Ref: https://cloud.tencent.com/developer/article/1662426
理论基础
Gossip protocol 也叫 Epidemic Protocol (流行病协议),是基于流行病传播方式的节点或者进程之间信息交换的协议。。Gossip protocol 在 1987 年 8 月由施乐公司帕洛阿尔托研究中心研究员艾伦・德默斯(Alan Demers)发表在 ACM 上的论文《Epidemic Algorithms for Replicated Database Maintenance》中被提出。
Gossip 协议是基于六度分隔理论(Six Degrees of Separation)哲学的体现,简单的来说,一个人通过 6 个中间人可以认识世界任何人。数学公式是: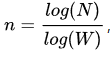
n 表示复杂度,N 表示人的总数,W 表示每个人的联系宽度。依据邓巴数,即每个人认识 150 人,其六度就是 150^6=11,390,625,000,000(约 11.4 万亿)。
基于六度分隔理论,任何信息的传播其实非常迅速,而且网络交互次数不会很多。比如 Facebook 在 2016 年 2 月 4 号做了一个实验:研究了当时已注册的 15.9 亿使用者资料,发现这个神奇数字的 “网络直径” 是 4.57,翻成白话文意味着每个人与其他人间隔为 4.57 人。
概览
Gossip 协议在计算机系统通常以随机的 “对等选择” 形式实现:以给定的频率,每台计算机随机选择另一台计算机,并共享任何消息。定义十分简单,所以实现方式非常多,可能有几百种 Gossip 协议变种。因为每个使用场景都可能根据组织的特定需求进行定制,维基百科上这样写:
There are probably hundreds of variants of specific Gossip-like protocols because each use-scenario is likely to be customized to the organization’s specific needs.
下文解说一种比较原始的 Gossip 协议实现的执行过程、消息类型、通讯方式,以下为 Gossip 协议执行过程:
- 种子节点周期性的散播消息 【假定把周期限定为 1 秒】。
- 被感染节点随机选择 N 个邻接节点散播消息【假定 fan-out (扇出) 设置为 6,每次最多往 6 个节点散播】。
- 节点只接收消息不反馈结果。
- 每次散播消息都选择尚未发送过的节点进行散播。
- 收到消息的节点不回传散播:A -> B,那么 B 进行散播的时候,不再发给 A。
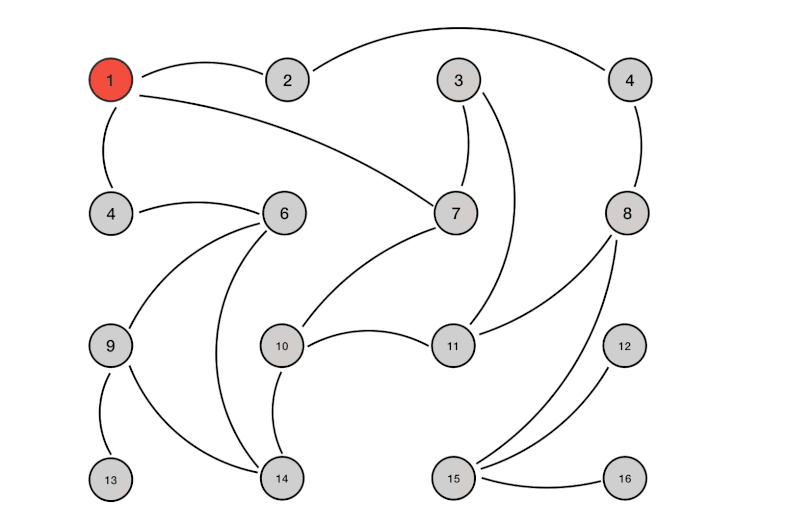
Goosip 协议的信息传播和扩散通常需要由种子节点发起。整个传播过程可能需要一定的时间,由于不能保证某个时刻所有节点都收到消息,但是理论上最终所有节点都会收到消息,因此它是一个最终一致性协议。
Gossip 协议是一个多主协议,所有写操作可以由不同节点发起,并且同步给其他副本。Gossip 内组成的网络节点都是对等节点,是非结构化网络。
传播方式
Gossip 协议的消息传播方式有两种:Anti-Entropy (反熵传播) 和 Rumor-Mongering (谣言传播)。
反熵传播
反熵传播使用 “simple epidemics (SI model)” 的方式:以固定的概率传播所有的数据。所有参与节点只有两种状态:
- Suspective(病原):处于 susceptible 状态的节点代表其并没有收到来自其他节点的更新。
- Infective(感染):处于 infective 状态的节点代表其有数据更新,并且会将这个数据分享给其他节点。
反熵传播过程是每个节点周期性地随机选择其他节点,然后通过互相交换自己的所有数据来消除两者之间的差异。
反熵传播方法每次节点两两交换自己的所有数据会带来非常大的通信负担,因此不会频繁使用,通常只用于新加入节点的数据初始化。
