一、索引
1.什么是索引
在关系型数据库中,索引是一种可以加快数据检索的数据库结构。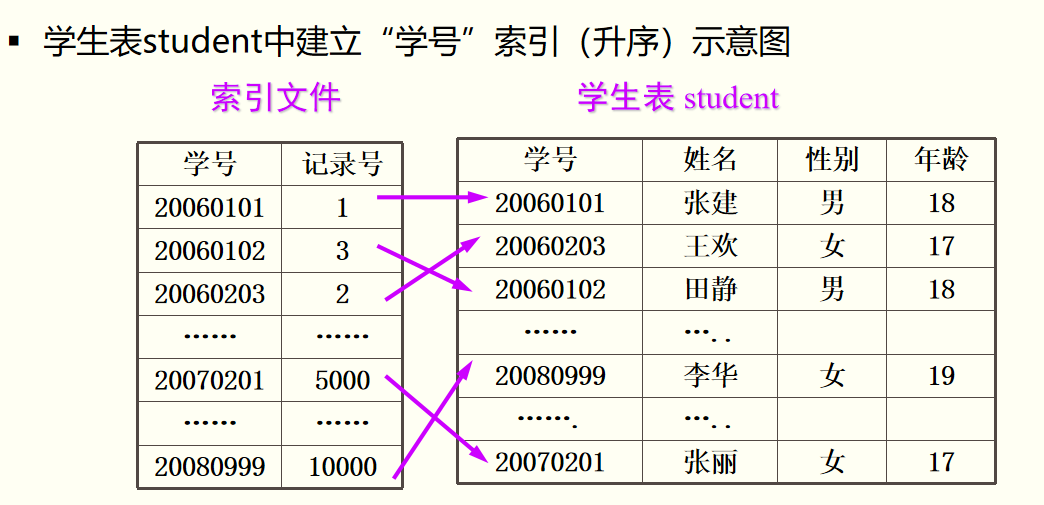
索引的含义和特点:
- 索引一旦被创建,将由数据库自动管理和维护。在更新数据表数据时,数据库会自动在索引上做出相应的修改。因此索引总是和表的内容保持一致。
索引的优点除了可以提高数据的查询速度,还可以通过创建唯一性索引保证表中数据记录不重复。
2.索引的分类
根据索引列的内容,MySQL的索引可以分为以下几类:
普通索引
普通索引是由KEY或INDEX定义的索引,它是MySQL中的基本索引类型,允许在定义索引的列中插入重复值和空值。该类型索引可以创建在任何数据类型中。
- 唯一性索引和主键索引
唯一索引是由UNIQUE定义的索引,指索引列的值必须唯一,但允许有空值。如果是在多个列上建立的组合索引,则列值的组合值必须唯一。
- 全文索引
全文索引是由FULLTEXT定义的索引,是指在定义索引的列上支持值的全文查找。它只能创建在CHAR、VARCHAR或TEXT类型的字段上。
- 空间索引
空间索引是由SPATIAL定义的索引,是只能在空间数据类型(GEOMETRY、POINT、LINESTRING和POLYGON。)的列上建立索引。需要注意的是,创建空间索引的字段,必须将其声明为NOT NULL。
此外,根据索引列的数目MySQL的索引又可以分为:
- 单列索引
- 组合索引
多列索引指的是在表中多个字段上创建的索引。只有在查询条件中使用了这些字段中的第一个字段时,该索引才会被使用。
唯一约束和唯一索引在 MySQL 数据库里区别
- 概念上不同,约束是为了保证数据的完整性,索引是为了辅助查询;
- 创建唯一约束时,会自动的创建唯一索引;
- 在理论上,不一样,在实际使用时,基本没有区别。
关于第二条,MySQL 中唯一约束是通过唯一索引实现的,为了保证没有重复值,在插入新记录时会再检索一遍,怎样检索快,当然是建索引了,所以,在创建唯一约束的时候就创建了唯一索引。
二、创建索引
创建表时创建索引的基本语法格式如下:
CREARE TABLE 表名 (字段名 数据类型 [完整性约束条件],…PRIMARY KEY(字段名,…[ASC|DESC]) /*主键索引*/|INDEX|KEY [索引名] (字段名[长度],…[ASC|DESC]) /*普通索引*/|[UNIQUE|FULLTEXT|SPATIAL] [INDEX|KEY] [索引名] (字段名[长度],…[ASC|DESC])/*唯一性/全文/空间索引*/);
参数说明:
UNIQUE: 该选项表示创建唯一索引,在索引列中不能有相同的列值存在。
FULLTEXT: 该选项表示创建全文索引。
SPATIAL: 该选项表示创建空间索引。
索引名:该选项表示创建索引的名称。不加此选项,则默认用创建索引的字段名为该索引名称。
长度:该选项指定字段中用于创建索引的长度。不加此选项,则默认用整个字段内容创建索引。
ASC|DESC:该选项表示创建索引时的排序方式。其中ASC为升序排列,DESC为降序排列。默认为升序排列。
例子:
【例8-1】创建borrow_copy表,在borrowid字段上建立主键索引,在bookid、readerid字段上建立组合唯一性索引,在readerid字段的前4个字符上上创建普通单列索引.
