Ref: https://pdai.tech/md/db/nosql-redis/db-redis-x-redis-ds.html
底层数据结构:
- 简单动态字符串 - sds
- 压缩列表 - ZipList
- 快表 - QuickList
- 字典 / 哈希表 - Dict
- 整数集 - IntSet
-
简单动态字符串 - sds
Redis 是用 C 语言写的,但是对于 Redis 的字符串,却不是 C 语言中的字符串(即以空字符 ‘\0’ 结尾的字符数组),它是自己构建了一种名为 简单动态字符串(simple dynamic string, SDS)的抽象类型,并将 SDS 作为 Redis 的默认字符串表示。
SDS 定义
这是一种用于存储二进制数据的一种结构,具有动态扩容的特点。其实现位于 src/sds.h 与 src/sds.c 中。
SDS 的总体概览如下图:

其中 sdshdr 是头部,buf 是真实存储用户数据的地方。另外注意,从命名上能看出来,这个数据结构除了能存储二进制数据,显然是用于设计作为字符串使用的,所以在 buf 中,用户数据后总跟着一个 \0. 即图中 “数据” + “\0” 是为所谓的 buf。
- 如下是 6.0 源码中 sds 相关的结构:

通过上图我们可以看到,SDS 有五种不同的头部。其中 sdshdr5 实际并未使用到。所以实际上有四种不同的头部,分别如下: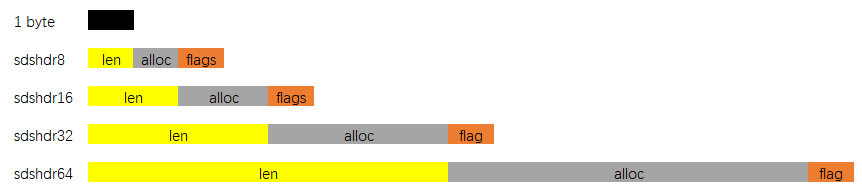
其中:
- len 保存了 SDS 保存字符串的长度
- buf[] 数组用来保存字符串的每个元素
- alloc 分别以 uint8, uint16, uint32, uint64 表示整个 SDS, 除过头部与末尾的 \0, 剩余的字节数.
flags 始终为一字节,以低三位标示着头部的类型,高 5 位未使用.
为什么使用 SDS
为什么不使用 C 语言字符串实现,而是使用 SDS 呢?这样实现有什么好处?
常数复杂度获取字符串长度
由于 len 属性的存在,我们获取 SDS 字符串的长度只需要读取 len 属性,时间复杂度为 O (1)。而对于 C 语言,获取字符串的长度通常是经过遍历计数来实现的,时间复杂度为 O (n)。通过 strlen key 命令可以获取 key 的字符串长度。
- 杜绝缓冲区溢出
我们知道在 C 语言中使用 strcat 函数来进行两个字符串的拼接,一旦没有分配足够长度的内存空间,就会造成缓冲区溢出。而对于 SDS 数据类型,在进行字符修改的时候,会首先根据记录的 len 属性检查内存空间是否满足需求,如果不满足,会进行相应的空间扩展,然后在进行修改操作,所以不会出现缓冲区溢出。
- 减少修改字符串的内存重新分配次数
C 语言由于不记录字符串的长度,所以如果要修改字符串,必须要重新分配内存(先释放再申请),因为如果没有重新分配,字符串长度增大时会造成内存缓冲区溢出,字符串长度减小时会造成内存泄露。
而对于 SDS,由于 len 属性和 alloc 属性的存在,对于修改字符串 SDS 实现了空间预分配和惰性空间释放两种策略:
1、空间预分配:对字符串进行空间扩展的时候,扩展的内存比实际需要的多,这样可以减少连续执行字符串增长操作所需的内存重分配次数。
2、惰性空间释放:对字符串进行缩短操作时,程序不立即使用内存重新分配来回收缩短后多余的字节,而是使用 alloc 属性将这些字节的数量记录下来,等待后续使用。(当然 SDS 也提供了相应的 API,当我们有需要时,也可以手动释放这些未使用的空间。)
- 二进制安全
因为 C 字符串以空字符作为字符串结束的标识,而对于一些二进制文件(如图片等),内容可能包括空字符串,因此 C 字符串无法正确存取;而所有 SDS 的 API 都是以处理二进制的方式来处理 buf 里面的元素,并且 SDS 不是以空字符串来判断是否结束,而是以 len 属性表示的长度来判断字符串是否结束。
- 兼容部分 C 字符串函数
虽然 SDS 是二进制安全的,但是一样遵从每个字符串都是以空字符串结尾的惯例,这样可以重用 C 语言库
空间预分配补进一步理解
当执行追加操作时,比如现在给 key=‘Hello World’的字符串后追加‘ again!’则这时的 len=18,free 由 0 变成了 18,此时的 buf=’Hello World again!\0………………..’(. 表示空格),也就是 buf 的内存空间是 18+18+1=37 个字节,其中‘\0’占 1 个字节 redis 给字符串多分配了 18 个字节的预分配空间,所以下次还有 append 追加的时候,如果预分配空间足够,就无须在进行空间分配了。在当前版本中,当新字符串的长度小于 1M 时,redis 会分配他们所需大小一倍的空间,当大于 1M 的时候,就为他们额外多分配 1M 的空间。
思考:这种分配策略会浪费内存资源吗?
答:执行过 APPEND 命令的字符串会带有额外的预分配空间,这些预分配空间不会被释放,除非该字符串所对应的键被删除,或者等到关闭 Redis 之后,再次启动时重新载入的字符串对象将不会有预分配空间。因为执行 APPEND 命令的字符串键数量通常并不多,占用内存的体积通常也不大,所以这一般并不算什么问题。另一方面,如果执行 APPEND 操作的键很多,而字符串的体积又很大的话,那可能就需要修改 Redis 服务器,让它定时释放一些字符串键的预分配空间,从而更有效地使用内存。
小结
redis 的字符串表示为 sds,而不是 C 字符串(以 \0 结尾的 char*), 它是 Redis 底层所使用的字符串表示,它被用在几乎所有的 Redis 模块中。可以看如下对比: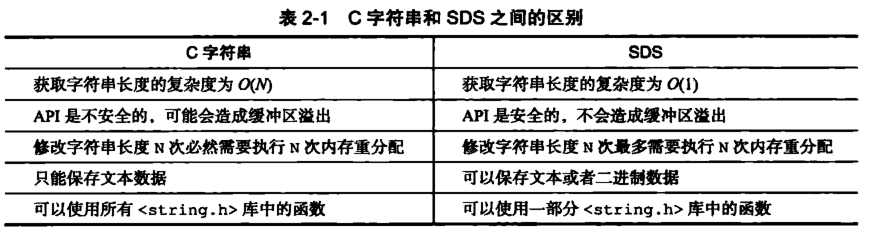
一般来说,SDS 除了保存数据库中的字符串值以外,SDS 还可以作为缓冲区(buffer):包括 AOF 模块中的 AOF 缓冲区以及客户端状态中的输入缓冲区。

若有收获,就点个赞吧
0 人点赞