谣言传播
谣言传播使用 “complex epidemics”(SIR model) 的方式:以固定的概率仅传播新到达的数据。所有参与节点有三种状态:Suspective (病原)、Infective (感染)、Removed (愈除)。
- Removed(愈除):其已经接收到来自其他节点的更新,但是其并不会将这个更新分享给其他节点。
谣言传播过程是消息只包含最新 update,谣言消息在某个时间点之后会被标记为 removed,并且不再被传播。缺点是系统有一定的概率会不一致,通常用于节点间数据增量同步。
一般来说,为了在通信代价和可靠性之间取得折中,需要将这两种方法结合使用。
通信方式
Gossip 协议最终目的是将数据分发到网络中的每一个节点。不管是 Anti-Entropy 还是 Rumor-Mongering 都涉及到节点间的数据交互方式,Gossip 网络中两个节点之间存在三种通信方式:Push、Pull 以及 Push&Pull:
- Push: 发起信息交换的节点 A 随机选择联系节点 B,并向其发送自己的信息,节点 B 在收到信息后更新比自己新的数据,一般拥有新信息的节点才会作为发起节点
- Pull:发起信息交换的节点 A 随机选择联系节点 B,并从对方获取信息。一般无新信息的节点才会作为发起节点
- Push&Pull:发起信息交换的节点 A 向选择的节点 B 发送信息,同时从对方获取数据,用于更新自己的本地数据。
如果把两个节点数据同步一次定义为一个周期,则在一个周期内,Push 需通信 1 次,Pull 需 2 次,Push&Pull 则需 3 次。虽然消息数增加了,但从效果上来讲,Push&Pull 最好,理论上一个周期内可以使两个节点完全一致。直观上,Push&Pull 的收敛速度也是最快的。
综上所述,Gossip 协议是按照流言传播或流行病传播的思想实现的,所以,Gossip 协议的实现算法也是很简单的,下面分别是 Anti-Entropy 和 Rumor-Mongering 的实现伪代码:

优缺点
Gossip 是一种去中心化的分布式协议,数据通过节点像病毒一样逐个传播。因为是指数级传播,整体传播速度非常快,很像现在美国失控的 2019-nCoV (新冠) 一样。它具备以下优势:
- 可扩展性(Scalable):允许节点的任意增加和减少,新增节点的状态最终会与其他节点一致。
- 容错(Fault-tolerance):网络中任何节点的重启或者宕机都不会影响 gossip 协议的运行,具有天然的分布式系统容错特性。
- 健壮性(Robust):gossip 协议是去中心化的协议,所以集群中的所有节点都是对等的,没有特殊的节点,所以任何节点出现问题都不会阻止其他节点继续发送消息。任何节点都可以随时加入或离开,而不会影响系统的整体服务质量。
- 最终一致性(Convergent consistency):谣言传播可以是指数级的快速传播,因此新信息传播时,消息可以快速地发送到全局节点,在有限的时间内能够做到所有节点都拥有最新的数据。
- 简单
同样也存在以下缺点:
- 消息延迟:节点随机向少数几个节点发送消息,消息最终是通过多个轮次的散播而到达全网,不可避免的造成消息延迟。
- 消息冗余:节点定期随机选择周围节点发送消息,而收到消息的节点也会重复该步骤,因此不可避免地引起同一节点多次接收同一消息,增加消息处理的压力。一次通信会对网路带宽、CUP 资源造成很大的负载,而这些负载又受限于 通信频率,该频率又影响着算法收敛的速度。
- 拜占庭问题:如果有一个恶意传播消息的节点,Gossip 协议的分布式系统就会出问题。
上述优缺点的本质是因为 Gossip 是一个带冗余的容错算法,是一个最终一致性算法,虽然无法保证在某个时刻所有节点状态一致,但可以保证在 “最终所有节点一致”,“最终” 的时间是一个理论无法明确的时间点。所以适合于 AP 场景的数据一致性处理,常见应用有:P2P 网络通信、Apache Cassandra、Redis Cluster、Consul。

若有收获,就点个赞吧
0 人点赞
