Ref: https://pdai.tech/md/db/nosql-redis/db-redis-x-redis-ds.html
快表 - QuickList
quicklist 这个结构是 Redis 在 3.2 版本后新加的,之前的版本是 list (即 linkedlist), 用于 String 数据类型中。
它是一种以 ziplist 为结点的双端链表结构。宏观上,quicklist 是一个链表,微观上,链表中的每个结点都是一个 ziplist。
quicklist 结构
- 如下是 6.0 源码中 quicklist 相关的结构: ```c / Node, quicklist, and Iterator are the only data structures used currently. /
/* quicklistNode is a 32 byte struct describing a ziplist for a quicklist.
- We use bit fields keep the quicklistNode at 32 bytes.
- count: 16 bits, max 65536 (max zl bytes is 65k, so max count actually < 32k).
- encoding: 2 bits, RAW=1, LZF=2.
- container: 2 bits, NONE=1, ZIPLIST=2.
- recompress: 1 bit, bool, true if node is temporarry decompressed for usage.
- attempted_compress: 1 bit, boolean, used for verifying during testing.
- extra: 10 bits, free for future use; pads out the remainder of 32 bits / typedef struct quicklistNode { struct quicklistNode prev; struct quicklistNode next; unsigned char zl; unsigned int sz; / ziplist size in bytes / unsigned int count : 16; / count of items in ziplist / unsigned int encoding : 2; / RAW==1 or LZF==2 / unsigned int container : 2; / NONE==1 or ZIPLIST==2 / unsigned int recompress : 1; / was this node previous compressed? / unsigned int attempted_compress : 1; / node can’t compress; too small / unsigned int extra : 10; / more bits to steal for future usage / } quicklistNode;
/* quicklistLZF is a 4+N byte struct holding ‘sz’ followed by ‘compressed’.
- ‘sz’ is byte length of ‘compressed’ field.
- ‘compressed’ is LZF data with total (compressed) length ‘sz’
- NOTE: uncompressed length is stored in quicklistNode->sz.
- When quicklistNode->zl is compressed, node->zl points to a quicklistLZF / typedef struct quicklistLZF { unsigned int sz; / LZF size in bytes*/ char compressed[]; } quicklistLZF;
/* Bookmarks are padded with realloc at the end of of the quicklist struct.
- They should only be used for very big lists if thousands of nodes were the
- excess memory usage is negligible, and there’s a real need to iterate on them
- in portions.
- When not used, they don’t add any memory overhead, but when used and then
- deleted, some overhead remains (to avoid resonance).
- The number of bookmarks used should be kept to minimum since it also adds
- overhead on node deletion (searching for a bookmark to update). / typedef struct quicklistBookmark { quicklistNode node; char *name; } quicklistBookmark;
/* quicklist is a 40 byte struct (on 64-bit systems) describing a quicklist.
- ‘count’ is the number of total entries.
- ‘len’ is the number of quicklist nodes.
- ‘compress’ is: -1 if compression disabled, otherwise it’s the number
- of quicklistNodes to leave uncompressed at ends of quicklist.
- ‘fill’ is the user-requested (or default) fill factor.
- ‘bookmakrs are an optional feature that is used by realloc this struct,
- so that they don’t consume memory when not used. / typedef struct quicklist { quicklistNode head; quicklistNode tail; unsigned long count; / total count of all entries in all ziplists / unsigned long len; / number of quicklistNodes / int fill : QL_FILL_BITS; / fill factor for individual nodes / unsigned int compress : QL_COMP_BITS; / depth of end nodes not to compress;0=off */ unsigned int bookmark_count: QL_BM_BITS; quicklistBookmark bookmarks[]; } quicklist;
typedef struct quicklistIter { const quicklist quicklist; quicklistNode current; unsigned char zi; long offset; / offset in current ziplist */ int direction; } quicklistIter;
typedef struct quicklistEntry {
const quicklist quicklist;
quicklistNode node;
unsigned char zi;
unsigned char value;
long long longval;
unsigned int sz;
int offset;
} quicklistEntry;
```
著作权归https://pdai.tech所有。 链接:https://pdai.tech/md/db/nosql-redis/db-redis-x-redis-ds.html
这里定义了 6 个结构体:
- quicklistNode, 宏观上,quicklist 是一个链表,这个结构描述的就是链表中的结点。它通过 zl 字段持有底层的 ziplist. 简单来讲,它描述了一个 ziplist 实例
- quicklistLZF, ziplist 是一段连续的内存,用 LZ4 算法压缩后,就可以包装成一个 quicklistLZF 结构。是否压缩 quicklist 中的每个 ziplist 实例是一个可配置项。若这个配置项是开启的,那么 quicklistNode.zl 字段指向的就不是一个 ziplist 实例,而是一个压缩后的 quicklistLZF 实例
- quicklistBookmark, 在 quicklist 尾部增加的一个书签,它只有在大量节点的多余内存使用量可以忽略不计的情况且确实需要分批迭代它们,才会被使用。当不使用它们时,它们不会增加任何内存开销。
- quicklist. 这就是一个双链表的定义. head, tail 分别指向头尾指针. len 代表链表中的结点. count 指的是整个 quicklist 中的所有 ziplist 中的 entry 的数目. fill 字段影响着每个链表结点中 ziplist 的最大占用空间,compress 影响着是否要对每个 ziplist 以 LZ4 算法进行进一步压缩以更节省内存空间.
