Ref:
https://blog.csdn.net/lupengfei1009/article/details/114525762
https://www.cnblogs.com/javazhiyin/p/13327925.html
liangliangLee
MQ 选型
| MQ | 描述 |
|---|---|
| RabbitMQ | erlang 开发,对消息堆积的支持并不好,当大量消息积压的时候,会导致 RabbitMQ 的性能急剧下降。每秒钟可以处理几万到十几万条消息。 |
| RocketMQ | java 开发,面向集群化,功能丰富,对在线业务的响应时延做了很多的优化,大多数情况下可以做到毫秒级的响应,每秒钟大概能处理几十万条消息。 |
| Kafka | Scala 开发,面向日志,功能丰富,性能最高。业务场景中,每秒钟消息数量没有那么多的时候,Kafka 的时延反而会比较高。所以,Kafka 不太适合在线业务场景。 |
| ActiveMQ | java 开发,简单,稳定,性能不如前面三个。小型系统用也 ok,但是不推荐。 |
- 如果消息队列不是将要构建系统的重点,对消息队列功能和性能没有很高的要求,只需要一个快速上手易于维护的消息队列,建议使用 RabbitMQ。
- 如果系统使用消息队列主要场景是处理在线业务,比如在交易系统中用消息队列传递订单,需要低延迟和高稳定性,建议使用 RocketMQ。
- 如果需要处理海量的消息,像收集日志、监控信息或是埋点这类数据,或是你的应用场景大量使用了大数据、流计算相关的开源产品,那 Kafka 是最适合的消息队列。
MQ 优缺点
优点
因为项目比较大,做了分布式系统,所有远程服务调用请求都是同步执行经常出问题,所以引入了 mq
| 作用 | 描述 |
|---|---|
| 解耦 | 系统耦合度降低,没有强依赖关系 |
| 异步 | 不需要同步执行的远程调用可以有效提高响应时间 |
| 削峰 | 请求达到峰值后,后端 service 还可以保持固定消费速率消费,不会被压垮 |
缺点
- 系统可用性降低
系统引入的外部依赖越多,越容易挂掉。本来你就是 A 系统调用 B、C、D 三个系统的接口就好了,人 A、B、C、D 四个系统好好的,没啥问题,你偏加个 MQ 进来,万一 MQ 挂了咋整,MQ 一挂,整套系统崩溃的,你不就完了?如何保证消息队列的高可用,可以点击这里查看。
- 系统复杂度提高
硬生生加个 MQ 进来,你怎么保证消息没有重复消费?怎么处理消息丢失的情况?怎么保证消息传递的顺序性?头大头大,问题一大堆,痛苦不已。
- 一致性问题
A 系统处理完了直接返回成功了,人都以为你这个请求就成功了;但是问题是,要是 B、C、D 三个系统那里,B、D 两个系统写库成功了,结果 C 系统写库失败了,咋整?你这数据就不一致了。
所以消息队列实际是一种非常复杂的架构,引入 MQ 有很多好处,但是也得针对它带来的坏处做各种额外的技术方案和架构来规避掉,做好之后,你会发现,系统复杂度提升了一个数量级,也许是复杂了 10 倍。但是关键时刻,还是得用的。
消息的顺序问题
消息有序指的是可以按照消息的发送顺序来消费。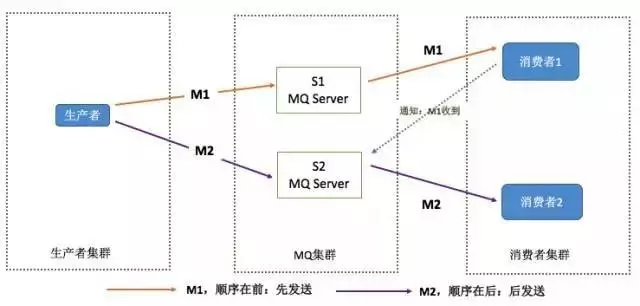
假如生产者产生了 2 条消息:M1、M2,假定 M1 发送到 S1,M2 发送到 S2,如果要保证 M1 先于 M2 被消费,怎么做?
- 保证生产者 - MQServer - 消费者是一对一对一的关系
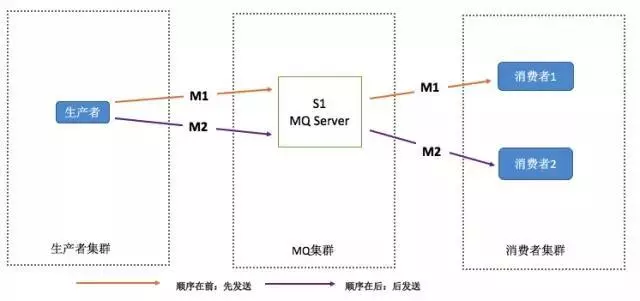
缺陷:
- 并行度就会成为消息系统的瓶颈(吞吐量不够)
- 更多的异常处理,比如:只要消费端出现问题,就会导致整个处理流程阻塞,我们不得不花费更多的精力来解决阻塞的问题。
- 通过合理的设计或者将问题分解来规避
队列无序并不意味着消息无序,所以从业务层面来保证消息的顺序而不仅仅是依赖于消息系统,是一种更合理的方式。
消息的重复问题
- 数据库表(幂等)
消费端处理消息的业务逻辑保持幂等性。保持幂等性,最后处理的结果都一样。
保证每条消息都有唯一编号且保证消息处理成功,利用一张日志表来记录已经处理成功的消息的 ID,如果新到的消息 ID 已经在日志表中,那么就不再处理这条消息。
- 分布式锁
Redis 等分布式锁

若有收获,就点个赞吧
0 人点赞
