Ref: https://pdai.tech/md/db/nosql-redis/db-redis-data-type-stream.html
为什么会设计 Stream
Redis5.0 中还增加了一个数据结构 Stream,从字面上看是流类型,但其实从功能上看,应该是 Redis 对消息队列(MQ,Message Queue)的完善实现。
用过 Redis 做消息队列的都了解,基于 Reids 的消息队列实现有很多种,例如:
- PUB/SUB,订阅 / 发布模式
- 但是发布订阅模式是无法持久化的,如果出现网络断开、Redis 宕机等,消息就会被丢弃;
- 基于 List LPUSH+BRPOP 或者 基于 Sorted-Set 的实现
- 支持了持久化,但是不支持多播,分组消费等
为什么上面的结构无法满足广泛的 MQ 场景? 这里便引出一个核心的问题:如果我们期望设计一种数据结构来实现消息队列,最重要的就是要理解设计一个消息队列需要考虑什么?初步的我们很容易想到
- 消息的生产
- 消息的消费
- 单播和多播(多对多)
- 阻塞和非阻塞读取
- 消息有序性
- 消息的持久化
其它还要考虑啥嗯?借助美团技术团队的一篇文章,消息队列设计精要(opens new window) 中的图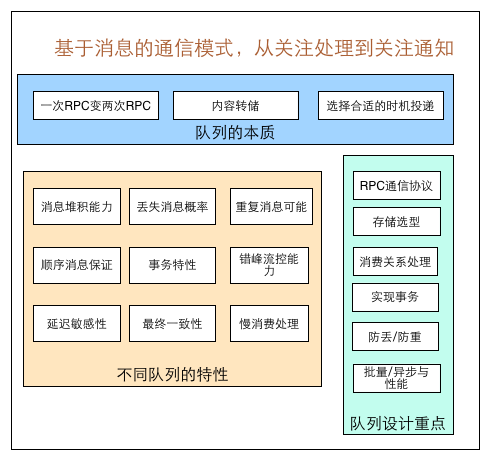
我们不妨看看 Redis 考虑了哪些设计?
- 消息 ID 的序列化生成
- 消息遍历
- 消息的阻塞和非阻塞读取
- 消息的分组消费
- 未完成消息的处理
- 消息队列监控
- …
这也是我们需要理解 Stream 的点,但是结合上面的图,我们也应该理解 Redis Stream 也是一种超轻量 MQ 并没有完全实现消息队列所有设计要点,这决定着它适用的场景。
¶ Stream 详解
经过梳理总结,我认为从以下几个大的方面去理解 Stream 是比较合适的,总结如下:@pdai
- Stream 的结构设计
