了这些版本。
表 1 总共详细描述了我们的 7 个主题程序和 24 个版本。 LOC(Lines Of Code)列列出了每个主题程序的规模,最后两列给出了正面测试用例的大小和版本信息。 请注意,对于表 1 中的所有程序,尽管 [21,表 I] 中列出了更多测试用例),但实际上每个错误版本使用的测试用例的具体数量相似但不同,因为并非所有测试用例都运行良好 对于每个版本。 此外,对于每个主题程序,我们通过在修复过程中执行一个否定测试用例来重现错误。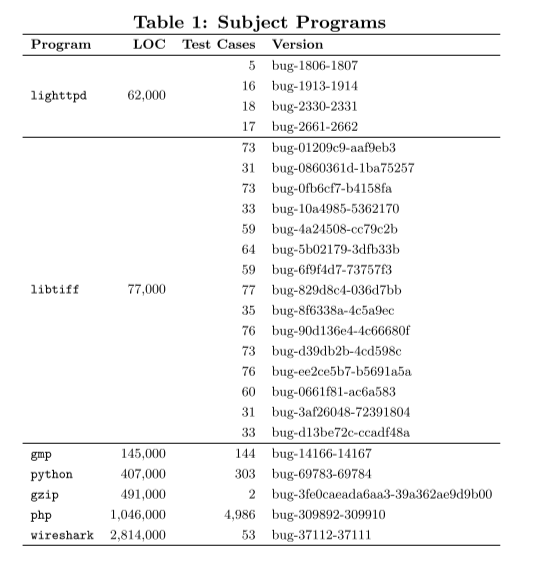
4.3 Experimental Setup
为了比较,我们分别运行 RSRepair 和 GenProg 来修复表 1 中描述的所有 24 个故障版本。我们实验中 GenProg 的所有实验参数与 [21] 中的设置相似:我们限制了人口规模 每代最多40代,每个修复过程最多10代; 全局静音率静音设置为 0.01。 事实上,对于除第一代以外的所有代,由于交叉产生了另外 40 个候选补丁。 也就是说,对于一个具体的修复过程,GenProg 可以迭代生成不超过 40+809=760 个候选补丁。 对于 RSRepair,我们也将每代的种群大小限制为 40 代,每个修复过程最多 10 代; 对于每一代,使用随机搜索(无交叉)以与第一代相同的方式产生总共 40 个候选补丁。 因此,为了公平比较,我们认为如果在 4010=400 个候选补丁中没有找到有效补丁,则 RSRepair (GenProg) 无法在一个修复过程中修复一个主题程序。
如 [24, 21] 中所述,当程序配备许多测试用例时,适应度函数(即算法 1 中的 SampleFit 函数)随机抽取 10% 的正测试来计算适应度:GenProg 测试一个候选补丁 如果补丁通过了所有采样的测试用例,则完整套件。 以 python 为例,表 1 中有 303 个测试用例,GenProg 必须针对总共 31 个测试用例(包括 30 个采样的阳性测试和 1 个阴性测试)运行打补丁的 python,以计算一个候选补丁的适应度; 如果修补后的 python 通过了上述所有 31 个测试用例,则它会针对完整的 303 个测试用例进行测试。 在我们的实验中,我们使用与上述相同的适应度评估机制运行 GenProg。
所有实验都在 Ubuntu 10.04 机器上运行,该机器具有 2.33 GHz Intel 四核 CPU 和 4 GB 内存。 由于 RSRepair 和 GenProg 都应用了随机算法,我们对实验结果进行了统计分析。
具体来说,对于 RSRepair 和 GenProg,我们分别对每个程序进行了 100 次试验,种子从 0 开始到 99 结束,并且只记录导致成功修复的试验。
5. EXPERIMENTAL RESULTS
我们首先在表 2 中展示实验结果,该表报告了提取信息的汇总统计数据。 第 3 列和第 4 列分别列出了每个程序的测试用例执行次数 (NTCE) 的平均值和中位数。 第 5 列给出了每个程序成功修复的平均时间。 第 6 列显示了使用一个修复工具修复每个程序时的成功率。 回想一下,在我们的实验中,我们分别对 24 个版本的 7 个程序中的每一个运行了 RSRepair 和 GenProg 100 次。 因此,如果有 n 次成功的试验,成功率为 n%; 表 2 中的所有其他统计数据均根据 n 次成功试验计算得出。 第 7 列报告了 RSRepair 和 GenProg 在 NTCE 上的差异的影响大小,第 8 列中显示了 p 值。 接下来,我们使用我们的研究结果来解决两个研究问题(第 4.1 节)。

若有收获,就点个赞吧
0 人点赞
