一、数组理论基础
一维数组
数组是存放在连续内存空间上的相同类型数据的集合。
数组可以方便的通过下标索引的方式获取到下标下对应的数据。
举一个字符数组的例子,如图所示:
需要两点注意的是
- 数组下标都是从0开始的。
- 数组内存空间的地址是连续的
正是因为数组的在内存空间的地址是连续的,所以我们在删除或者增添元素的时候,就难免要移动其他元素的地址。
例如删除下标为3的元素,需要对下标为3的元素后面的所有元素都要做移动操作,如图所示: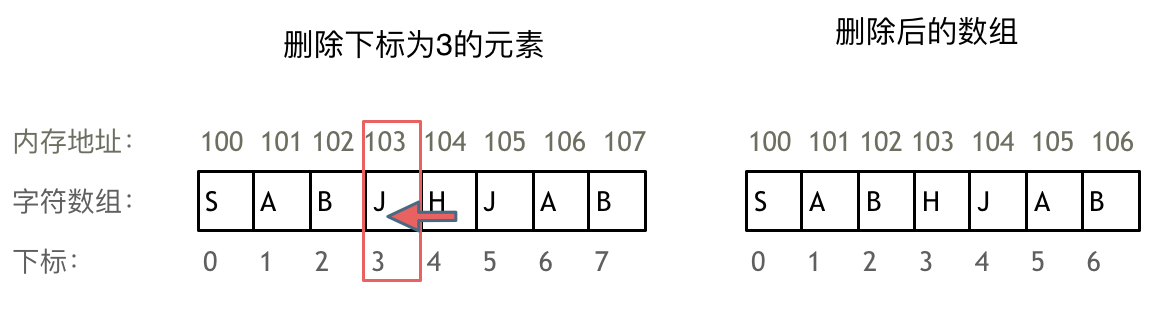
数组的元素是不能删的,只能覆盖。
静态初始化语法格式:
int[] array = {100, 2100, 300, 55};
