背景
对于一个单链表来讲,即便链表中存储的数据是有序的,要想在其中查找某个数据,也只能从头到尾遍历链表。这样查找效率就会很低,时间复杂度会很高,是 O(n)。跳表的出现就提高了查找效率,尤其是当数据越大效果越明显!支持二分查找算法
概念
跳表就是对链表进行稍加改造:链表加多级索引的一种数据结构。
跳表是一种各方面性能都比较优秀的动态数据结构,可以支持快速的插入、删除、查找操作,写起来也不复杂,甚至可以替代红黑树(Red-black tree)。Redis 中的有序集合(Sorted Set)就是用跳表来实现的。
代码实现
复杂度
跳表也是典型的用空间换时间:
- 查找、插入、删除操作的时间复杂度都是 O(logn)
- 空间复杂度是O(n)。也就是说,如果将包含 n 个结点的单链表构造成跳表,需要额外再用接近 n 个结点的存储空间。如果改为每三个结点或五个结点,抽一个结点到上级索引,尽管空间复杂度还是O(n),但么实际上可以减少了一半以上的内存空间。
跳表索引动态更新
当不停地往跳表中插入数据时,如果不更新索引,就有可能出现某 2 个索引结点之间数据非常多的情况。极端情况下,跳表还会退化成单链表: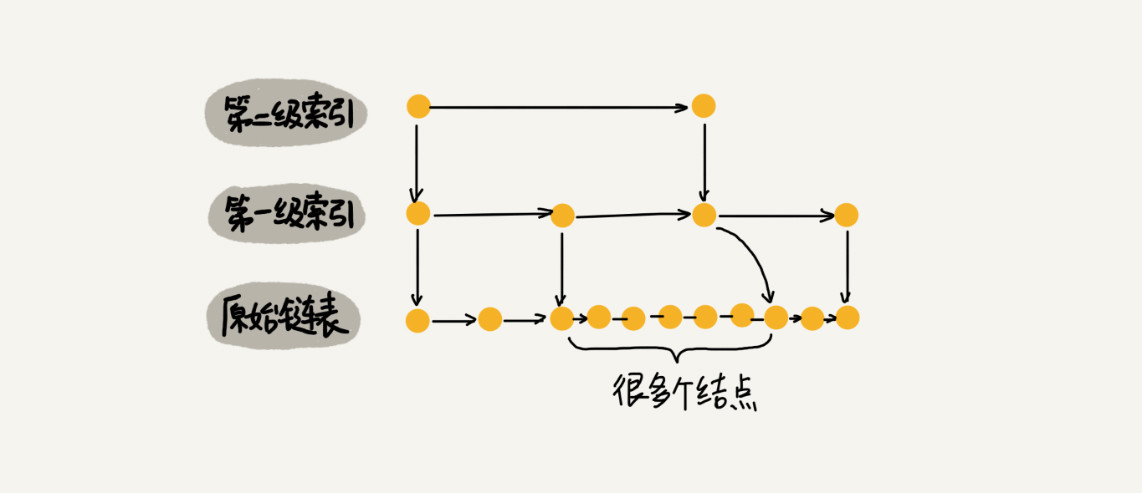
所以,跳表作为一种动态数据结构,需要某种手段来维护索引与原始链表大小之间的平衡,也就是说,如果链表中结点多了,索引结点就相应地增加一些,避免复杂度退化,以及查找、插入、删除操作性能下降。
红黑树、AVL 树这样平衡二叉树,它们是通过左右旋的方式保持左右子树的大小平衡,而跳表是通过随机函数来维护前面提到的“平衡性”。
当往跳表中插入数据的时候,可以选择同时将这个数据插入到部分索引层中。通过一个随机函数,来决定将这个结点插入到哪几级索引中,比如随机函数生成了值 K,那就将这个结点添加到第一级到第 K 级这 K 级索引中。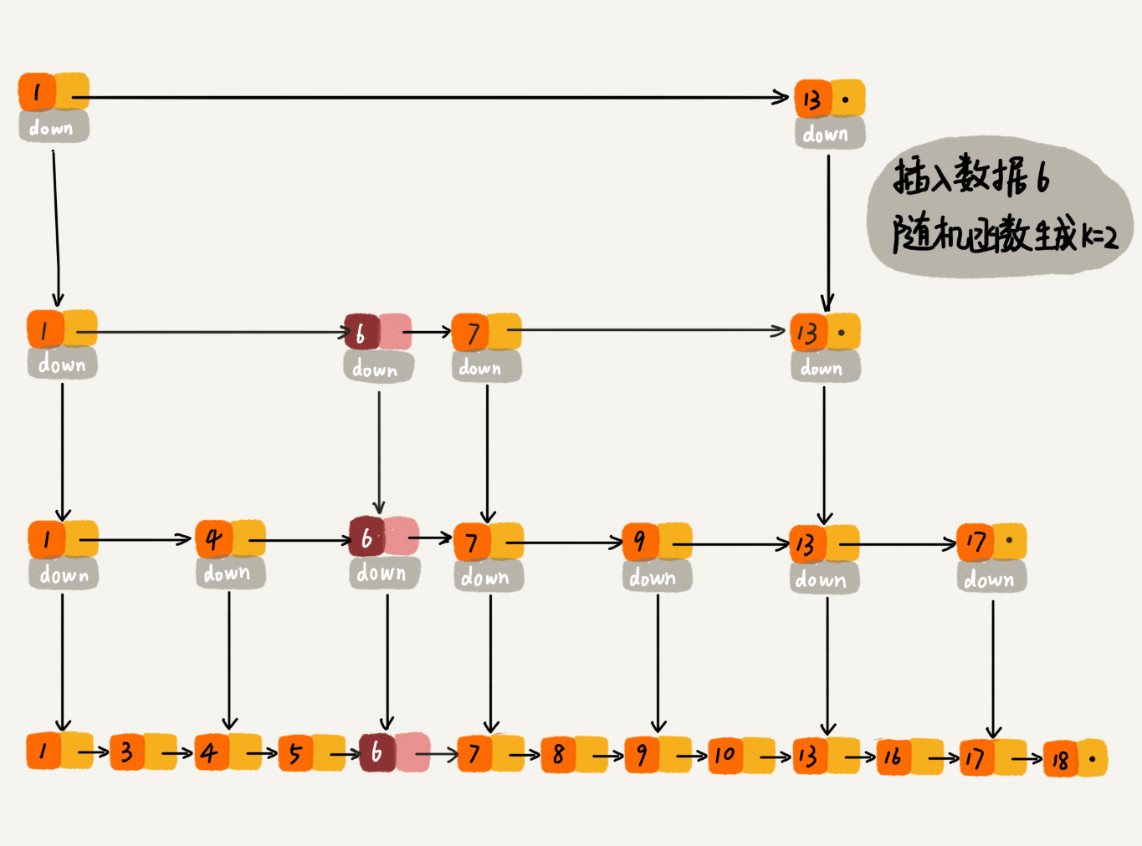

若有收获,就点个赞吧
0 人点赞
