1.集中过期
Ref: https://pdai.tech/md/db/nosql-redis/db-redis-x-performance.html
如果你发现,平时在操作 Redis 时,并没有延迟很大的情况发生,但在某个时间点突然出现一波延时,其现象表现为:变慢的时间点很有规律,例如某个整点,或者每间隔多久就会发生一波延迟。如果是出现这种情况,那么你需要排查一下,业务代码中是否存在设置大量 key 集中过期的情况。
如果有大量的 key 在某个固定时间点集中过期,在这个时间点访问 Redis 时,就有可能导致延时变大。
为什么集中过期会导致 Redis 延迟变大?
这就需要我们了解 Redis 的过期策略是怎样的。
Redis 的过期数据采用被动过期 + 主动过期两种策略。
1.1 被动过期(惰性删除)
只有当访问某个 key 时,才判断这个 key 是否已过期,如果已过期,则从实例中删除(在 Redis 主线程中执行)。
int getGenericCommand(redisClient *c) {robj *o;// lookupKeyReadOrReply 函数会调用 lookupKeyRead 函数,// 后者会调用到 expireIfNeeded 先检测是否过期了if ((o = lookupKeyReadOrReply(c,c->argv[1],shared.nullbulk)) == NULL)return REDIS_OK;if (o->type != REDIS_STRING) {addReply(c,shared.wrongtypeerr);return REDIS_ERR;} else {addReplyBulk(c,o);return REDIS_OK;}}int expireIfNeeded(redisDb *db, robj *key) {mstime_t when = getExpire(db,key);mstime_t now;/* If we are running in the context of a slave, return ASAP:* the slave key expiration is controlled by the master that will* send us synthesized DEL operations for expired keys.** Still we try to return the right information to the caller,* that is, 0 if we think the key should be still valid, 1 if* we think the key is expired at this time. */if (server.masterhost != NULL) return now > when;}
如果当前实例为 slave 则直接返回,不会做进一步的处理;作者也做了注释,说 slave 上过期的 key 会依赖 master 发过来的 DEL 命令来删除。
redis 的惰性删除机制是在执行用户请求的时候判断 key 是否过期,惰性删除也只在 master 上生效,slave 上是不生效的。
1.2 主动过期(主动删除)
Redis 内部维护了一个定时任务,默认每隔 100 毫秒(1 秒 10 次)就会从全局的过期哈希表中随机取出 20 个 key,然后随机删除其中过期的 key,如果过期 key 的比例超过了 25%,则继续重复此过程,直到过期 key 的比例下降到 25% 以下,或者这次任务的执行耗时超过了 25 毫秒,才会退出循环。防止执行时间太长会抢占太多 CPU。
注意,这个主动过期 key 的定时任务,是在 Redis 主线程中执行的。
(100ms -> 删除20个key -> 大于25% -> 循环 -> 超时25ms退出)
也就是说如果在执行主动过期的过程中,出现了需要大量删除过期 key 的情况,那么此时应用程序在访问 Redis 时,必须要等待这个过期任务执行结束,Redis 才可以服务这个客户端请求。从而导致应用访问 Redis 延时变大。
如果此时需要过期删除的是一个 bigkey,那么这个耗时会更久。而且,这个操作延迟的命令并不会记录在慢日志中。因为慢日志中只记录一个命令真正操作内存数据的耗时,而 Redis 主动删除过期 key 的逻辑,是在命令真正执行之前执行的。
所以,此时你会看到,慢日志中没有操作耗时的命令,但我们的应用程序却感知到了延迟变大,其实时间都花费在了删除过期 key 上,这种情况我们需要尤为注意。
排查定位
那遇到这种情况,如何分析和排查?
此时,你需要检查你的业务代码,是否存在集中过期 key 的逻辑。
一般集中过期使用的是 expireat /pexpireat 命令,你需要在代码中搜索这个关键字。
排查代码后,如果确实存在集中过期 key 的逻辑存在,但这种逻辑又是业务所必须的,那此时如何优化,同时又不对 Redis 有性能影响呢?
优化方案
一般有两种方案来规避这个问题:
- 集中过期 key 增加一个随机过期时间,把集中过期的时间打散,降低 Redis 清理过期 key 的压力
- 如果你使用的 Redis 是 4.0 以上版本,可以开启 lazy-free 机制,当删除过期 key 时,把释放内存的操作放到后台线程中执行,避免阻塞主线程
第一种方案,在设置 key 的过期时间时,增加一个随机时间,伪代码可以这么写:
# 在过期时间点之后的 5 分钟内随机过期掉redis.expireat(key, expire_time + random(300))
第二种方案,Redis 4.0 以上版本,开启 lazy-free 机制:
# 释放过期 key 的内存,放到后台线程执行lazyfree-lazy-expire yes
另外,除了业务层面的优化和修改配置之外,你还可以通过运维手段及时发现这种情况。
运维层面,你需要把 Redis 的各项运行状态数据监控起来,在 Redis 上执行 INFO 命令就可以拿到这个实例所有的运行状态数据。
在这里我们需要重点关注 expired_keys 这一项,它代表整个实例到目前为止,累计删除过期 key 的数量。
你需要把这个指标监控起来,当这个指标在很短时间内出现了突增,需要及时报警出来,然后与业务应用报慢的时间点进行对比分析,确认时间是否一致,如果一致,则可以确认确实是因为集中过期 key 导致的延迟变大。
2.过期 key 仍存在于 slave
Ref: https://segmentfault.com/a/1190000021705441
公司去年上线一个抽奖系统,主要用来拉新、提升流量,所有新注册的用户在指定时间都可以抽奖,为了保证安全性,程序中做了频率限制,每个用户 30 秒只能抽 1 次,具体做法是以用户 id 为 key,保存在 redis 中,过期时间为 30 秒;抽奖时会先读取这个 key 是否存在,如果存在则认为用户在 30 秒内已经抽过,返回稍后再试。
因为读多写少,为了提高系统的吞吐量,系统采用了 redis 读、写分离的架构,即写入的时候往 master 上写,读取用户是否抽过奖则从 slave 上读取,redis 版本为 2.8.6。
这个系统上线后前几天运行比较良好,某天突然报大量的稍后重试的错误,不少用户反馈抽了一次奖后再也无法抽奖。
通过日志分析和数据核对发现某个 key 过期了,但在 slave 上还可以读取的到。
复现如下:
在 master 上设置一个 key,并设置过期时间:
set name edwardexpire name 5
过了 5 秒等 key 过期后再到 slave 上读取,但 get 返回不为空: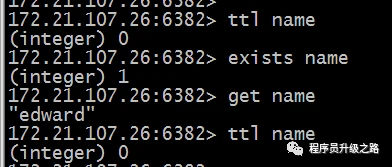
但这个时候如果在 master 上 get 1 次,再到 slave 上 get,结果就是空了。
原因分析
1、redis 中过期 key 的删除有 2 种策略:主动删除、惰性删除。
2、主动删除和惰性删除只在 master 上发生,slave 的删除机制依赖于 master。
回到上面的问题,是什么原因导致 key 过期了,而 slave 上还有值。
因为 master 没有及时将过期的 key 删除,即没有触发主动删除机制,这时候也没有在 master 上读取数据,即执行 get 命令,所以也不会触发 master 上的惰性删除机制,所以 slave 上的 key 没有及时删除。
为什么 master 的主动删除没有触发:

若有收获,就点个赞吧
0 人点赞