动态初始化语法格式:
int[] array = new int[5];
二维数组
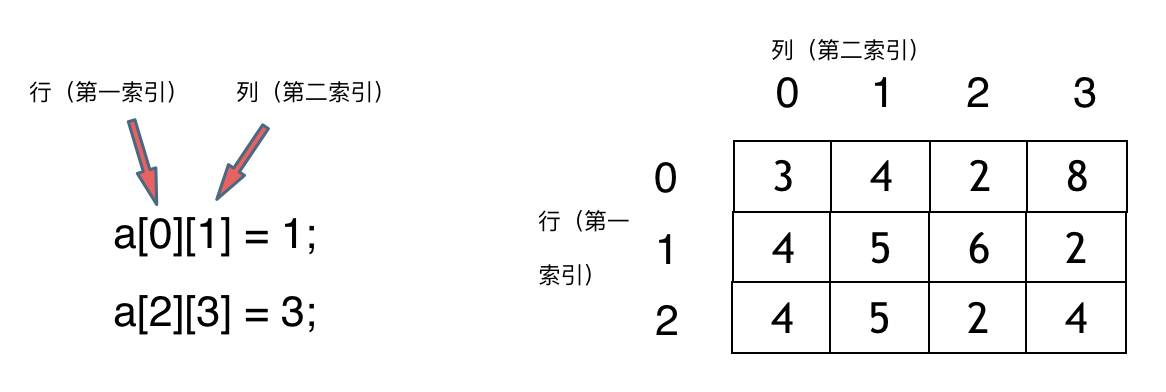
Java的二维数组可能是如下排列的方式: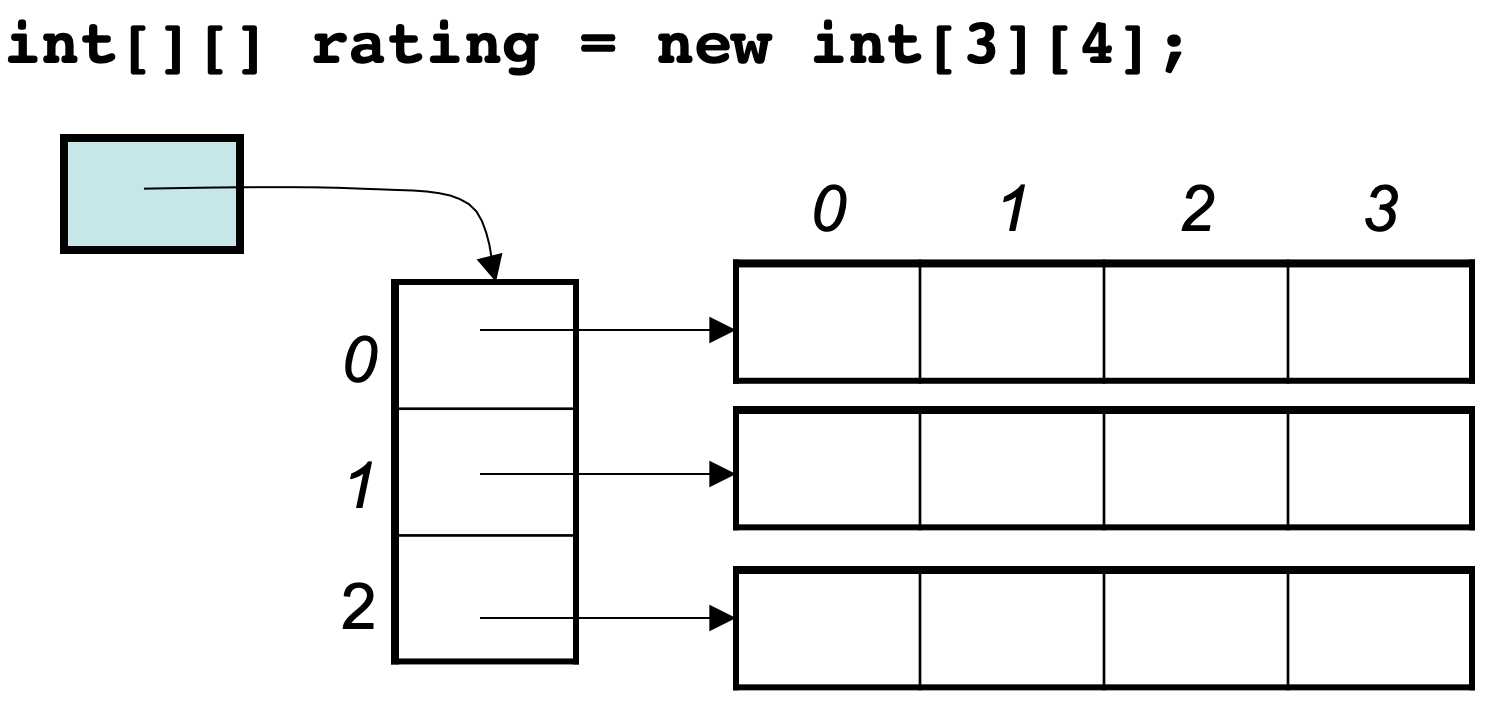
String[][] array = {{ "java" , "oracle " , "C++"," python" , "c#"},{"张三","李四",“王五."},{ "lucy" , "jack ","rose "};};
例题:
二维数组M的成员是6个字符组成的串,行下标从0到8,列下标从1到10,则至少要需要多少个字节来储存?则M的第8列和第5行共占多少个字节?
