概念
和树比起来,图是一种更加复杂的非线性表结构。树中的元素称为节点,图中的元素就叫作顶点(vertex),图中的一个顶点可以与任意其他顶点建立连接关系。把这种建立的关系叫作边(edge)。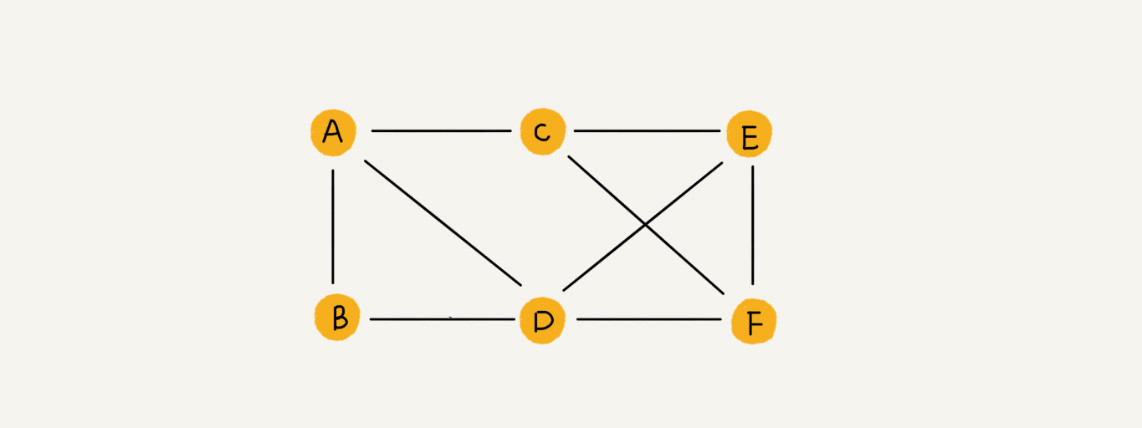
社交网络微博、微信等存储好友关系,就是一个非常典型的图结构。可以把每个用户看作一个顶点。如果两个用户之间互加好友,那就在两者之间建立一条边。所以好友关系就可以用一张图来表示。其中每个用户有多少个好友,对应到图中,就叫作顶点的度(degree),就是跟顶点相连接的边的条数。同时用户 A 关注了用户 B,但用户 B 可以不关注用户 A。这时就要稍微改造一下图结构,引入边的“方向”的概念,把这种边有方向的图叫作“有向图”。把边没有方向的图就叫作“无向图”。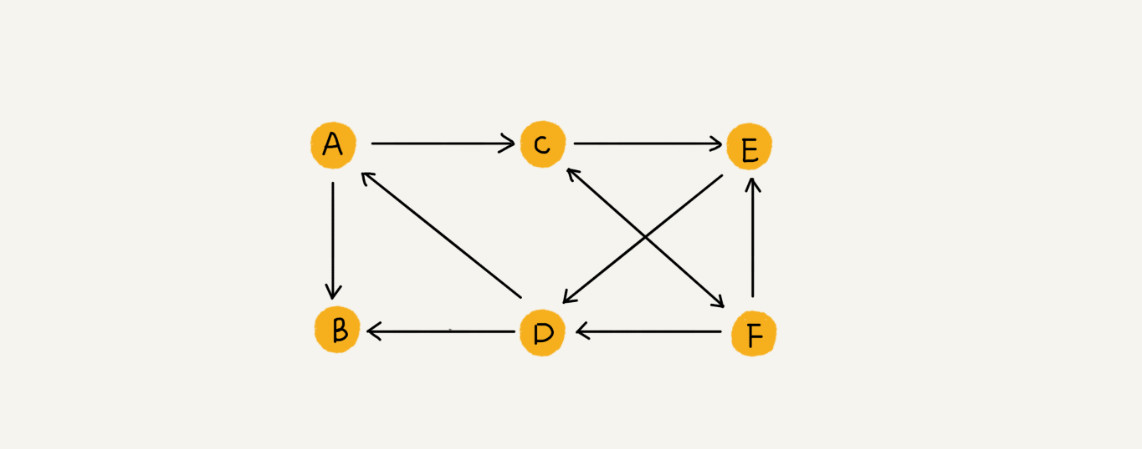
无向图中有“度”这个概念,表示一个顶点有多少条边。在有向图中,把度分为入度(In-degree)和出度(Out-degree)。顶点的入度,表示有多少条边指向这个顶点;顶点的出度,表示有多少条边是以这个顶点为起点指向其他顶点。对应到微博的例子,入度就表示有多少粉丝,出度就表示关注了多少人。
带权图(weighted graph)。在带权图中,每条边都有一个权重(weight),可以通过这个权重来表示 QQ 好友间的亲密度: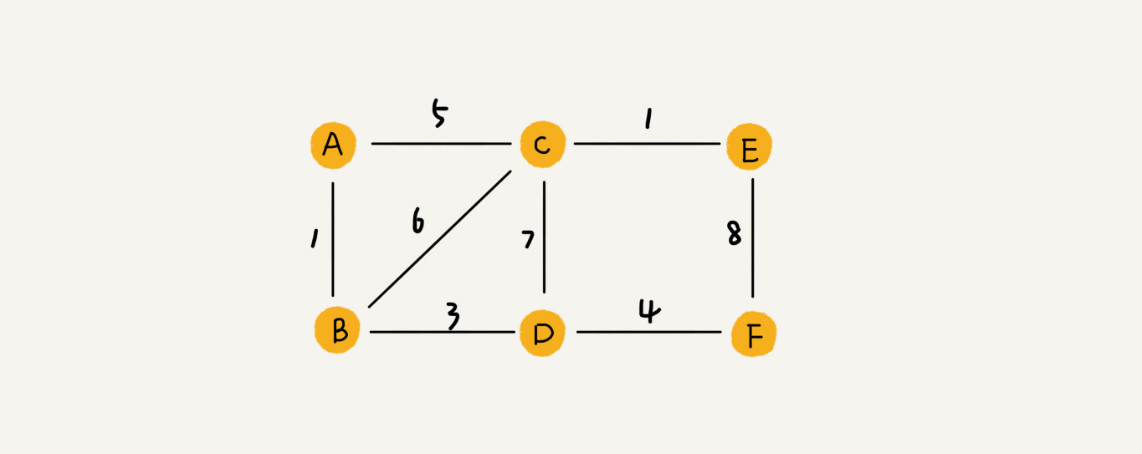
存储图的方法
邻接矩阵存储方法
邻接矩阵的底层依赖一个二维数组。对于无向图来说,如果顶点 i 与顶点 j 之间有边,就将 A[i][j] 和 A[j][i] 标记为 1;对于有向图来说,如果顶点 i 到顶点 j 之间,有一条箭头从顶点 i 指向顶点 j 的边,就将 A[i][j] 标记为 1。同理,如果有一条箭头从顶点 j 指向顶点 i 的边,就将 A[j][i]标记为 1。对于带权图,数组中就存储相应的权重。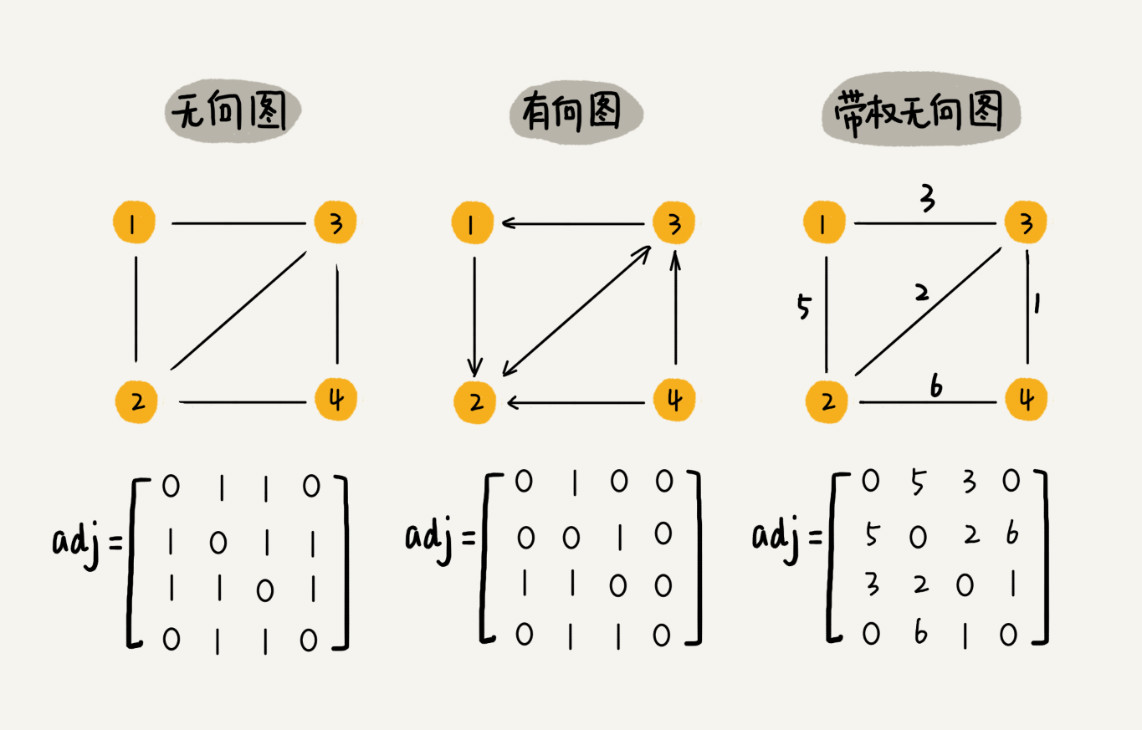
优点:用邻接矩阵来表示一个图,简单、直观。因为基于数组,所以在获取两个顶点的关系时,就非常高效。其次是方便计算,可以将很多图的运算转换成矩阵之间的运算。比如求解最短路径问题时会提到一个Floyd-Warshall 算法,就是利用矩阵循环相乘若干次得到结果。
