1.索引原理
mysql 索引结构:B+ 树
B+ 树不像 B 树一样,其在内节点上只放置了一个索引信息,而真正全部信息则放在叶子结点上,而 B 树每个节点都是要放置实际数据信息。因为这样,B+ 数的内节点可以放置更多的索引信息。这样在同量的数据情况下,B+ 树的层级更低,是一个矮胖子,B 树则会成为一个瘦高子。而我们的查询效率也正是数的层级越小,查询速度也会更快一些。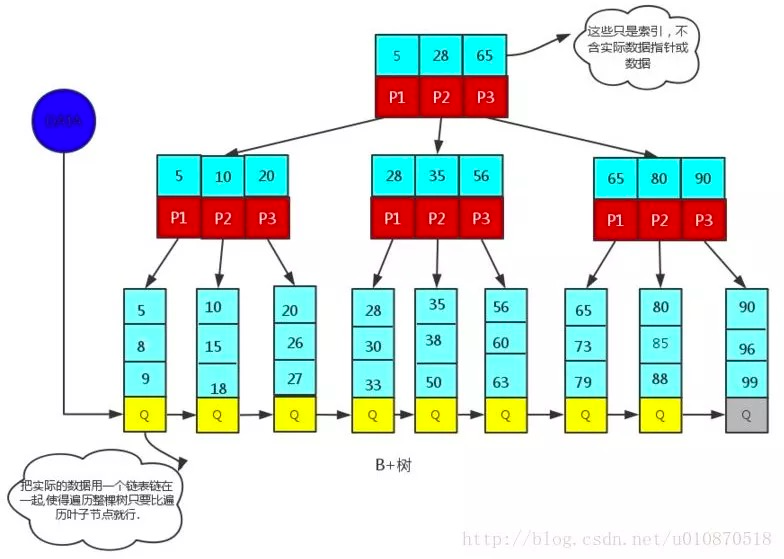
MySQL 索引分为两种,分别是聚簇索引和二级索引。聚簇索引在一张表中只有一个,其内节点上放置的是该表的主键,叶子结点存储了全部数据,二级索引则是我们自己建立的索引,其叶子结点储存了索引的值及主键。
回表:在使用二级索引的时候,由于二级索引上只存储了索引列信息,所以对于非该索引的其他信息,还是需要去聚簇索引上查询,这种情况叫做回表。
同时将这种在二级索引上拿不到数据的情况称为非覆盖索引,能拿到的情况称为覆盖索引。
关于索引节点的信息:
- 聚簇索引内节点 key 列:主键,pageNo 指针叶子节点 key 列:该行全部数据信息
- 二级唯一索引内节点 key 列:唯一索引键,pageNo 指针叶子节点 key 列:唯一索引键,主键
- 二级非唯一索引内节点 key 列:非唯一索引键,主键,pageNo 指针叶子节点 key 列:非唯一索引键,主键。
B+ 树索引原理:https://www.cnblogs.com/tiancai/p/9024351.html
2.最左匹配原则
关于索引的最左匹配原则,一般遇到 > , < , like 时,都会停止使用索引。
如果我们有一个组合索引 idx_c1_c2_c3(c1,c2,c3) 说明 int 类型占用 4 字节。
对于以下查询,分别使用到的索引的 key 是:
| 查询条件 | key-length | 说明 |
|---|---|---|
| where c1 = 1 | 4 | 只匹配索引当中c1列 |
| where c1 = 1 and c2 = 2 | 8 | 匹配索引c1,c2 |
| where c1 = 1 and c2 = 2 and c3 = 3 | 12 | 匹配索引c1,c2,c3 |
| where c1 > 1 and c2 = 2 | 4 | 只能走到索引c1, c2用来筛选 |
| where c1 > 1 and c2 >= 2 | 4 | 只能走到索引c1,c2用来筛选 |
| where c1 > 1 and c2 > 2 | 4 | 只能走到索引c1,c2用来筛选 |
| where c1 = 1 and c2 > 2 and c3 =1 | 8 | 能够走到c1,c2用来筛选 |
| where c1 = 1 and c2 > 2 and c3 >= 1 | 8 | 能够走到c1,c2用来筛选 |
| where c1 = 1 and c2 > 2 and c3 > 1 | 8 | 能够走到c1,c2用来筛选 |
结论:
- 什么时候可以使用到 c1
当 c1 的条件是 >= ,>, = 时
- 什么时候能够使用索引 c1, c2
c1 满足 >= , =
c2 是 >=, =, >时
- 什么时候可以使用到索引 c1, c2, c3
c1 满足 >=,=
c2 满足 >=,=
c3 >=, >, =
对于 c1 between 1 and 4 等同于 c1 >=1 and c1 <= 4
如果此时查询条件是
c1 between 1 and 4 and c2 >=2 and c3 >4
那么将会使用到c1,c2,c3进行过滤
c1 in (2,3,4) and c2 >= 3 and c3 >4
同样也是会使用索引 c1, c2,c3 进行过滤
3.ORDER BY
在了解 mysql 的 order by 语句的执行原理之前,需要对了解归并排序算法,快速排序算法 ,堆排序算法 mysql 当中使用了常规排序和优化排序,对于 limit m,n 也做了特别的优化。
3.1 常规排序
1)从表当中获取满足条件的记录
2)对于每条记录,会记录主键+排序键(id+col2)到 sort buffer 当中
