Ref: https://pdai.tech/md/db/nosql-redis/db-redis-x-redis-ds.html
跳表 - ZSkipList
跳跃表结构在 Redis 中的运用场景只有一个,那就是作为有序列表 (Zset) 的使用。跳跃表的性能可以保证在查找,删除,添加等操作的时候在对数期望时间内完成,这个性能是可以和平衡树来相比较的,而且在实现方面比平衡树要优雅,这就是跳跃表的长处。跳跃表的缺点就是需要的存储空间比较大,属于利用空间来换取时间的数据结构。
¶ 什么是跳跃表
跳跃表要解决什么问题呢?如果你一上来就去看它的实现,你很难理解设计的本质,所以先要看它的设计要解决什么问题。
对于于一个单链表来讲,即便链表中存储的数据是有序的,如果我们要想在其中查找某个数据,也只能从头到尾遍历链表。这样查找效率就会很低,时间复杂度会很高,是 O (n)。比如查找 12,需要 7 次查找
如果我们增加如下两级索引,那么它搜索次数就变成了 3 次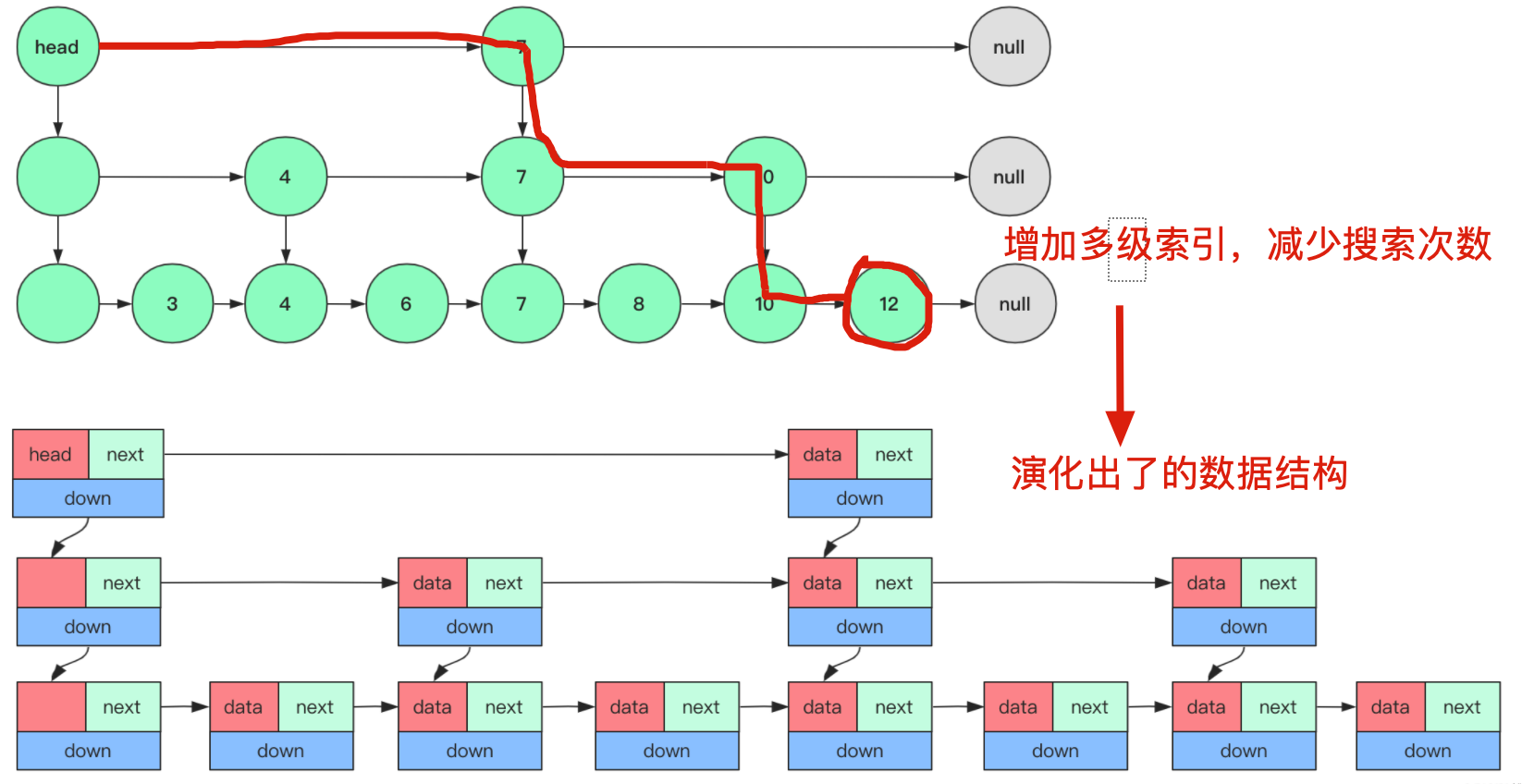
¶ Redis 跳跃表的设计
redis 跳跃表并没有在单独的类(比如 skplist.c) 中定义,而是其定义在 server.h 中,如下:
/* ZSETs use a specialized version of Skiplists */typedef struct zskiplistNode {sds ele;double score;struct zskiplistNode *backward;struct zskiplistLevel {struct zskiplistNode *forward;unsigned int span;} level[];} zskiplistNode;typedef struct zskiplist {struct zskiplistNode *header, *tail;unsigned long length;int level;} zskiplist;
著作权归https://pdai.tech所有。 链接:https://pdai.tech/md/db/nosql-redis/db-redis-x-redis-ds.html
其内存布局如下图: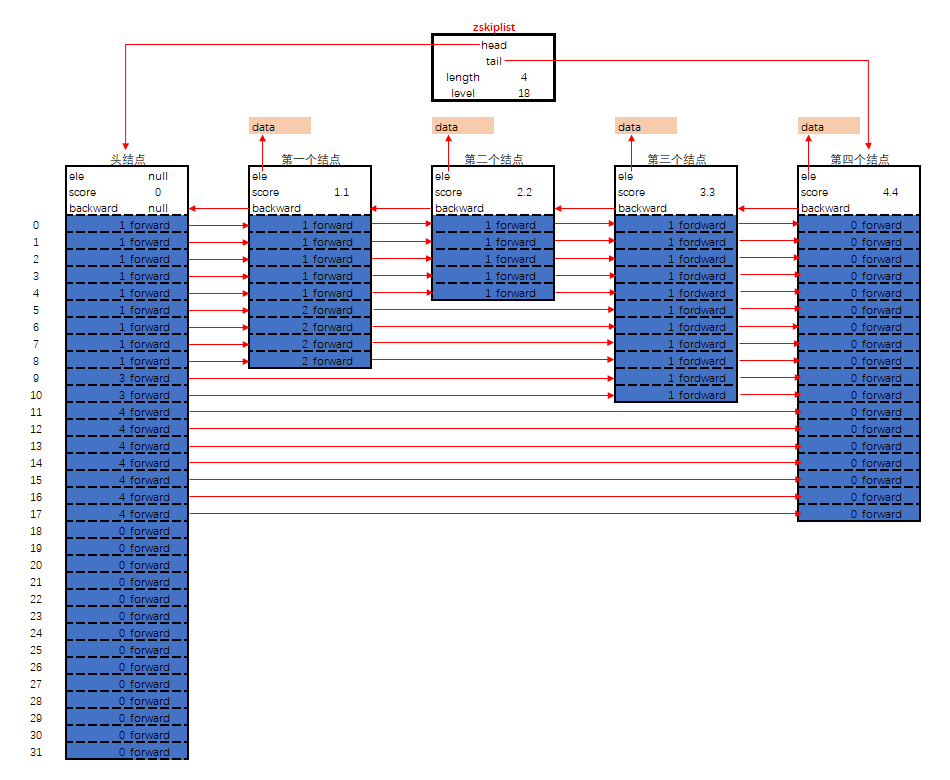
zskiplist 的核心设计要点
- 头节点不持有任何数据,且其 level [] 的长度为 32
每个结点
- ele 字段,持有数据,是 sds 类型
- score 字段,其标示着结点的得分,结点之间凭借得分来判断先后顺序,跳跃表中的结点按结点的得分升序排列.