- 生产和消费
- 基本的增删查改
- 单一消费者的消费
- 消费组的消费
-
¶ Stream 的结构
每个 Stream 都有唯一的名称,它就是 Redis 的 key,在我们首次使用 xadd 指令追加消息时自动创建。
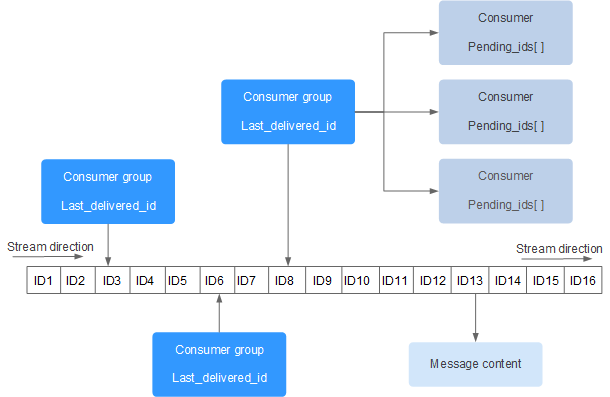
上图解析: Consumer Group :消费组,使用 XGROUP CREATE 命令创建,一个消费组有多个消费者 (Consumer), 这些消费者之间是竞争关系。
- last_delivered_id :游标,每个消费组会有个游标 last_delivered_id,任意一个消费者读取了消息都会使游标 last_delivered_id 往前移动。
- pending_ids :消费者 (Consumer) 的状态变量,作用是维护消费者的未确认的 id。 pending_ids 记录了当前已经被客户端读取的消息,但是还没有 ack (Acknowledge character:确认字符)。如果客户端没有 ack,这个变量里面的消息 ID 会越来越多,一旦某个消息被 ack,它就开始减少。这个 pending_ids 变量在 Redis 官方被称之为 PEL,也就是 Pending Entries List,这是一个很核心的数据结构,它用来确保客户端至少消费了消息一次,而不会在网络传输的中途丢失了没处理。
此外我们还需要理解两点:
- 消息ID: 消息 ID 的形式是 timestampInMillis-sequence,例如 1527846880572-5,它表示当前的消息在毫米时间戳 1527846880572 时产生,并且是该毫秒内产生的第 5 条消息。消息 ID 可以由服务器自动生成,也可以由客户端自己指定,但是形式必须是整数 - 整数,而且必须是后面加入的消息的 ID 要大于前面的消息 ID。
消息内容: 消息内容就是键值对,形如 hash 结构的键值对,这没什么特别之处。