3)当 sort buffer 中可以存放所有的(id+col2)时,则进行排序,如果 sort buffer 满了之后,将其排序,然后固化到临时文件当中(sort buffer 内使用的是快速排序)
4)对于第三步当中产生的临时文件,他们之间使用归并排序算法进行排序,保证临时文件之间的数据是有序的
5)循环上述步骤,直到所有的记录都是有序的
6)对于上述排好序的数据(id+col2),根据id 回表查询 c1,c2,c3 等列
7)返回用户所需要的数据
总结:上述排序的时间瓶颈在于 sort buffer 的大小,第二是读取磁盘 IO 的次数,buffer 的大小是通过 sort_buffer_size 来进行控制,而 IO 执行的次数,这里是需要两次读取磁盘IO:
- 第一次是捞(id,col2),由于使用 col2 进行排序,id 是无序的,
- 第二次根据 id 回表查询行数据,在使用 id 回表查询(c1,c2,c3)时,id 的无序将导致大量的随机 IO。
对于第二次 IO,mysql 有一个优化,就是通过 id 回表查询行数据之前,对 id 进行了排序,并将其放入到缓冲区当中,这个缓冲区的大小通过 read_rnd_buffer_size 来控制,将随机 IO 转为顺序 IO。
3.2 优化排序
对于常规排序,除了排序本身,还要进行两次 IO 的读取,优化排序在此基础上减少了第二次的 IO, 最主要的区别是,放在 sort buffer 当中的是(c1,c2,c3) 而不是(id+col2), sort buffer 当中存放了排序之后所要返回的所有数据,那么就不需要进行二次回表查询数据。
不足:在 sort buffer 大小固定的情况下,存放(c1,c2,c3)的数据量要小于存放(id+col2)的量,如果 sort buffer 不够大的话,需要进行归并排序算法进行排序,增加了读取磁盘的次数,mysql 提供了 max_length_for_sort_data 配置,当我们的排序元组小于 max_length_for_sort_data 时,才会使用优化排序算法,否则只能使用常规排序算法。
3.3 优先队列排序
在 mysql 5.6 版本,针对于 order by limit m, n 的排序进行了优化,加入了一种新的排序方式,优先队列,其实现是通过堆排序,排序的过程仍然需要所有的满足条件的记录进行排序,但是只需要 m+n 个元组空间即可,如果 m,n 很小的情况下,基本上不会因为 sort buffer 空间不足,而进行归并排序,对于升序,采用大顶锥,获取到最小的 n 个元素。
3.4 分页查询数据重复问题
在生产环境当中用户在导出报表时,会发现导出的数据有重复。
原因:mysql5.6 开始,对于 order by col1 limit m,n 采用上述优先队列的排序方式,生产环境导出的查询语句是 order by created_at limit 0,20
| id | created_at | skuId |
|---|---|---|
| id | created_at | skuId |
| 1 | 2018-10-01 | 12 |
| 2 | 2018-10-02 | 32 |
| 3 | 2018-10-02 | 33 |
| 4 | 2018-10-02 | 23 |
| 5 | 2018-10-03 | 13 |
| 6 | 2018-10-04 | 24 |
select * from stock_bill order by created_at limit 0,3 查询结果
| ID | created_at | skuId |
|---|---|---|
| 1 | 2018-10-01 | 12 |
| 2 | 2018-10-02 | 32 |
| 4 | 2018-10-02 | 23 |
select * from stock_bill order by created_at limit 3,3 查询结果
| id | created_at | skuId |
|---|---|---|
| 4 | 2018-10-02 | 23 |
| 5 | 2018-10-03 | 13 |
| 6 | 2018-10-04 | 24 |