1 2 3 4 5 6 7 8 9 1 0<br />0 M<br />1 M<br />2 M<br />3 M<br />4 M<br />5**M M M M M M M M M M **<br />6 M<br />7 M<br />8 M<br /> <br />行数:9(0..8)<br />列数:10(1..10)<br />每个数组元素占用的空间:6字节 每个字符占1字节<br />存储M的总空间:9 * 10 * 6 = 540字节。
第8列总共9个元素(因为总共9行),每个元素占6个字节,共54字节。
第5行总共10个元素(因为总共10列),每个元素占6个字节,共60字节。
但是第8列和第5行重复一个元素,就是54+60-6=108
数组的拷贝
//数组拷贝public class Test7 {public static void main(String[] args){//拷贝源(从这个数组中拷贝)int[] src = {1,11,22,3,4};//拷贝目标(拷贝到这个目标数组上)int[] dest = new int[10];//动态初始化一个长度为10的数组,每一个元素默认值0//调用JDK System类中的arraycopy方法,来完成数组的拷贝System.arraycopy(src, 0,dest, 2,src.length);for(int i = 0; i < dest.length; i++) {System. out.println(dest[i]);//0 0 1 11 22 3 4 0 0 0}}}
数组的扩容
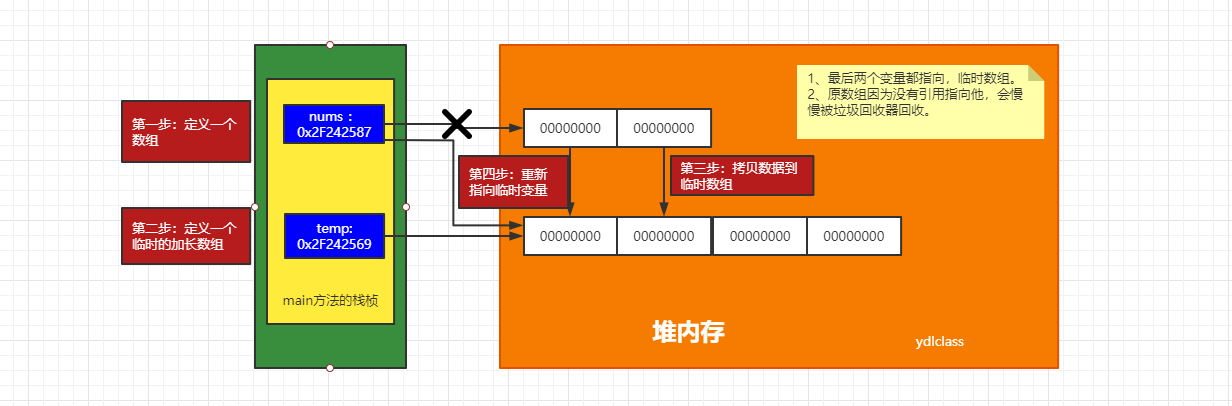
