Ref: https://pdai.tech/md/framework/orm-mybatis/mybatis-y-cache-level1.html
MyBatis 一级缓存实现
什么是一级缓存? 为什么使用一级缓存?
每当我们使用 MyBatis 开启一次和数据库的会话,MyBatis 会创建出一个 SqlSession 对象表示一次数据库会话。
在对数据库的一次会话中,我们有可能会反复地执行完全相同的查询语句,如果不采取一些措施的话,每一次查询都会查询一次数据库,而我们在极短的时间内做了完全相同的查询,那么它们的结果极有可能完全相同,由于查询一次数据库的代价很大,这有可能造成很大的资源浪费。
为了解决这一问题,减少资源的浪费,MyBatis 会在表示会话的 SqlSession 对象中建立一个简单的缓存,将每次查询到的结果结果缓存起来,当下次查询的时候,如果判断先前有个完全一样的查询,会直接从缓存中直接将结果取出,返回给用户,不需要再进行一次数据库查询了。
如下图所示,MyBatis 一次会话:一个 SqlSession 对象中创建一个本地缓存 (local cache),对于每一次查询,都会尝试根据查询的条件去本地缓存中查找是否在缓存中,如果在缓存中,就直接从缓存中取出,然后返回给用户;否则,从数据库读取数据,将查询结果存入缓存并返回给用户。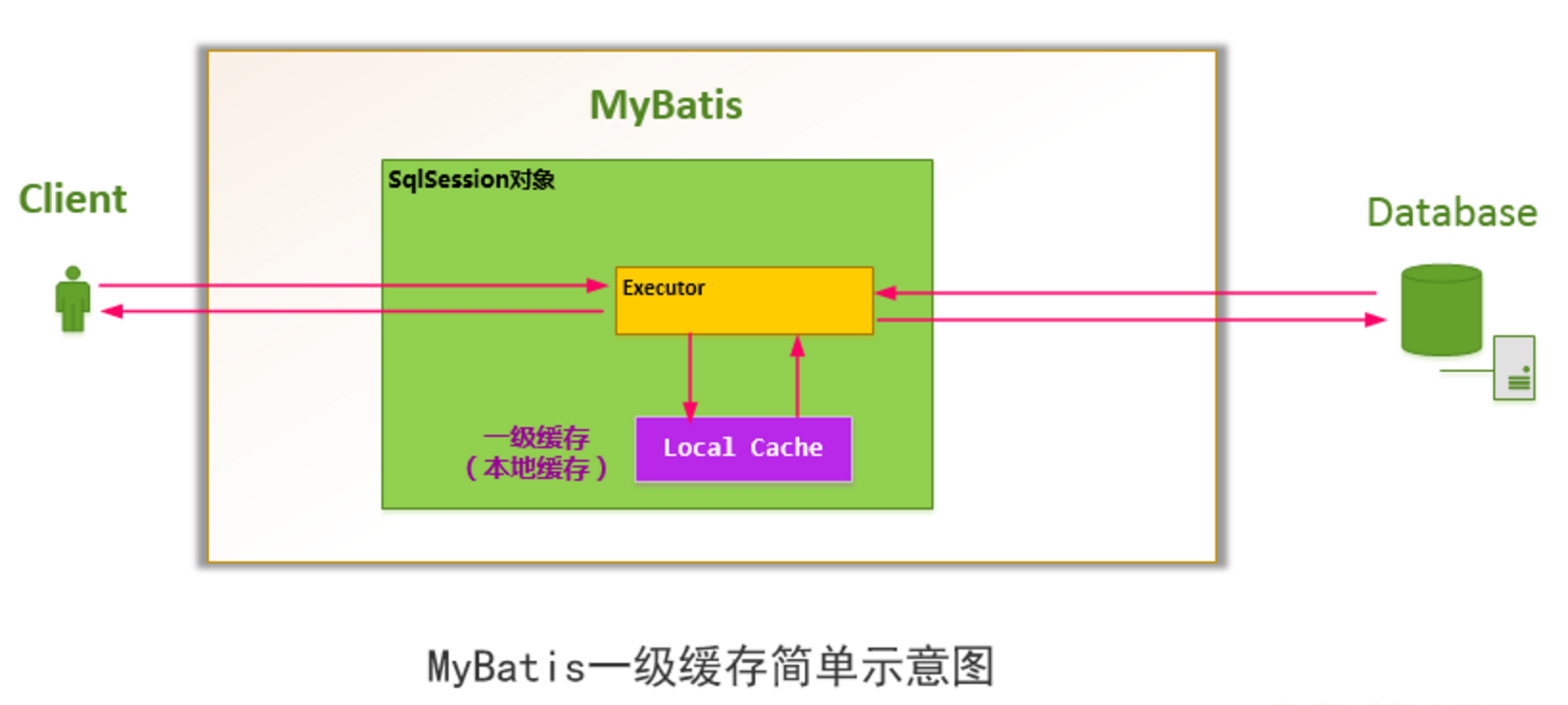
对于会话(Session)级别的数据缓存,我们称之为一级数据缓存,简称一级缓存。
MyBatis 中的一级缓存是怎样组织的?