缺点:邻接矩阵法比较浪费存储空间。对于无向图来说,如果 A[i][j] 等于 1,那 A[j][i] 也肯定等于 1。实际上,只需要存储一个就可以,无向图的二维数组中用对角线划分为上下两部分,只需要利用上面或者下面这样一半的空间就足够了,另外一半白白浪费掉了。如果存储的是稀疏图(Sparse Matrix),顶点很多,但每个顶点的边并不多,那邻接矩阵的存储方法就更加浪费空间了。比如微信有好几亿的用户,对应到图上就是好几亿的顶点。但是每个用户的好友并不会很多,一般也就三五百个而已。如果用邻接矩阵来存储,那绝大部分的存储空间都被浪费了。
邻接表存储方法
邻接表(Adjacency List)。主要用来解决邻接矩阵比较浪费内存空间的问题
每个顶点对应一条链表,链表中存储的是与这个顶点相连接的其他顶点。有向图的邻接表存储方式,每个顶点对应的链表里面,存储的是指向的顶点。对于无向图来说,每个顶点的链表中存储的,是跟这个顶点有边相连的顶点。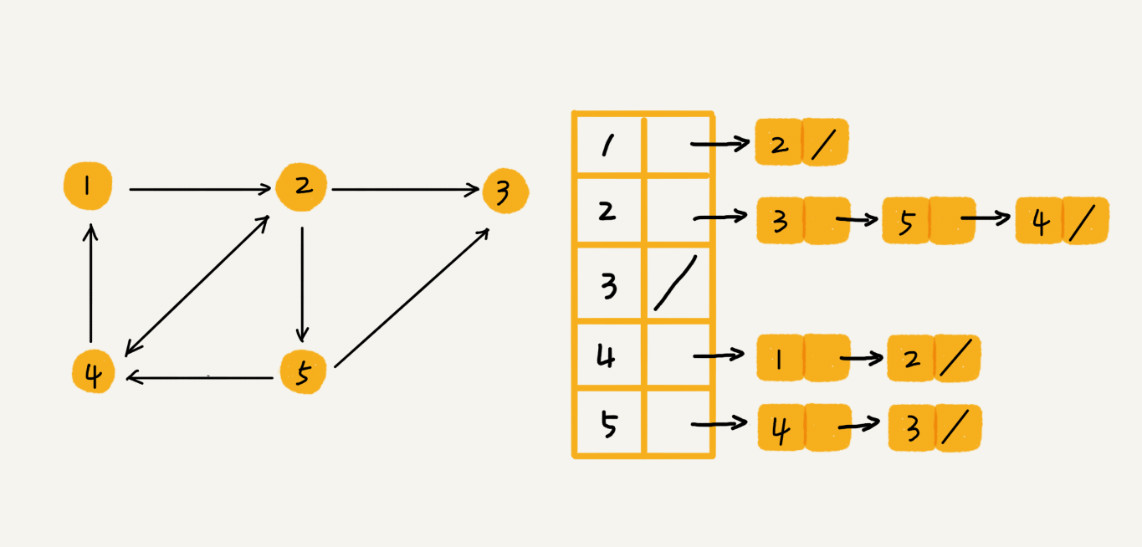
邻接矩阵存储起来比较浪费空间,但是使用起来比较节省时间。相反,邻接表存储起来比较节省空间,但是使用起来就比较耗时间。
所以为了提高查找效率,可以将链表换成其他更加高效的数据结构,比如平衡二叉查找树(比如红黑树)等。可以将邻接表中的链表改成平衡二叉查找树。还可以将链表改成有序动态数组,可以通过二分查找的方法来快速定位两个顶点之间否是存在边。
代码实现
字典和集合的主要区别就在于,集合中数据是以[值,值]的形式保存的,只关心值本身;而在字典和散列表中数据是以[键,值]的形式保存的,键不能重复,不仅关心键,也关心键所对应的值。
也可以把字典称之为映射表。由于字典和集合很相似,与Set类相似,ES6的原生Map类已经实现了字典的全部功能。
class Dictionary {constructor() {this.items = {}}set(key, value) { // 向字典中添加或修改元素this.items[key] = value}get(key) { // 通过键值查找字典中的值return this.items[key]}delete(key) { // 通过使用键值来从字典中删除对应的元素if (this.has(key)) {delete this.items[key]return true}return false}has(key) { // 判断给定的键值是否存在于字典中return this.items.hasOwnProperty(key)}clear() { // 清空字典内容this.items = {}}size() { // 返回字典中所有元素的数量return