public class test55 {public static void main(String[] args) {// 定义原始数组int[] nums = new int[]{18,2,59,43,89};// 定义一个新的临时数字int[] temp = new int[8];// 将原始数组的数据全部拷贝到临时数组for (int i = 0; i < nums.length; i++) {temp[i] = nums[i];}// 让原始数组的引用指向临时数组,感觉上就像原始数组被扩容了nums = temp;for (int i = 0; i < nums.length; i++) {System.out.println(temp[i]);}}}
二、链表理论基础
1.单链表
什么是链表,链表是一种通过指针串联在一起的线性结构,每一个节点由两部分组成,一个是数据域一个是指针域(存放指向下一个节点的指针),最后一个节点的指针域指向null(空指针的意思)。
链接的入口节点称为链表的头结点也就是head。
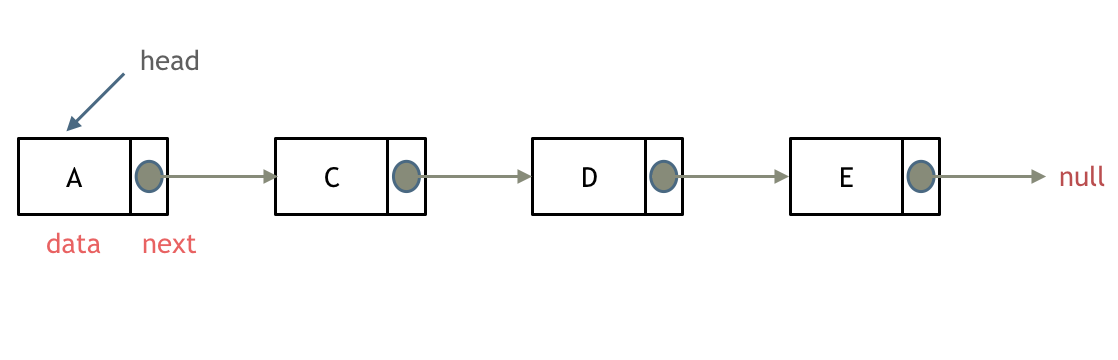
2.双链表
双链表:每一个节点有两个指针域,一个指向下一个节点,一个指向上一个节点。
双链表既可以向前查询也可以向后查询。
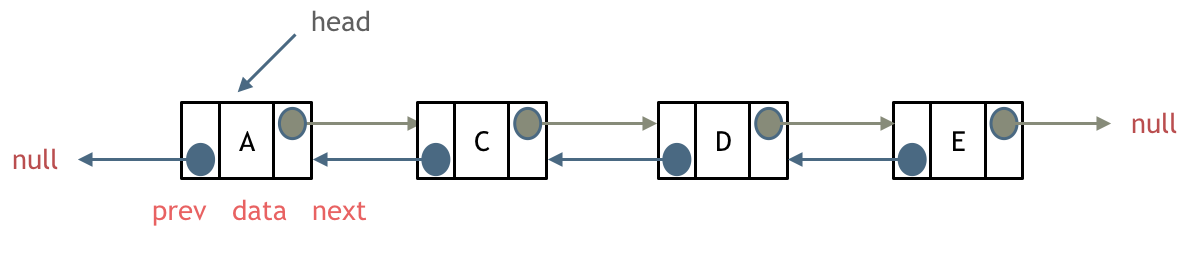
3.循环链表
循环链表,顾名思义,就是链表首尾相连。
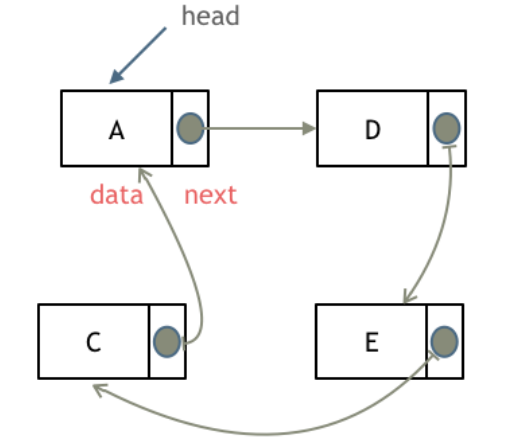
链表的存储方式
数组是在内存中是连续分布的,但是链表在内存中可不是连续分布的。
链表是通过指针域的指针链接在内存中各个节点。
