索引分片
水平扩展
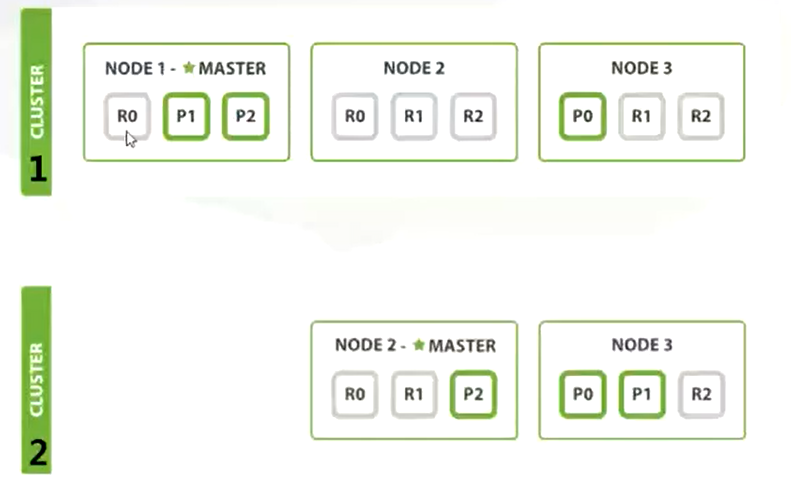
主分片(primary shards)+副本分片(replicas shards),每个节点上每个分片最多一个。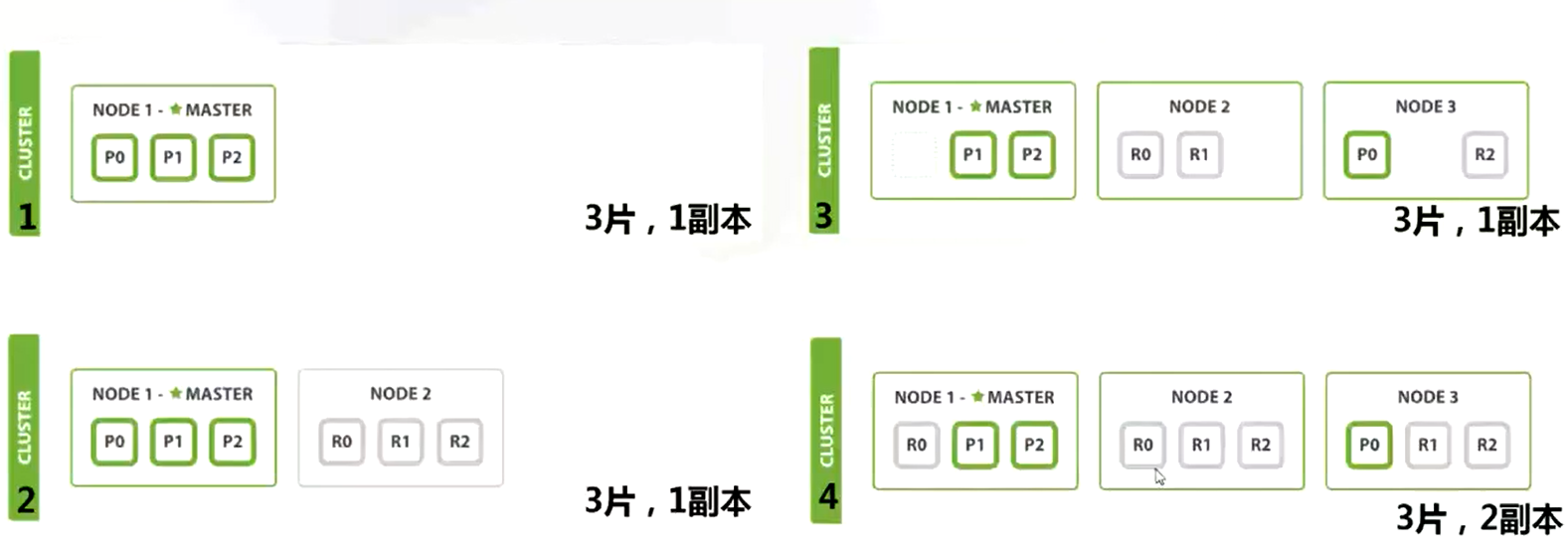
应对故障
文档路由规则

- 路由公式:
shard = hash(routing) % number_of_primary_shards - 默认 routing 值是 _id,也可手动指定
-
索引写入过程
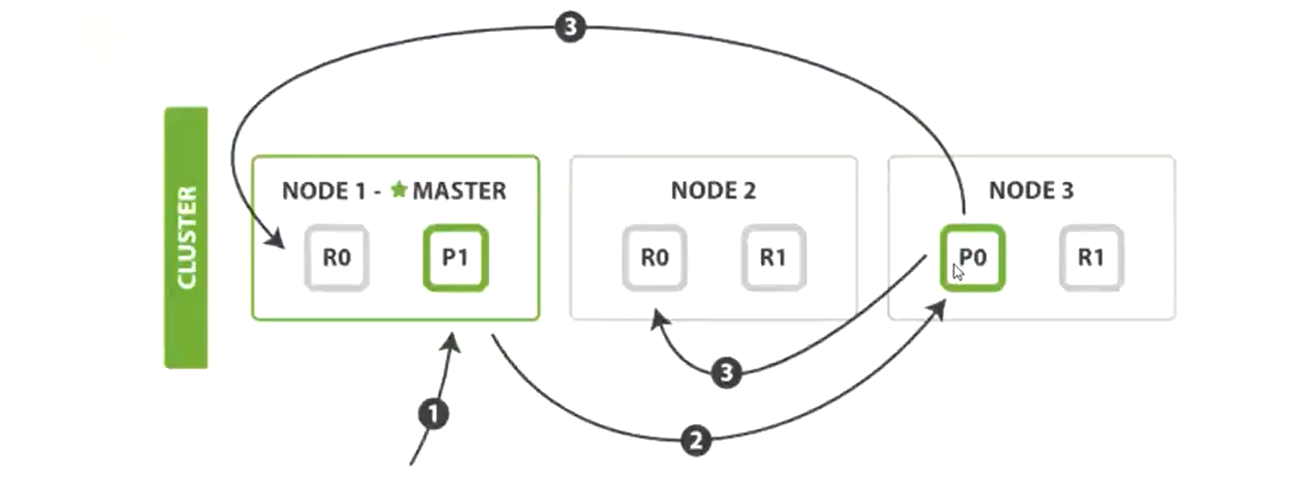
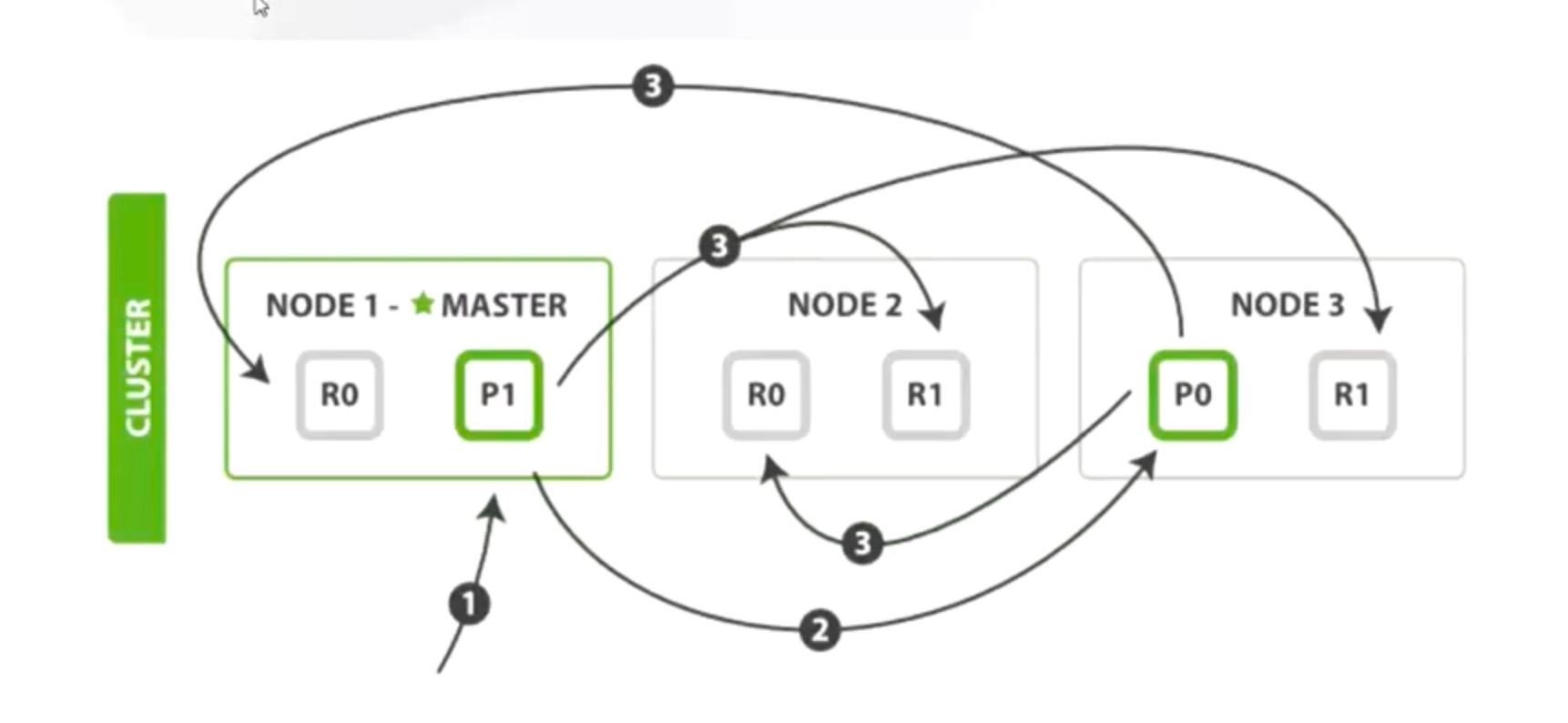