- backward 指针,这是原版跳跃表中所没有的。该指针指向结点的前一个紧邻结点.
- level 字段,用以记录所有结点 (除过头节点外);每个结点中最多持有 32 个 zskiplistLevel 结构。实际数量在结点创建时,按幂次定律随机生成 (不超过 32). 每个 zskiplistLevel 中有两个字段
- forward 字段指向比自己得分高的某个结点 (不一定是紧邻的), 并且,若当前 zskiplistLevel 实例在 level [] 中的索引为 X, 则其 forward 字段指向的结点,其 level [] 字段的容量至少是 X+1. 这也是上图中,为什么 forward 指针总是画的水平的原因.
- span 字段代表 forward 字段指向的结点,距离当前结点的距离。紧邻的两个结点之间的距离定义为 1.
¶ 为什么不用平衡树或者哈希表
为什么不是平衡树,先看下作者的回答
https://news.ycombinator.com/item?id=1171423
其内存布局如下图: zskiplist 的核心设计要点 头节点不持有任何数据,且其 level [] 的长度为 32 每个结点 ele 字段,持有数据,是 sds 类型 score 字段,其标示着结点的得分,结点之间凭借得分来判断先后顺序,跳跃表中的结点按结点的得分升序排列. backward 指针,这是原版跳跃表中所没有的。该指针指向结点的前一个紧邻结点. level 字段,用以记录所有结点 (除过头节点外);每个结点中最多持有 32 个 zskiplistLevel 结构。实际数量在结点创建时,按幂次定律随机生成 (不超过 32). 每个 zskiplistLevel 中有两个字段forward 字段指向比自己得分高的某个结点 (不一定是紧邻的), 并且,若当前 zskiplistLevel 实例在 level [] 中的索引为 X, 则其 forward 字段指向的结点,其 level [] 字段的容量至少是 X+1. 这也是上图中,为什么 forward 指针总是画的水平的原因. span 字段代表 forward 字段指向的结点,距离当前结点的距离。紧邻的两个结点之间的距离定义为 1. ¶ 为什么不用平衡树或者哈希表 为什么不是平衡树,先看下作者的回答 https://news.ycombinator.com/item?id=1171423
- skiplist 与平衡树、哈希表的比较
来源于:https://www.jianshu.com/p/8ac45fd01548
skiplist 和各种平衡树(如 AVL、红黑树等)的元素是有序排列的,而哈希表不是有序的。因此,在哈希表上只能做单个 key 的查找,不适宜做范围查找。所谓范围查找,指的是查找那些大小在指定的两个值之间的所有节点。
在做范围查找的时候,平衡树比 skiplist 操作要复杂。在平衡树上,我们找到指定范围的小值之后,还需要以中序遍历的顺序继续寻找其它不超过大值的节点。如果不对平衡树进行一定的改造,这里的中序遍历并不容易实现。而在 skiplist 上进行范围查找就非常简单,只需要在找到小值之后,对第 1 层链表进行若干步的遍历就可以实现。
平衡树的插入和删除操作可能引发子树的调整,逻辑复杂,而 skiplist 的插入和删除只需要修改相邻节点的指针,操作简单又快速。
从内存占用上来说,skiplist 比平衡树更灵活一些。一般来说,平衡树每个节点包含 2 个指针(分别指向左右子树),而 skiplist 每个节点包含的指针数目平均为 1/(1-p),具体取决于参数 p 的大小。如果像 Redis 里的实现一样,取 p=1/4,那么平均每个节点包含 1.33 个指针,比平衡树更有优势。
查找单个 key,skiplist 和平衡树的时间复杂度都为 O (log n),大体相当;而哈希表在保持较低的哈希值冲突概率的前提下,查找时间复杂度接近 O (1),性能更高一些。所以我们平常使用的各种 Map 或 dictionary 结构,大都是基于哈希表实现的。
从算法实现难度上来比较,skiplist 比平衡树要简单得多。

若有收获,就点个赞吧
0 人点赞