CREATE TABLE borrow_copy(borrowid CHAR(6) NOT NULL,bookid CHAR(6) NOT NULL,readerid CHAR(6) NOT NULL,borrowdate DATETIME,num INT(2) NOT NULL,PRIMARY KEY(borrowid),UNIQUE INDEX book_reader(bookid,readerid),INDEX (readerid(4))); 这里的 readerid(4)是指 用读者号前4个字符建索引
使用SHOW CREATE TABLE语句查看表的结构。
SHOW CREATE TABLE borrow_copy;
使用SHOW INDEX语句查看索引。
SHOW INDEX FROM borrow_copy;
为了查看索引是否被使用,可以使用EXPLAIN语句进行查看。
EXPLAIN SELECT * FROM borrow_copy WHERE readerid='S1001' ;
2.在已经存在的表上创建索引在已经存在的表上创建索引,可以使用ALTER TABLE语句或者CREATE INDEX语句。
①使用ALTER TABLE语句创建索引ALTER TABLE语句创建索引的基本语法格式如下:
ALTER TABLE 表名ADD PRIMARY KEY (字段名,…[ASC|DESC])|ADD INDEX [索引名] (字段名[长度] ,…[ASC|DESC])|ADD [UNIQUE|FULLTEXT|SPATIAL] [INDEX|KEY] [索引名] (字段名[长度] ,…[ASC|DESC])
【例8-2】在books表的press和pubdate列上创建一个组合索引,在info列上创建一个全文索引。
ALTER TABLE booksADD INDEX mark (press,pubdate),ADD FULLTEXT (info);SHOW INDEX FROM books;
②使用CREATE INDEX语句创建索引
CREATE [UNIQUE|FULLTEXT|SPATIAL] INDEX 索引名ON 表名 (字段名[长度],…[ASC|DESC])
【例8-3】根据books表的bookname列上的前6个字符建立一个升序索引name_book。
CREATE INDEX name_bookON books (bookname(6) ASC);SHOW INDEX FROM books;
三、删除索引
1.使用ALTER TABLE语句删除索引
ALTER TABLE 表名|DROP PRIMARY KEY /*删除主键*/|DROP INDEX 索引名 /*删除索引*/
【例8-4】删除books表中名称为mark和name_book的索引。
ALTER TABLE booksDROP INDEX mark,DROP INDEX name_book;SHOW INDEX FROM books;
2.使用DROP INDEX语句删除索引
DROP INDEX 索引名 ON 表名
【例8-5】删除books表中名称为info的索引
DROP INDEX info ON books;SHOW INDEX FROM books;
四、索引失效
失效的第1种情况:
select * from emp where ename like '%T';
ename上即使添加了索引,也不会走索引,为什么?
原因是因为模糊匹配当中以“%”开头了!