即 SqlSession 中的缓存是怎样组织的?由于 MyBatis 使用 SqlSession 对象表示一次数据库的会话,那么,对于会话级别的一级缓存也应该是在 SqlSession 中控制的。
实际上,MyBatis 只是一个 MyBatis 对外的接口,SqlSession 将它的工作交给了 Executor 执行器这个角色来完成,负责完成对数据库的各种操作。当创建了一个 SqlSession 对象时,MyBatis 会为这个 SqlSession 对象创建一个新的 Executor 执行器,而缓存信息就被维护在这个 Executor 执行器中,MyBatis 将缓存和对缓存相关的操作封装成了 Cache 接口中。SqlSession、Executor、Cache 之间的关系如下列类图所示: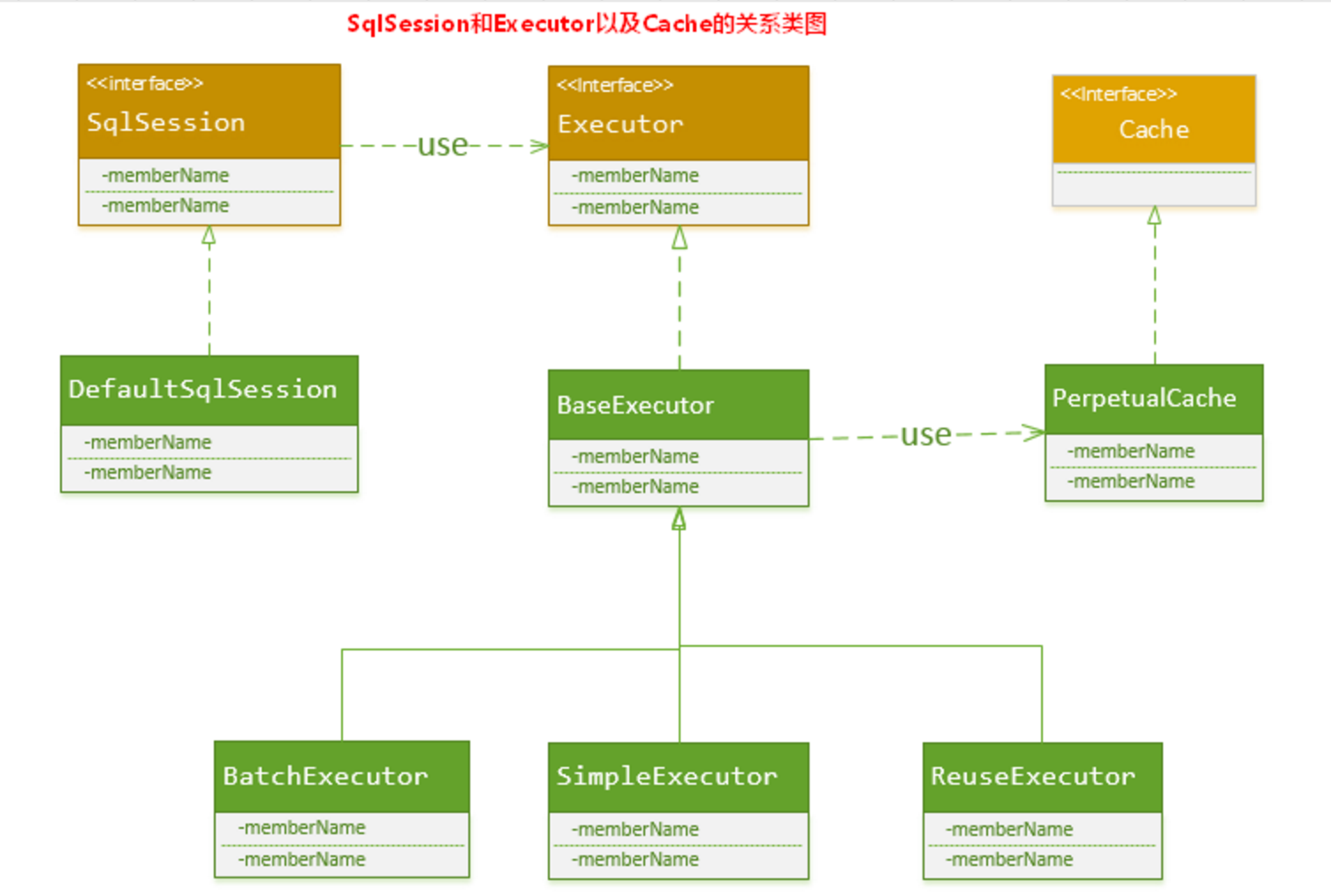
如上述的类图所示,Executor 接口的实现类 BaseExecutor 中拥有一个 Cache 接口的实现类 PerpetualCache,则对于 BaseExecutor 对象而言,它将使用 PerpetualCache 对象维护缓存。
综上,SqlSession 对象、Executor 对象、Cache 对象之间的关系如下图所示: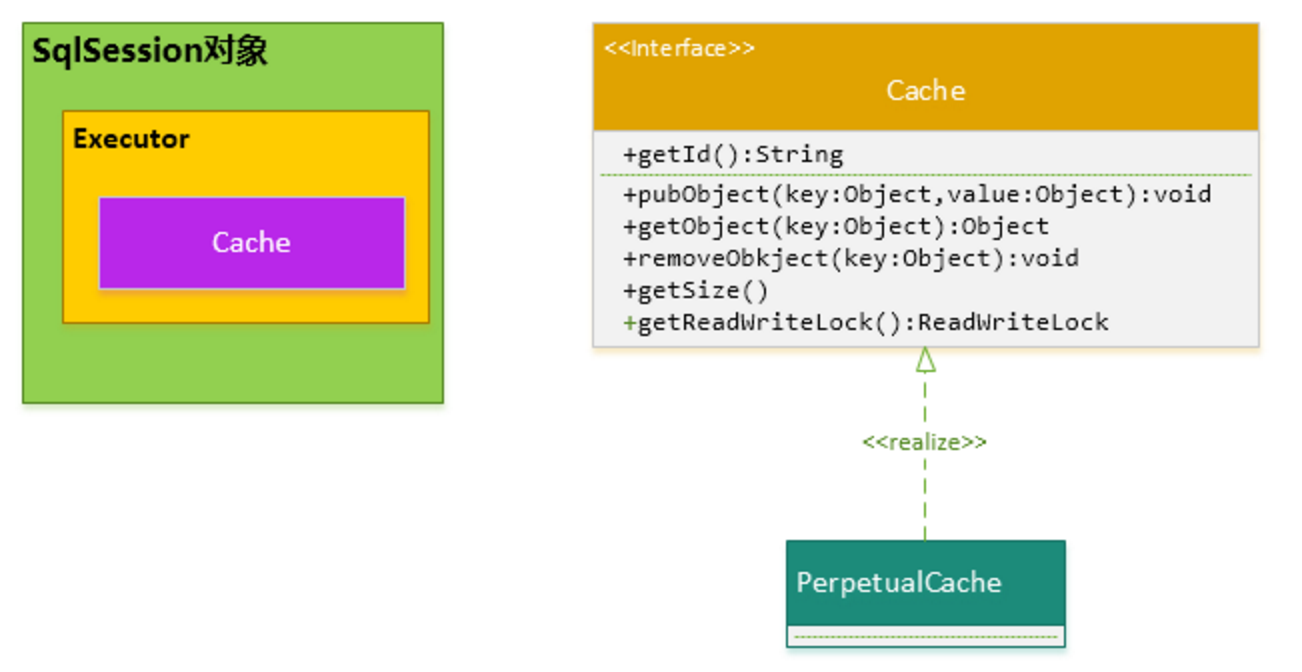
由于 Session 级别的一级缓存实际上就是使用 PerpetualCache 维护的,那么 PerpetualCache 是怎样实现的呢?