id 为 4 的数据出现了两次,原因在于使用了堆排序,order by created_at asc limit 0,3 需要大小为 3 的大顶堆,order by created_at asc limit 3,3 需要大小为 6 的大顶堆,created_at 等于 2018-10-02 的数据有三条,而堆排序是不稳定的,对于 key 相同的数据,不能保证排序前和排序后的位置一致,就会出现分页重复的问题,简单的解决方式就是 order by created_at ,id limit m,n
索引有序性
对于是否使用到索引有序性,严格遵守上面的第三条
create table t1(id int not null primary key ,key_part1 int(10) not null,key_part2 varchar(10) not null default '',key_part3key idx_kp1_kp2(key_part1,key_part2,key_part4),key idx_kp3(id)) engine=innodb default charset=utf8
以下案例当中是可以使用到索引有序性的例子,官方例子官方给出可以使用索引有序性进行排序的例子
SELECT * FROM t1 ORDER BY key_part1, key_part2 ;SELECT * FROM t1 ORDER BY key_part1 DESC, key_part2 DESC;SELECT * FROM t1 WHERE key_part1 = 1 ORDER BY key_part2;SELECT * FROM t1 WHERE key_part1 = 1 ORDER BY key_part1 DESC, key_part2 DESC;SELECT * FROM t1 WHERE key_part1 = 3 AND key_part2 > 3 ORDER BY key_part2SELECT * FROM t1 WHERE key_part1 > 2 ORDER BY key_part1 ASC;SELECT * FROM t1 WHERE key_part1 < 4 ORDER BY key_part1 DESC;
主要是不能使用到索引有序性的例子
1 最常见的情况 用来查找结果的索引(key2) 和排序的索引(key1) 不一样,where a=x and b=y order by id;
SELECT FROM t1 WHERE key_part2 = 3 ORDER BY key_part1;
2 排序字段在不同的索引中,无法使用索引排序
SELECT FROM t1 ORDER BY key_part1, id;
3 排序字段顺序与索引中列顺序不一致,无法使用索引排序
SELECT FROM t1 ORDER BY key_part2, key_part1;
4 order by 中的升降序和索引中的默认升降不一致,无法使用索引排序
SELECT FROM t1 ORDER BY key_part1 DESC, key_part2 ASC;
5 key_part1 是范围查询,key_part2 无法使用索引排序
SELECT FROM t1 WHERE key_part1> 3 ORDER BY key_part2;
6 order by 和 group by 字段列不一致,group by 本身会进行排序操作
SELECT FROM t1 WHERE key_part1= 1 ORDER BY key_part2 group by key_part4;
7 索引本身是无序存储的,比如 hash 索引,不能利用索引的有序性
8 order by 字段只被索引了前缀 ,key idx_col(col(10)) ,目前遇到的比较熟
select * from t1 order by col ;
官方给出的在使用 order by 时可以利用索引有序性的要求是:
即使 order by 的列不能精确地匹配到(组合)索引列,也能使用索引,只要 where 条件中未使用的索引部分和额外的 order by 列为常数即可。
比较严谨的说法应该是,对于 where 条件的查询使用索引最左前缀进行等值匹配,其余列进行 order by
有序性
