如下 sqlmap 是常见的写法,当遇到 SQL 性能问题的时,id 字段已经加了索引,貌似已经没有优化的空间。但是为什么还会慢呢?只能归咎于数据库的抖动?其实不然。
<select id="selectByIds" parameterType="org.blackist.lifer.order.OrderQuery">select * from orderwhere rect_id = #{rectId}and id IN<foreach collection="ids" item="id" open="(" separator="," close=")">#{id}</foreach></select>
mybatis 执行过程
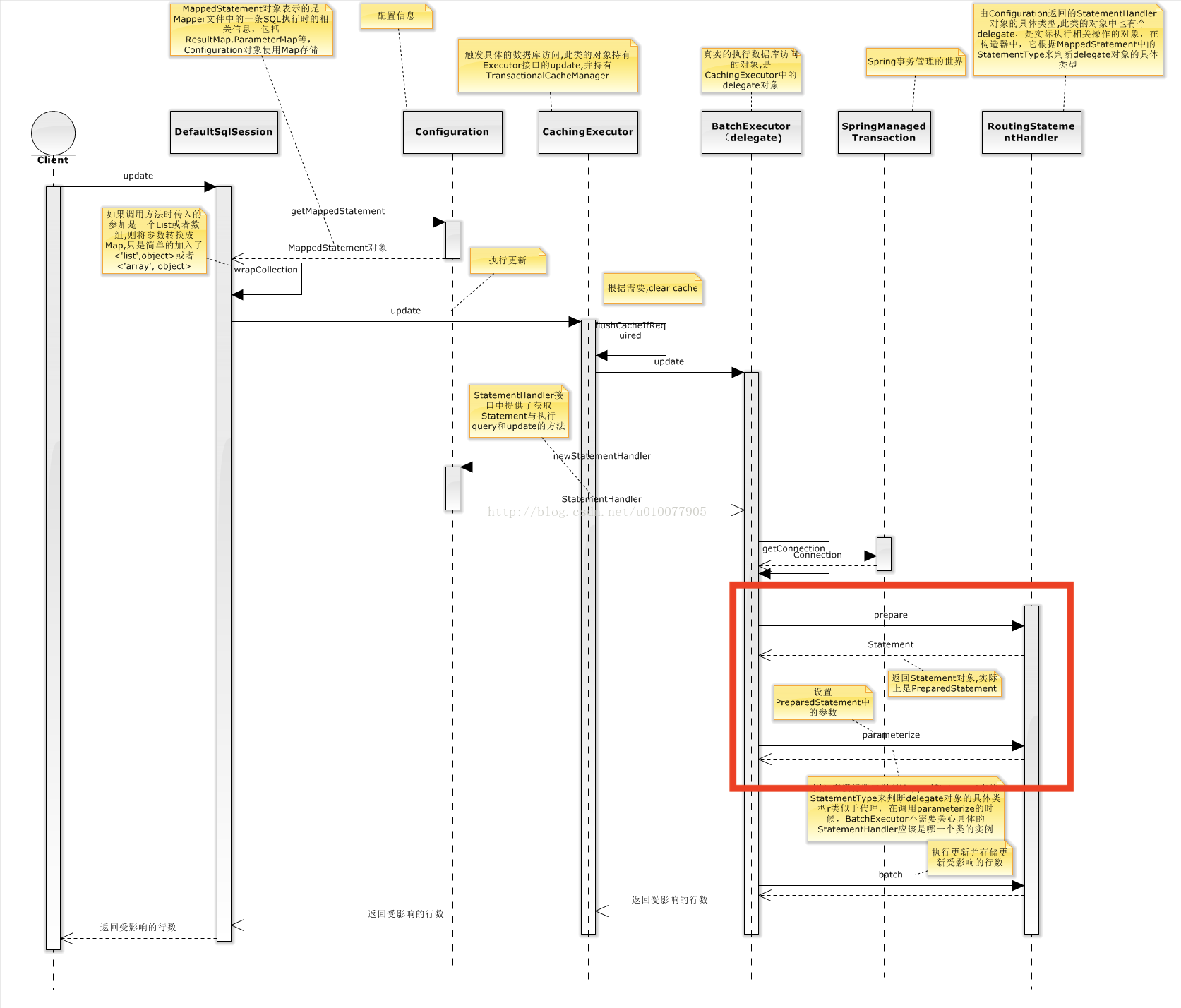
mybatis 的执行过程简单分为四步:
getConnection → prepare → parameterize → execute
- getConnection:顾名思义,就是获取数据库连接的
- prepare:预处理,这个是因为 mysql 有一个词法语义解析、语句优化、制定执行计划等过程,而预处理的好处就是一次编译多次运行,可以大大提高运行效率。基本大部分 mybatis 的配置都会采用这个方式
- parameterize:就是将占位符转换成真正的参数,放入到 statement 中的过程
- execute:真正的 sql 执行过程
预处理
在设计数据库交互的时候应尽量使用预处理,这是个很重要的性能优化点,先看一下用命令行的执行过程: ```bash PREPARE SQL1 FROM ‘SELECT * FROM test WHERE TEST = ?’;
SET @param = 123;
EXECUTE SQL1 USING @param;
```
这是一次典型的预处理的执行过程。
第二次执行,可以直接跳过预处理过程,直接 set parameter 和 execute 了,性能会提升比较明显。
这个也是为什么系统重新启动的时候需要预热的原因。第一次执行是没有被预处理的,之后速度就上去了。
那么什么情况会导致无法预处理呢?