PerpetualCache 实现原理其实很简单,其内部就是通过一个简单的 HashMap
package org.apache.ibatis.cache.impl;import java.util.HashMap;import java.util.Map;import java.util.concurrent.locks.ReadWriteLock;import org.apache.ibatis.cache.Cache;import org.apache.ibatis.cache.CacheException;/*** 使用简单的HashMap来维护缓存* @author Clinton Begin*/public class PerpetualCache implements Cache {private String id;private Map<Object, Object> cache = new HashMap<Object, Object>();public PerpetualCache(String id) {this.id = id;}public String getId() {return id;}public int getSize() {return cache.size();}public void putObject(Object key, Object value) {cache.put(key, value);}public Object getObject(Object key) {return cache.get(key);}public Object removeObject(Object key) {return cache.remove(key);}public void clear() {cache.clear();}public ReadWriteLock getReadWriteLock() {return null;}public boolean equals(Object o) {if (getId() == null) throw new CacheException("Cache instances require an ID.");if (this == o) return true;if (!(o instanceof Cache)) return false;Cache otherCache = (Cache) o;return getId().equals(otherCache.getId());}public int hashCode() {if (getId() == null) throw new CacheException("Cache instances require an ID.");return getId().hashCode();}}
一级缓存的生命周期有多长?
MyBatis 在开启一个数据库会话时,会创建一个新的 SqlSession 对象,SqlSession 对象中会有一个新的 Executor 对象,Executor 对象中持有一个新的 PerpetualCache 对象;当会话结束时,SqlSession 对象及其内部的 Executor 对象还有 PerpetualCache 对象也一并释放掉。
- 如果 SqlSession 调用了 close () 方法,会释放掉一级缓存 PerpetualCache 对象,一级缓存将不可用;
- 如果 SqlSession 调用了 clearCache (),会清空 PerpetualCache 对象中的数据,但是该对象仍可使用;
- SqlSession 中执行了任何一个 update 操作 (update ()、delete ()、insert ()) ,都会清空 PerpetualCache 对象的数据,但是该对象可以继续使用;
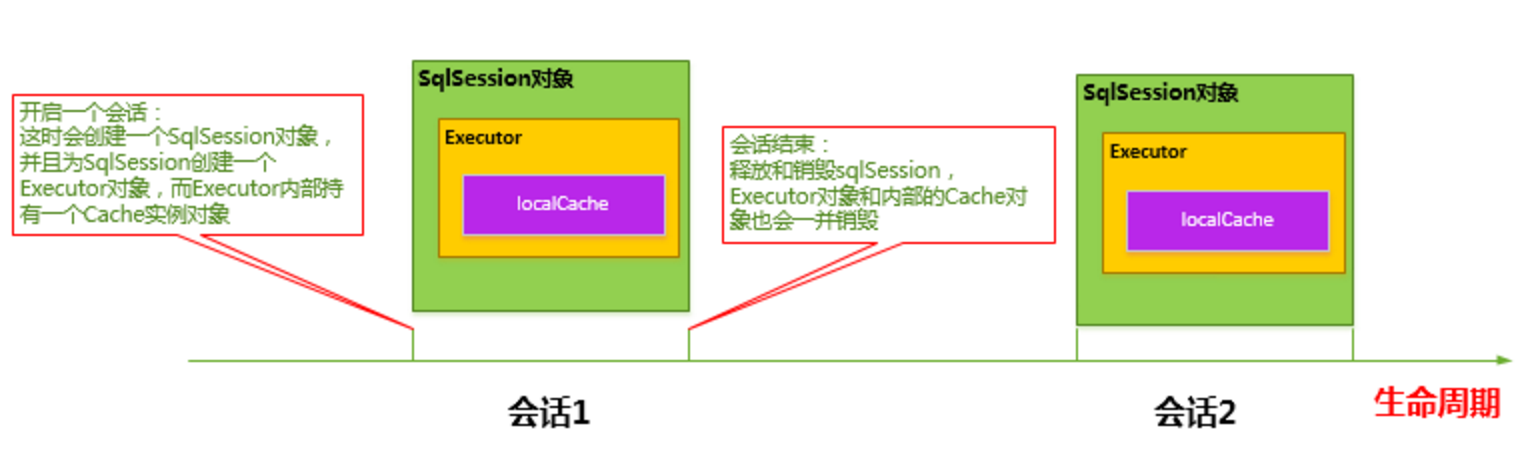
SqlSession 一级缓存的工作流程
- 对于某个查询,根据 statementId,params,rowBounds 来构建一个 key 值,根据这个 key 值去缓存 Cache 中取出对应的 key 值存储的缓存结果;
- 判断从 Cache 中根据特定的 key 值取的数据数据是否为空,即是否命中;
- 如果命中,则直接将缓存结果返回;
- 如果没命中:
- 去数据库中查询数据,得到查询结果;
- 将 key 和查询到的结果分别作为 key,value 对存储到 Cache 中;
- 将查询结果返回;
- 结束。

Cache 接口的设计以及 CacheKey 的定义
如下图所示,MyBatis 定义了一个 org.apache.ibatis.cache.Cache 接口作为其 Cache 提供者的 SPI (Service Provider Interface) ,所有的 MyBatis 内部的 Cache 缓存,都应该实现这一接口。MyBatis 定义了一个 PerpetualCache 实现类实现了 Cache 接口,实际上,在 SqlSession 对象里的 Executor 对象内维护的 Cache 类型实例对象,就是 PerpetualCache 子类创建的。