所以链表中的节点在内存中不是连续分布的 ,而是散乱分布在内存中的某地址上,分配机制取决于操作系统的内存管理。
如图所示: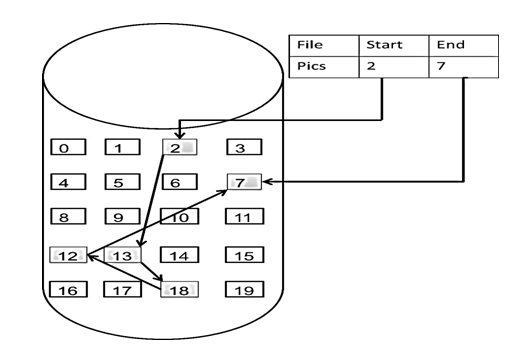
这个链表起始节点为2, 终止节点为7, 各个节点分布在内存个不同地址空间上,通过指针串联在一起。
链表的定义
public class ListNode{int val;ListNode next; //链表指向的下一个值的指针ListNode(int x){val = x;} //这个方式赋值}
通过自己定义构造函数初始化节点
xx.next = new ListNode(4)
注意此时是赋值给下一个指针指向的位置,此时此链表一个值,值为4。
链表的操作
删除节点
删除D节点,如图所示:
只要将C节点的next指针 指向E节点就可以了。
添加节点
如图所示: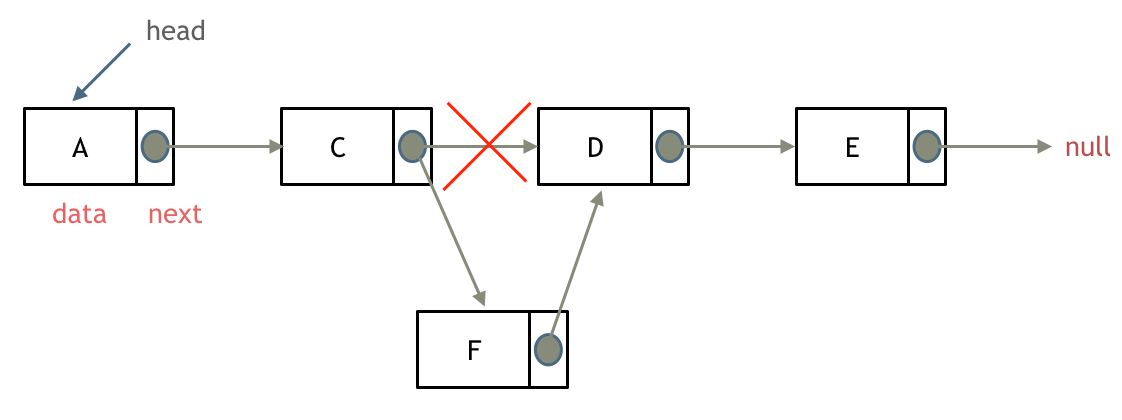
可以看出链表的增添和删除都是$O(1)$操作,也不会影响到其他节点。
但是要注意,要是删除第五个节点,需要从头节点查找到第四个节点通过next指针进行删除操作,查找的时间复杂度是$O(n)$。
性能分析
再把链表的特性和数组的特性进行一个对比,如图所示: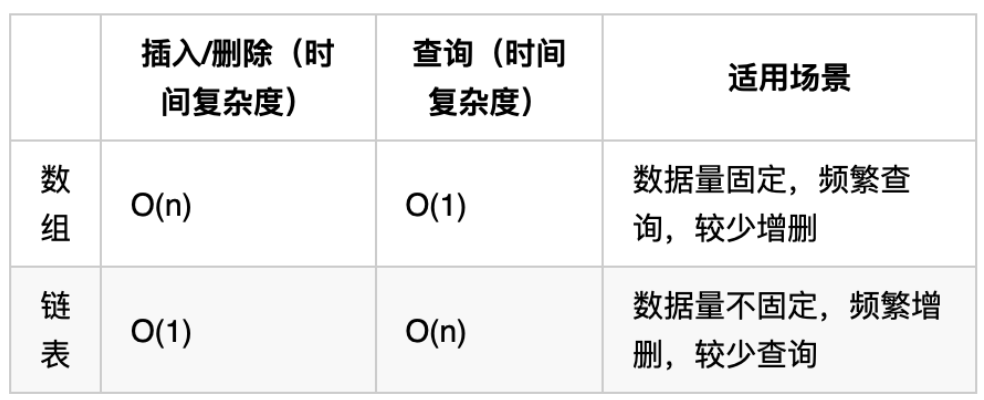
数组在定义的时候,长度就是固定的,如果想改动数组的长度,就需要重新定义一个新的数组。
链表的长度可以是不固定的,并且可以动态增删, 适合数据量不固定,频繁增删,较少查询的场景。
补充
1.在有n个结点的二叉链表中,空链域的个数为 n+1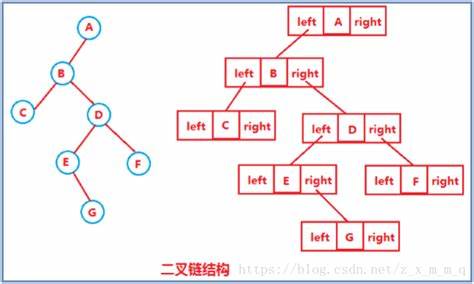

若有收获,就点个赞吧
0 人点赞