写入成功判断:写入的节点数 >= (主分片数 + 副本分片 / 2 向下取整)。多文档 bulk
A BulkRequest can be used to execute multiple index, update and/or delete operations using a single request.查询过程
查询过程
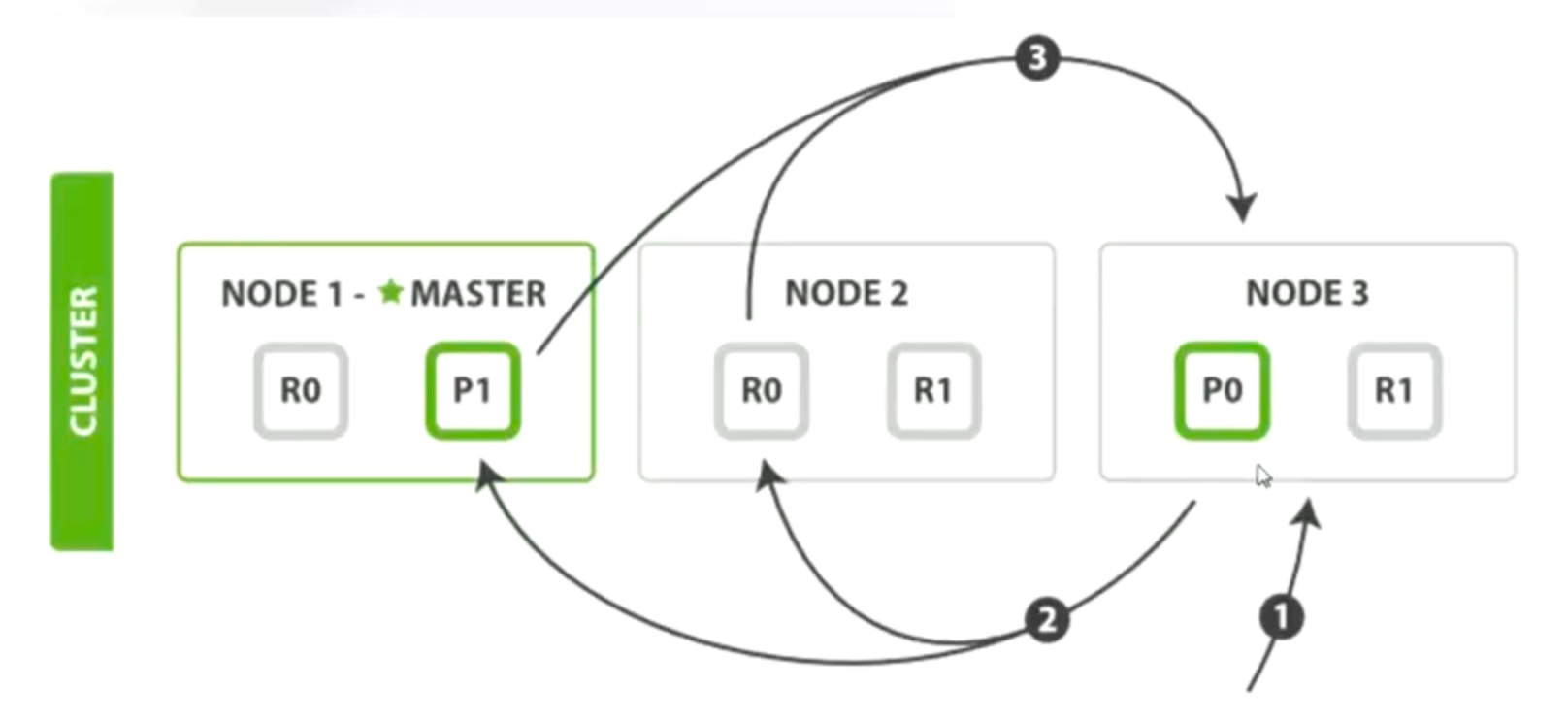
查询 10W 到 11W 之间的 1W 条数据的过程:请求发给协调节点 Node3,Node3 将请求发给 Node1 和 Node2,Node1 和 Node2 分别生成一个 11W 容量的队列并各自排序,取回共计 