(MyBatis 内部还有很多 Cache 接口的实现,一级缓存只会涉及到这一个 PerpetualCache 子类,Cache 的其他实现将会放到二级缓存中介绍)。
我们知道,Cache 最核心的实现其实就是一个 Map,将本次查询使用的特征值作为 key,将查询结果作为 value 存储到 Map 中。现在最核心的问题出现了:怎样来确定一次查询的特征值?换句话说就是:怎样判断某两次查询是完全相同的查询?也可以这样说:如何确定 Cache 中的 key 值?
MyBatis 认为,对于两次查询,如果以下条件都完全一样,那么就认为它们是完全相同的两次查询:
- 传入的 statementId
- 查询时要求的结果集中的结果范围 (结果的范围通过 rowBounds.offset 和 rowBounds.limit 表示)
- 这次查询所产生的最终要传递给 JDBC java.sql.Preparedstatement 的 Sql 语句字符串(boundSql.getSql () )
- 传递给 java.sql.Statement 要设置的参数值
现在分别解释上述四个条件:
- 传入的 statementId,对于 MyBatis 而言,你要使用它,必须需要一个 statementId,它代表着你将执行什么样的 Sql;
- MyBatis 自身提供的分页功能是通过 RowBounds 来实现的,它通过 rowBounds.offset 和 rowBounds.limit 来过滤查询出来的结果集,这种分页功能是基于查询结果的再过滤,而不是进行数据库的物理分页;
- 由于 MyBatis 底层还是依赖于 JDBC 实现的,那么,对于两次完全一模一样的查询,MyBatis 要保证对于底层 JDBC 而言,也是完全一致的查询才行。而对于 JDBC 而言,两次查询,只要传入给 JDBC 的 SQL 语句完全一致,传入的参数也完全一致,就认为是两次查询是完全一致的。
- 上述的第 3 个条件正是要求保证传递给 JDBC 的 SQL 语句完全一致;第 4 条则是保证传递给 JDBC 的参数也完全一致;即 3、4 两条 MyBatis 最本质的要求就是:调用 JDBC 的时候,传入的 SQL 语句要完全相同,传递给 JDBC 的参数值也要完全相同。
综上所述,CacheKey 由以下条件决定:statementId + rowBounds + 传递给 JDBC 的 SQL + 传递给 JDBC 的参数值;
- CacheKey 的创建
对于每次的查询请求,Executor 都会根据传递的参数信息以及动态生成的 SQL 语句,将上面的条件根据一定的计算规则,创建一个对应的 CacheKey 对象。
我们知道创建 CacheKey 的目的,就两个:
- 根据 CacheKey 作为 key, 去 Cache 缓存中查找缓存结果;
- 如果查找缓存命中失败,则通过此 CacheKey 作为 key,将从数据库查询到的结果作为 value,组成 key,value 对存储到 Cache 缓存中;
CacheKey 的构建被放置到了 Executor 接口的实现类 BaseExecutor 中,定义如下:
/*** 所属类: org.apache.ibatis.executor.BaseExecutor* 功能 : 根据传入信息构建CacheKey*/public CacheKey createCacheKey(MappedStatement ms, Object parameterObject, RowBounds rowBounds, BoundSql boundSql) {if (closed) throw new ExecutorException("Executor was closed.");CacheKey cacheKey = new CacheKey();//1.statementIdcacheKey.update(ms.getId());//2. rowBounds.offsetcacheKey.update(rowBounds.getOffset());//3. rowBounds.limitcacheKey.update(rowBounds.getLimit());//4. SQL语句cacheKey.update(boundSql.getSql());//5. 