- quicklistIter 是一个迭代器
quicklistEntry 是对 ziplist 中的 entry 概念的封装. quicklist 作为一个封装良好的数据结构,不希望使用者感知到其内部的实现,所以需要把 ziplist.entry 的概念重新包装一下.
quicklist 内存布局图
quicklist 更多额外信息
下面是有关 quicklist 的更多额外信息:
quicklist.fill 的值影响着每个链表结点中,ziplist 的长度.
- 当数值为负数时,代表以字节数限制单个 ziplist 的最大长度。具体为:
- -1 不超过 4kb
- -2 不超过 8kb
- -3 不超过 16kb
- -4 不超过 32kb
- -5 不超过 64kb
- 当数值为正数时,代表以 entry 数目限制单个 ziplist 的长度。值即为数目。由于该字段仅占 16 位,所以以 entry 数目限制 ziplist 的容量时,最大值为 2^15 个
- quicklist.compress 的值影响着 quicklistNode.zl 字段指向的是原生的 ziplist, 还是经过压缩包装后的 quicklistLZF
- 0 表示不压缩,zl 字段直接指向 ziplist
- 1 表示 quicklist 的链表头尾结点不压缩,其余结点的 zl 字段指向的是经过压缩后的 quicklistLZF
- 2 表示 quicklist 的链表头两个,与末两个结点不压缩,其余结点的 zl 字段指向的是经过压缩后的 quicklistLZF
- 以此类推,最大值为 2^16
- quicklistNode.encoding 字段,以指示本链表结点所持有的 ziplist 是否经过了压缩. 1 代表未压缩,持有的是原生的 ziplist, 2 代表压缩过
- quicklistNode.container 字段指示的是每个链表结点所持有的数据类型是什么。默认的实现是 ziplist, 对应的该字段的值是 2, 目前 Redis 没有提供其它实现。所以实际上,该字段的值恒为 2
- quicklistNode.recompress 字段指示的是当前结点所持有的 ziplist 是否经过了解压。如果该字段为 1 即代表之前被解压过,且需要在下一次操作时重新压缩.
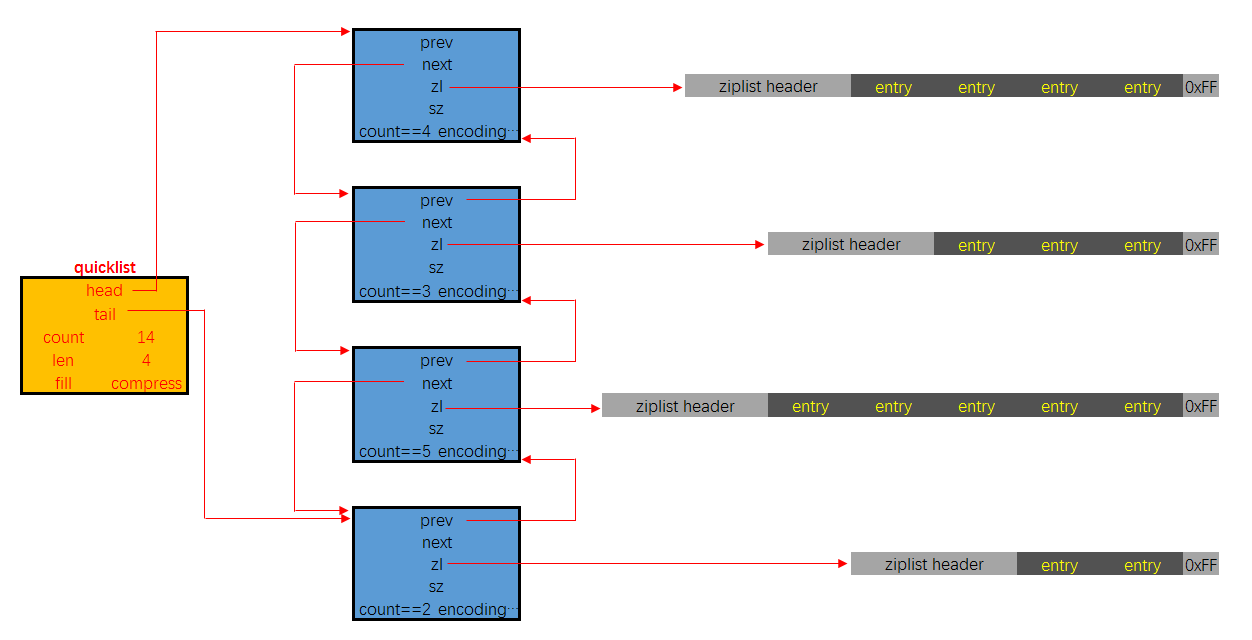
quicklist 的具体实现代码篇幅很长,这里就不贴代码片断了,从内存布局上也能看出来,由于每个结点持有的 ziplist 是有上限长度的,所以在与操作时要考虑的分支情况比较多。
quicklist 有自己的优点,也有缺点,对于使用者来说,其使用体验类似于线性数据结构,list 作为最传统的双链表,结点通过指针持有数据,指针字段会耗费大量内存. ziplist 解决了耗费内存这个问题。但引入了新的问题:每次写操作整个 ziplist 的内存都需要重分配. quicklist 在两者之间做了一个平衡。并且使用者可以通过自定义 quicklist.fill, 根据实际业务情况,经验主义调参.

若有收获,就点个赞吧
0 人点赞