尽量避免模糊查询的时候以“%”开始。
这是一种优化的手段/策略。
失效的第2种情况:
使用or的时候会失效,如果使用or那么要求or两边的条件字段都要有
索引,才会走索引,如果其中一边有一个字段没有索引,那么另一个
字段上的索引也会实现。
失效的第3种情况:
使用复合索引的时候,没有使用左侧的列查找,索引失效
什么是复合索引?
两个字段,或者更多的字段联合起来添加一个索引,叫做复合索引。
create index emp_job_sal_index on emp(job,sal);
失效的第4种情况:
在where当中索引列参加了运算,索引失效。mysql> create index emp_sal_index on emp(sal);
失效的第5种情况:
在where当中索引列使用了函数explain select * from emp where lower(ename) = 'smith';
二、事务
怎么提交事务,怎么回滚事务?
提交事务:commit; 语句
回滚事务:rollback; 语句(回滚永远都是只能回滚到上一次的提交点!)
怎么将mysql的自动提交机制关闭掉呢?
先执行这个命令:start transaction;
事务包括4个特性?
A:原子性
说明事务是最小的工作单元。不可再分。
C:一致性
所有事务要求,在同一个事务当中,所有操作必须同时成功,或者同时失败,
以保证数据的一致性。
I:隔离性
A事务和B事务之间具有一定的隔离。
教室A和教室B之间有一道墙,这道墙就是隔离性。
A事务在操作一张表的时候,另一个事务B也操作这张表会那样???
D:持久性
事务最终结束的一个保障。事务提交,就相当于将没有保存到硬盘上的数据
保存到硬盘上!
3.5、关于事务之间的隔离性
提交事务:commit; 语句
回滚事务:rollback; 语句(回滚永远都是只能回滚到上一次的提交点!)
怎么将mysql的自动提交机制关闭掉呢?
先执行这个命令:start transaction;
---------------------------------回滚事务----------------------------------------mysql> use bjpowernode;Database changedmysql> select * from dept_bak;Empty set (0.00 sec)mysql> start transaction;Query OK, 0 rows affected (0.00 sec)mysql> insert into dept_bak values(10,'abc', 'tj');Query OK, 1 row affected (0.00 sec)mysql> insert into dept_bak values(10,'abc', 'tj');Query OK, 1 row affected (0.00 sec)mysql> select * from dept_bak;+--------+-------+------+| DEPTNO | DNAME | LOC |+--------+-------+------+| 10 | abc | tj || 10 | abc | tj |+--------+-------+------+2 rows in set (0.00 sec)mysql> rollback;Query OK, 0 rows affected (0.00 sec)mysql> select * from dept_bak;Empty set (0.00 sec)---------------------------------提交事务----------------------------------------mysql> use bjpowernode;Database changedmysql> select * from dept_bak;+--------+-------+------+| DEPTNO | DNAME | LOC |+--------+-------+------+| 10 | abc | bj |+--------+-------+------+1 row in set (0.00 sec)mysql> start transaction;Query OK, 0 rows affected (0.00 sec)mysql> insert into dept_bak values(20,'abcQuery OK, 1 row affected (0.00 sec)mysql> insert into dept_bak values(20,'abcQuery OK, 1 row affected (0.00 sec)mysql> insert into dept_bak values(20,'abcQuery OK, 1 row affected (0.00 sec)mysql> commit;Query OK, 0 rows affected (0.01 sec)mysql> select * from dept_bak;+--------+-------+------+| DEPTNO | DNAME | LOC |+--------+-------+------+| 10 | abc | bj || 20 | abc | tj || 20 | abc | tj || 20 | abc | tj |+--------+-------+------+4 rows in set (0.00 sec)mysql> rollback;Query OK, 0 rows affected (0.00 sec)mysql> select * from dept_bak;+--------+-------+------+| DEPTNO | DNAME | LOC |+--------+-------+------+| 10 | abc | bj || 20 | abc | tj || 20 | abc | tj || 20 | abc | tj |+--------+-------+------+4 rows in set (0.00 sec)
注意:
- MySQL中的事务不允许嵌套,若在执行START TRANSACTION语句前上一个事务还未提交,会隐式地执行提交操作。
- 事务处理主要是针对数据表中数据的处理,不包括创建或删除数据库、数据表,修改表结构等操作,而且执行这类操作时会隐式地提交事务。
例如:在使用START TRANSACTION开启事务后执行ALTER TABLE修改表结构,会隐式提交事务。
事务包括4个特性?