将每一个要传递给JDBC的参数值也更新到CacheKey中List<ParameterMapping> parameterMappings = boundSql.getParameterMappings();TypeHandlerRegistry typeHandlerRegistry = ms.getConfiguration().getTypeHandlerRegistry();for (int i = 0; i < parameterMappings.size(); i++) { // mimic DefaultParameterHandler logicParameterMapping parameterMapping = parameterMappings.get(i);if (parameterMapping.getMode() != ParameterMode.OUT) {Object value;String propertyName = parameterMapping.getProperty();if (boundSql.hasAdditionalParameter(propertyName)) {value = boundSql.getAdditionalParameter(propertyName);} else if (parameterObject == null) {value = null;} else if (typeHandlerRegistry.hasTypeHandler(parameterObject.getClass())) {value = parameterObject;} else {MetaObject metaObject = configuration.newMetaObject(parameterObject);value = metaObject.getValue(propertyName);}//将每一个要传递给JDBC的参数值也更新到CacheKey中cacheKey.update(value);}}return cacheKey;}
- CacheKey 的 hashcode 生成算法
刚才已经提到,Cache 接口的实现,本质上是使用的 HashMap
public void update(Object object) {if (object != null && object.getClass().isArray()) {int length = Array.getLength(object);for (int i = 0; i < length; i++) {Object element = Array.get(object, i);doUpdate(element);}} else {doUpdate(object);}}private void doUpdate(Object object) {//1. 得到对象的hashcode;int baseHashCode = object == null ? 1 : object.hashCode();//对象计数递增count++;checksum += baseHashCode;//2. 对象的hashcode 扩大count倍baseHashCode *= count;//3. hashCode * 拓展因子(默认37)+拓展扩大后的对象hashCode值hashcode = multiplier * hashcode + baseHashCode;updateList.add(object);}
MyBatis 认为的完全相同的查询,不是指使用 sqlSession 查询时传递给算起来 Session 的所有参数值完完全全相同,你只要保证 statementId,rowBounds, 最后生成的 SQL 语句,以及这个 SQL 语句所需要的参数完全一致就可以了。
一级缓存的性能分析
- MyBatis 对会话(Session)级别的一级缓存设计的比较简单,就简单地使用了 HashMap 来维护,并没有对 HashMap 的容量和大小进行限制
读者有可能就觉得不妥了:如果我一直使用某一个 SqlSession 对象查询数据,这样会不会导致 HashMap 太大,而导致 java.lang.OutOfMemoryError 错误啊? 读者这么考虑也不无道理,不过 MyBatis 的确是这样设计的。
MyBatis 这样设计也有它自己的理由:
- 一般而言 SqlSession 的生存时间很短。一般情况下使用一个 SqlSession 对象执行的操作不会太多,执行完就会消亡;
- 对于某一个 SqlSession 对象而言,只要执行 update 操作(update、insert、delete),都会将这个 SqlSession 对象中对应的一级缓存清空掉,所以一般情况下不会出现缓存过大,影响 JVM 内存空间的问题;
- 可以手动地释放掉 SqlSession 对象中的缓存。
- 一级缓存是一个粗粒度的缓存,没有更新缓存和缓存过期的概念
MyBatis 的一级缓存就是使用了简单的 HashMap,MyBatis 只负责将查询数据库的结果存储到缓存中去, 不会去判断缓存存放的时间是否过长、是否过期,因此也就没有对缓存的结果进行更新这一说了。
根据一级缓存的特性,在使用的过程中,我认为应该注意:
- 对于数据变化频率很大,并且需要高时效准确性的数据要求,我们使用 SqlSession 查询的时候,要控制好 SqlSession 的生存时间, SqlSession 的生存时间越长,它其中缓存的数据有可能就越旧,从而造成和真实数据库的误差;同时对于这种情况,用户也可以手动地适时清空 SqlSession 中的缓存;
- 对于只执行、并且频繁执行大范围的 select 操作的 SqlSession 对象,SqlSession 对象的生存时间不应过长。

若有收获,就点个赞吧
0 人点赞