- 使用
${}符号的 sql,而且这种做法也不安全,有 SQL 注入的风险,所以一般都不会这么写 - 由于
foreach导致每次的参数个数不一样,所以无法预处理
prepare sql1 from 'select * from test where id in (?)'
和prepare sql1 from 'select * from test where id in (?,?)'
这是两条不一样的 SQL(参数个数不一样导致 SQL 长度不一样),是无法预处理的,所以 mybatis 的 foreach 是很容易导致无法预处理的。
慢 SQL
getConnection 阶段
有几种可能:
- 系统刚启动的时候,这个时候数据库连接池中里没有足够可用连接,突然的流量会导致请求排队等待获取/创建连接这种情况,可以在系统启动的时候增加预热的环节。最简单的做法,控制系统流量比如从 5% 逐渐放大至 100% 给一个缓冲的时间
- 系统在经历业务低峰期,突然遇到了突发的流量,导致和上面一样的问题这种情况,注意 mybatis 的配置,将 keepalive 打开即可,这样一直保持一个比较高的可用连接数量在连接池即可。不过这种做法也有一个风险,就是当集群规模比较大的时候,将占住大量的数据库连接。只要提前预估好连接数即可。
有慢 SQL 占住了连接,导致其他 SQL 无法获取连接,导致 getConnection 阶段比较慢。这种情况比较危险,应该及时处理慢 SQL,保持连接池一个比较健康的水平
prepare 阶段
复杂的 SQL 会导致预处理慢,这个跟 SQL 本身有关系。
这种情况比较好解决和发现,只要注意简化 SQL,或者拆分成几个sql执行即可另外一种情况,SQL 本身不复杂,但是 in 语句的循环次数非常多。甚至上百个或上千的 in 的参数。同时配合其他查询条件,整个预处理过程也是比较慢的。
一般来说 in 中的查询条件,基本都会有索引,所以提前将重复的查询条件过滤掉,提前排序是一种优化手法。另外预估 in 的条件数量是非常必要的。
如果需要大量的 in 查询条件,那么就要考虑是否可以通过冗余的方式或者用 exist 替换 in 的查询。这种问题隐藏的比较深容易被忽略到线上,做好监控是很重要的。parameterize 阶段
execute 阶段
这个过程的性能问题,一般是大家都比较熟悉的
没有走合适的索引:通过expian命令查询执行计划,合理规划索引即可。不过注意索引不是越多越好的,一般不超过4个
- using filesort:尽量通过数据库索引的顺序性做排序,合理安排索引的顺序,针对大量的数据排序,如果出现using filesort一般都会比较慢,要避免
- 锁竞争数据库的锁的问题,是面试高频问题,相信大家都比较熟悉了。注意几点即可:
- 不要搞大事务,例如批量插入1万条数据,这是会被DBA砍死的
- 合理使用行锁,控制锁的粒度和持有时间
- 业务高峰期,不要做表结构变更
- 将热点数据拆分成多条子数据,例如将一个账户拆分成多个子账户,这样在操作余额的时候可以降低锁的竞争
- …foreach 性能问题
Mybatis 本身的 foreach 性能问题,处理标签时,代码本身的处理逻辑并不高效,通过不断的循环生成 (?,?,?,…,?)。
再加上预处理的过程,所以最终结果会导致 SQL 非常慢。这是 mybatis 本身的代码问题,跟数据库没有关系。
在内存中拼接好字符串然后用 in ${ids} 类似的做法,依然无法根本解决 SQL 慢的问题,原因还是无法做预处理和预处理本身慢的问题。大量的这种预处理可能导致数据库 CPU 负载升高导致整个响应比较慢。
提高数据库的核数,增加处理能力。
推荐方案
- 首先并不是完全不能用foreach,毕竟这个是比较简洁的查询方案,而且在数据不大且有索引的时候,效率还是不错的。
- 其次一般用到 foreach 的场景,可以用适当的冗余把查询的条件数据维度降下去,用空间换时间。
- 尝试用表连接查询,不过这种做法也比较危险,可能会 join 出一个大表,其次很多时候 DBA 是不太建议这种连表查询的。需要有把握和评估数据量的时候再用。
- 很可能就是获取连接慢,跟 prepare 和 execute 没关系。

若有收获,就点个赞吧
0 人点赞