A:原子性
说明事务是最小的工作单元。不可再分。
C:一致性
所有事务要求,在同一个事务当中,所有操作必须同时成功,或者同时失败,
以保证数据的一致性。
I:隔离性
A事务和B事务之间具有一定的隔离。
教室A和教室B之间有一道墙,这道墙就是隔离性。
A事务在操作一张表的时候,另一个事务B也操作这张表会那样???
D:持久性
事务最终结束的一个保障。事务提交,就相当于将没有保存到硬盘上的数据
保存到硬盘上!
事务隔离性存在隔离级别,理论上隔离级别包括4个:
第一级别:读未提交(read uncommitted)
对方事务还没有提交,我们当前事务可以读取到对方未提交的数据。
读未提交存在脏读(Dirty Read)现象:表示读到了脏的数据。
第二级别:读已提交(read committed)
对方事务提交之后的数据我方可以读取到。
这种隔离级别解决了: 脏读现象没有了。
读已提交存在的问题是:不可重复读。
第三级别:可重复读(repeatable read)
这种隔离级别解决了:不可重复读问题。
这种隔离级别存在的问题是:读取到的数据是幻象。
第四级别:序列化读/串行化读(serializable)
解决了所有问题。
效率低。需要事务排队。
oracle数据库默认的隔离级别是:读已提交。
mysql数据库默认的隔离级别是:可重复读。
三、数据类型
整型
TINYINT, SMALLINT, MEDIUMINT, INT, BIGINT 分别使用 8, 16, 24, 32, 64 位存储空间,一般情况下越小的列越好。
INT(11) 中的数字只是规定了交互工具显示字符的个数,对于存储和计算来说是没有意义的。
浮点数
FLOAT 和 DOUBLE 为浮点类型,DECIMAL 为高精度小数类型。CPU 原生支持浮点运算,但是不支持 DECIMAl 类型的计算,因此 DECIMAL 的计算比浮点类型需要更高的代价。
FLOAT、DOUBLE 和 DECIMAL 都可以指定列宽,例如 DECIMAL(18, 9) 表示总共 18 位,取 9 位存储小数部分,剩下 9 位存储整数部分。
字符串
主要有 CHAR 和 VARCHAR 两种类型,一种是定长的,一种是变长的。
VARCHAR 这种变长类型能够节省空间,因为只需要存储必要的内容。但是在执行 UPDATE 时可能会使行变得比原来长,当超出一个页所能容纳的大小时,就要执行额外的操作。MyISAM 会将行拆成不同的片段存储,而 InnoDB 则需要分裂页来使行放进页内。
在进行存储和检索时,会保留 VARCHAR 末尾的空格,而会删除 CHAR 末尾的空格。
时间和日期
MySQL 提供了两种相似的日期时间类型:DATETIME 和 TIMESTAMP。
1. DATETIME
能够保存从 1000 年到 9999 年的日期和时间,精度为秒,使用 8 字节的存储空间。
它与时区无关。
默认情况下,MySQL 以一种可排序的、无歧义的格式显示 DATETIME 值,例如“2008-01-16 22:37:08”,这是 ANSI 标准定义的日期和时间表示方法。
2. TIMESTAMP
和 UNIX 时间戳相同,保存从 1970 年 1 月 1 日午夜(格林威治时间)以来的秒数,使用 4 个字节,只能表示从 1970 年到 2038 年。
它和时区有关,也就是说一个时间戳在不同的时区所代表的具体时间是不同的。
MySQL 提供了 FROM_UNIXTIME() 函数把 UNIX 时间戳转换为日期,并提供了 UNIX_TIMESTAMP() 函数把日期转换为 UNIX 时间戳。
默认情况下,如果插入时没有指定 TIMESTAMP 列的值,会将这个值设置为当前时间。
应该尽量使用 TIMESTAMP,因为它比 DATETIME 空间效率更高

若有收获,就点个赞吧
0 人点赞