https://blog.csdn.net/u013705066/article/details/82257099
【推荐】如果有 order by 的场景,请注意利用索引的有序性。order by 最后的字段是组合索引的一部分,并且放在索引组合顺序的最后,避免出现 file_sort 的情况,影响查询性能。正例:where a=? and b=? order by c; 索引:a_b_c反例:索引中有范围查找,那么索引有序性无法利用,如:WHERE a>10 ORDER BY b; 索引a_b无法排序。
解释 order by 的排序原理
1.利用索引的有序性获取有序数据
2.利用内存/磁盘文件排序获取结果
- 双路排序:是首先根据相应的条件取出相应的排序字段和可以直接定位行数据的行指针信息,然后在sort buffer 中进行排序。
- 单路排序:是一次性取出满足条件行的所有字段,然后在sort buffer中进行排序。
组合索引的有序性和最左前缀原理
【强制】理解组合索引最左前缀原则,避免重复建设索引,如果建立了(a,b,c),相当于建立了(a), (a,b), (a,b,c)
假设有索引(A,B)mysql创建组合索引的规则是首先会对复合索引的最左边的,也就是第一个A字段的数据进行排序,在第一个字段的排序基础上,然后再对后面第二个的B字段进行排序。其实就相当于实现了类似 order by A B这样一种排序规则。第一个A字段是绝对有序的,而第二字段就是无序的了。所以通常情况下,直接使用第二个B字段进行条件判断是用不到索引的那么什么时候才能用到呢?当然是B字段的索引数据也是有序的情况下才能使用。什么时候才是有序的呢?只有在A字段是等值匹配的情况下,B才是有序的。
组合索引查询场景
有 Index (A,B,C) ——组合索引多字段是有序的,并且是个完整的BTree 索引。
下面条件可以用上该组合索引查询:
A>5
A=5 AND B>6
A=5 AND B=6 AND C=7
A=5 AND B IN (2,3) AND C>5
下面条件将不能用上组合索引查询:
B>5 ——查询条件不包含组合索引首列字段
B=6 AND C=7 ——查询条件不包含组合索引首列字段
下面条件将能用上部分组合索引查询:
A>5 AND B=2 ——当范围查询使用第一列,查询条件仅仅能使用第一列
A=5 AND B>6 AND C=2 ——范围查询使用第二列,查询条件仅仅能使用前二列
组合索引排序场景
有组合索引 Index(A,B)。
下面条件可以用上组合索引排序:
ORDER BY A——首列排序
A=5 ORDER BY B——第一列过滤后第二列排序
ORDER BY A DESC, B DESC——注意,此时两列以相同顺序排序
A>5 ORDER BY A——数据检索和排序都在第一列
下面条件不能用上组合索引排序:
ORDER BY B ——排序在索引的第二列
A>5 ORDER BY B ——范围查询在第一列,排序在第二列
A IN(1,2) ORDER BY B ——理由同上
ORDER BY A ASC, B DESC ——注意,此时两列以不同顺序排序
建议
索引常用技巧
- https://dev.mysql.com/doc/refman/5.6/en/group-by-optimization.html
- http://dev.mysql.com/doc/refman/5.6/en/order-by-optimization.html
- https://dev.mysql.com/doc/refman/5.6/en/mysql-indexes.html
- https://www.percona.com/files/presentations/percona-live/london-2011/PLUK2011-b-tree-indexes-and-innodb.pdf
- Composite Indexes 可以很大幅度提升 QUERY 性能. 一定要使用 Index Selectivity 高的索引
- (专业术语: 不重复的索引的度量(也叫基数Cardinality) + Index Selectivity )
- 必要时,请使用 FORCE INDEX

若有收获,就点个赞吧
0 人点赞