Object.keys(this.items).length}keys() { // 返回字典中所有的键值return Object.keys(this.items)}values() { // 返回字典中所有的值return Object.values(this.items)}getItems() { // 返回字典中的所有元素return this.items}}let dictionary = new Dictionary()dictionary.set('Gandalf', 'gandalf@email.com')dictionary.set('John', 'john@email.com')dictionary.set('Tyrion', 'tyrion@email.com')console.log(dictionary.has('Gandalf')) // trueconsole.log(dictionary.size()) // 3console.log(dictionary.keys()) // [ 'Gandalf', 'John', 'Tyrion' ]console.log(dictionary.values()) // [ 'gandalf@email.com', 'john@email.com', 'tyrion@email.com' ]console.log(dictionary.get('Tyrion')) // tyrion@email.comdictionary.delete('John')console.log(dictionary.keys()) // [ 'Gandalf', 'Tyrion' ]console.log(dictionary.values()) // [ 'gandalf@email.com', 'tyrion@email.com' ]console.log(dictionary.getItems()) // { Gandalf: 'gandalf@email.com', Tyrion: 'tyrion@email.com' }
class Graph {constructor(isDirected = false) {this.isDirected = isDirected // 是否为有向图this.vertices = [] // 用来存放图中的顶点this.adjList = new Dictionary() // 用来存放图中的边(每一个顶点到相邻顶点的关系列表)}// 向图中添加一个新顶点addVertex(v) {if (!this.vertices.includes(v)) {this.vertices.push(v)this.adjList.set(v, [])}}// 向图中添加给定的顶点a和顶点b之间的边addEdge(a, b) {// 如果图中没有顶点a,先添加顶点aif (!this.adjList.has(a)) {this.addVertex(a)}// 如果图中没有顶点b,先添加顶点bif (!this.adjList.has(b)) {this.addVertex(b)}this.adjList.get(a).push(b) // 在顶点a中添加指向顶点b的边if (!this.isDirected) {this.adjList.get(b).push(a); // 如果为无向图,则在顶点b中添加指向顶点a的边}}// 获取图的verticesgetVertices() {return this.vertices}// 获取图中的adjListgetAdjList() {return this.adjList}toString() {let s = ''this.vertices.forEach((v) => {s += `${v} -> `this.adjList.get(v).forEach((n) => {s += `${n} `})s += '\n'})return s}}// 测试let graph = new Graph()let myVertices = ['A', 'B', 'C', 'D', 'E', 'F', 'G', 'H', 'I']myVertices.forEach((v) => {graph.addVertex(v)})graph.addEdge('A', 'B')graph.addEdge('A', 'C')graph.addEdge('A', 'D')graph.addEdge('C', 'D')graph.addEdge('C', 'G')graph.addEdge('D', 'G')graph.addEdge('D', 'H')graph.addEdge('B', 'E')graph.addEdge('B', 'F')graph.addEdge('E', 'I')console.log(graph.toString())// A -> B C D// B -> A E F// C -> A D G// D -> A C G H// E -> B I// F -> B// G -> C D// H -> D// I -> E

若有收获,就点个赞吧
0 人点赞