¶ 独立消费
我们可以在不定义消费组的情况下进行 Stream 消息的独立消费,当 Stream 没有新消息时,甚至可以阻塞等待。Redis 设计了一个单独的消费指令 xread,可以将 Stream 当成普通的消息队列 (list) 来使用。使用 xread 时,我们可以完全忽略消费组 (Consumer Group) 的存在,就好比 Stream 就是一个普通的列表 (list)。
消费组消费
消费组消费图
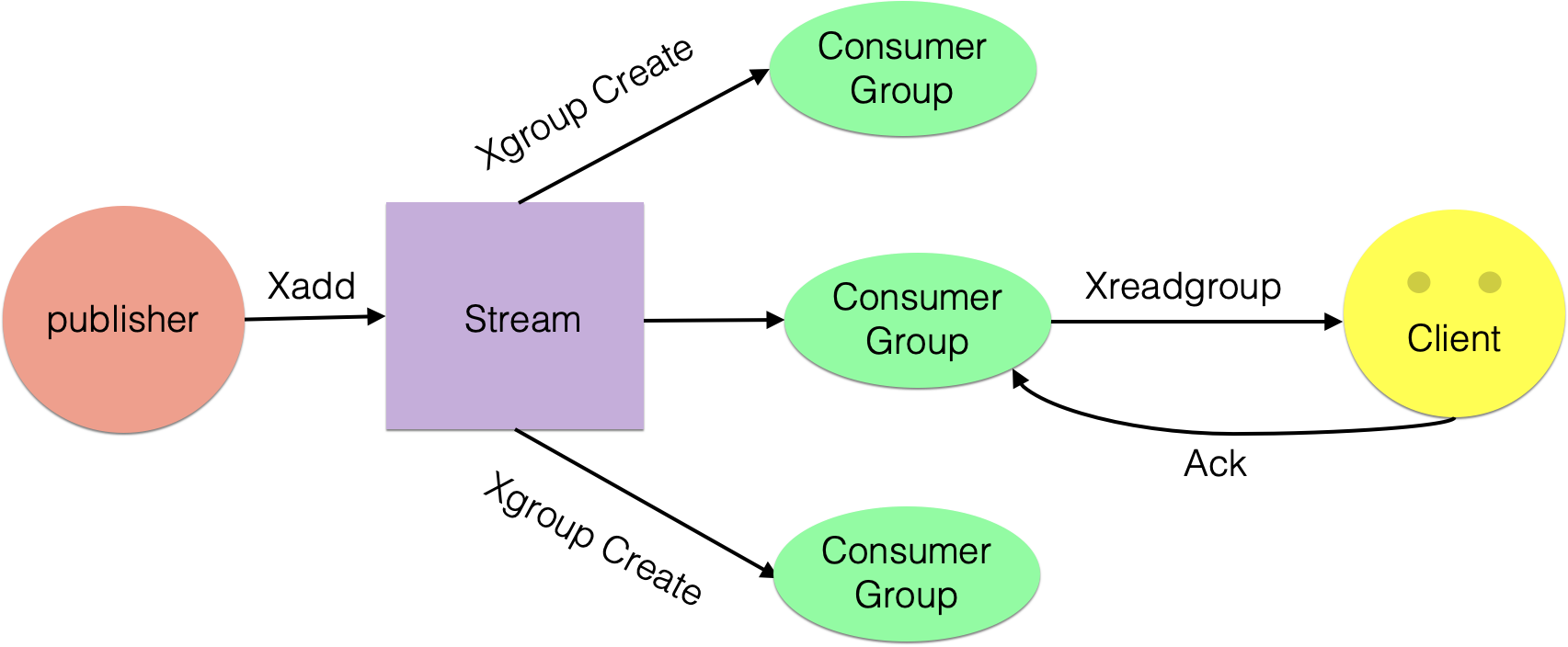
著作权归https://pdai.tech所有。 链接:https://pdai.tech/md/db/nosql-redis/db-redis-data-type-stream.html
更深入理解
我们结合 MQ 中常见问题,看 Redis 是如何解决的,来进一步理解 Redis。
¶ Stream 用在什么样场景
可用作时通信,大数据分析,异地数据备份等
客户端可以平滑扩展,提高处理能力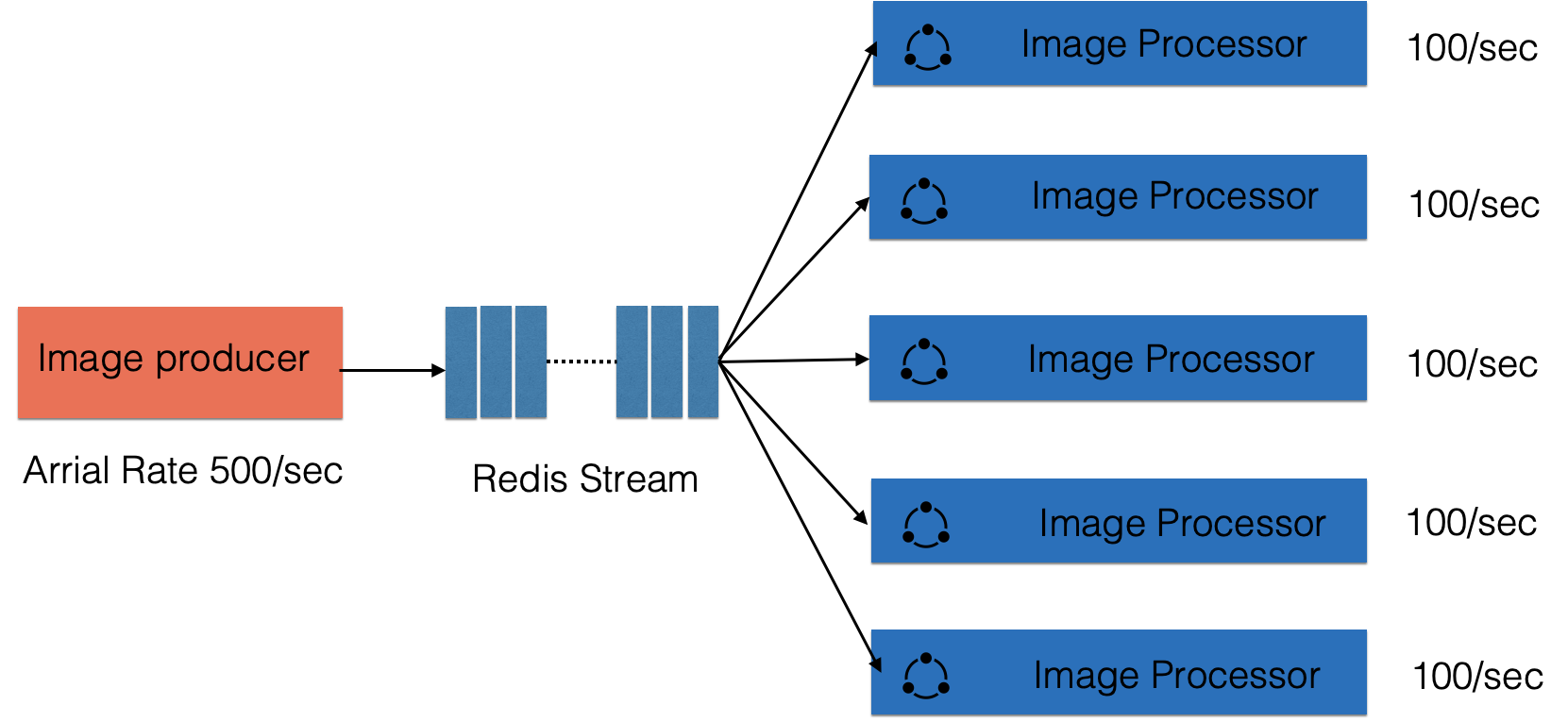
¶ 消息 ID 的设计是否考虑了时间回拨的问题?
在 分布式算法 - ID 算法设计中,一个常见的问题就是时间回拨问题,那么 Redis 的消息 ID 设计中是否考虑到这个问题呢?
XADD 生成的 1553439850328-0,就是 Redis 生成的消息 ID,由两部分组成: 时间戳 - 序号。时间戳是毫秒级单位,是生成消息的 Redis 服务器时间,它是个 64 位整型(int64)。序号是在这个毫秒时间点内的消息序号,它也是个 64 位整型。
可以通过 multi 批处理,来验证序号的递增:
127.0.0.1:6379> MULTIOK127.0.0.1:6379> XADD memberMessage * msg oneQUEUED127.0.0.1:6379> XADD memberMessage * msg twoQUEUED127.0.0.1:6379> XADD memberMessage * msg threeQUEUED127.0.0.1:6379> XADD memberMessage * msg fourQUEUED127.0.0.1:6379> XADD memberMessage * msg fiveQUEUED127.0.0.1:6379> EXEC1) "1553441006884-0"2) "1553441006884-1"3) "1553441006884-2"4) "1553441006884-3"5) "1553441006884-4"
由于一个 redis 命令的执行很快,所以可以看到在同一时间戳内,是通过序号递增来表示消息的。
为了保证消息是有序的,因此 Redis 生成的 ID 是单调递增有序的。
由于 ID 中包含时间戳部分,为了避免服务器时间错误而带来的问题(例如服务器时间延后了),Redis 的每个 Stream 类型数据都维护一个 latest_generated_id 属性,用于记录最后一个消息的 ID。若发现当前时间戳退后(小于 latest_generated_id 所记录的),则采用时间戳不变而序号递增的方案来作为新消息 ID(这也是序号为什么使用 int64 的原因,保证有足够多的的序号),从而保证 ID 的单调递增性质。
强烈建议使用 Redis 的方案生成消息 ID,因为这种时间戳 + 序号的单调递增的 ID 方案,几乎可以满足你全部的需求。但同时,记住 ID 是支持自定义的,别忘了!
¶ 消费者崩溃带来的会不会消息丢失问题?
为了解决组内消息读取但处理期间消费者崩溃带来的消息丢失问题,STREAM 设计了 Pending 列表,用于记录读取但并未处理完毕的消息。命令 XPENDIING 用来获消费组或消费内消费者的未处理完毕的消息。

若有收获,就点个赞吧
0 人点赞