22W 数据返给 Node3,Node3 做总排序,最终取得 1W 个 _id。
取回过程
1W 条数据的取回过程:协调节点 Node3 分别让 Node1 和 Node2 根据 _id 做 MGET 操作获取多文档,Node3 再对文档包装整理返回给客户端。
不适合做深分页,使用 scroll 游标方法查询。索引原理
动态更新索引,不修改已经生成好的倒排索引,而是生成一个新的段(segment)
- 每一个 segment 都是一个倒排索引
- ES 另外使用一个 commit 文件,记录索引内所有的 segment
- 生成 segment 的数据是内存中的 buffer
一个 Lucene 索引包含一个提交点和三个 segment,如下是在内存缓冲区中包含了新文档的 Lucene 索引,在一次缓冲区被提交到磁盘后,一个新的 segment 被添加到提交点,缓存区被清空。此时文档可以被搜索、被索引。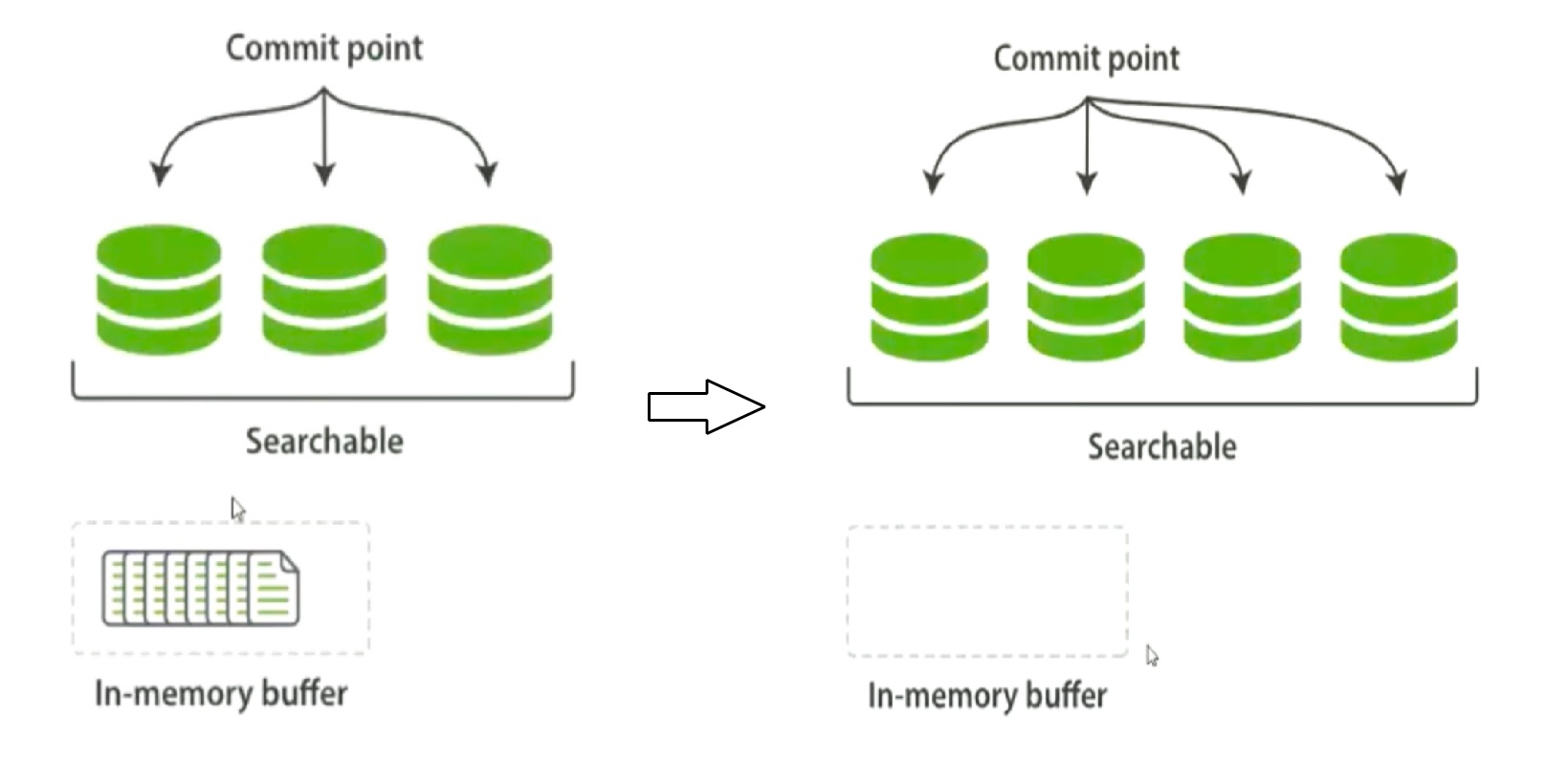
准实时索引原理
当 Lucene 索引的内存缓冲区中包含了新文档,缓冲区内容已被写入一个可被检索的 segment,但还没进行提交。即内存中生成一个倒排索引 segment,默认每秒钟将缓冲区文档写入内存 segment,可被检索(Refresh)。
- segment 刷新到文件系统缓存
refresh_interval 默认 1s 间隔,可以手工设置:日志数据可以设置较长间隔(比如 10s)
PUT /my_index/_settings{"index": {"refresh_interval": "30s"}}
主动调用 /refresh 接口刷新到缓存
_POST /_refresh POST /blogs/_refresh可以使用 “refresh_interval”:”-1” 禁用刷新:初始化数据时,灌入上亿数据,可以先禁用刷新,写完之后统一刷新
事务日志
新的文档被添加到内存缓冲区并且被追加到了事务日志,刷新(refresh)完成后(未涉及 Linux fsink 磁盘操作),缓存被清空但事务日志不会。事务日志不断积累,在刷新(flush)之后,segment 被全量提交,并且事务日志被清空。
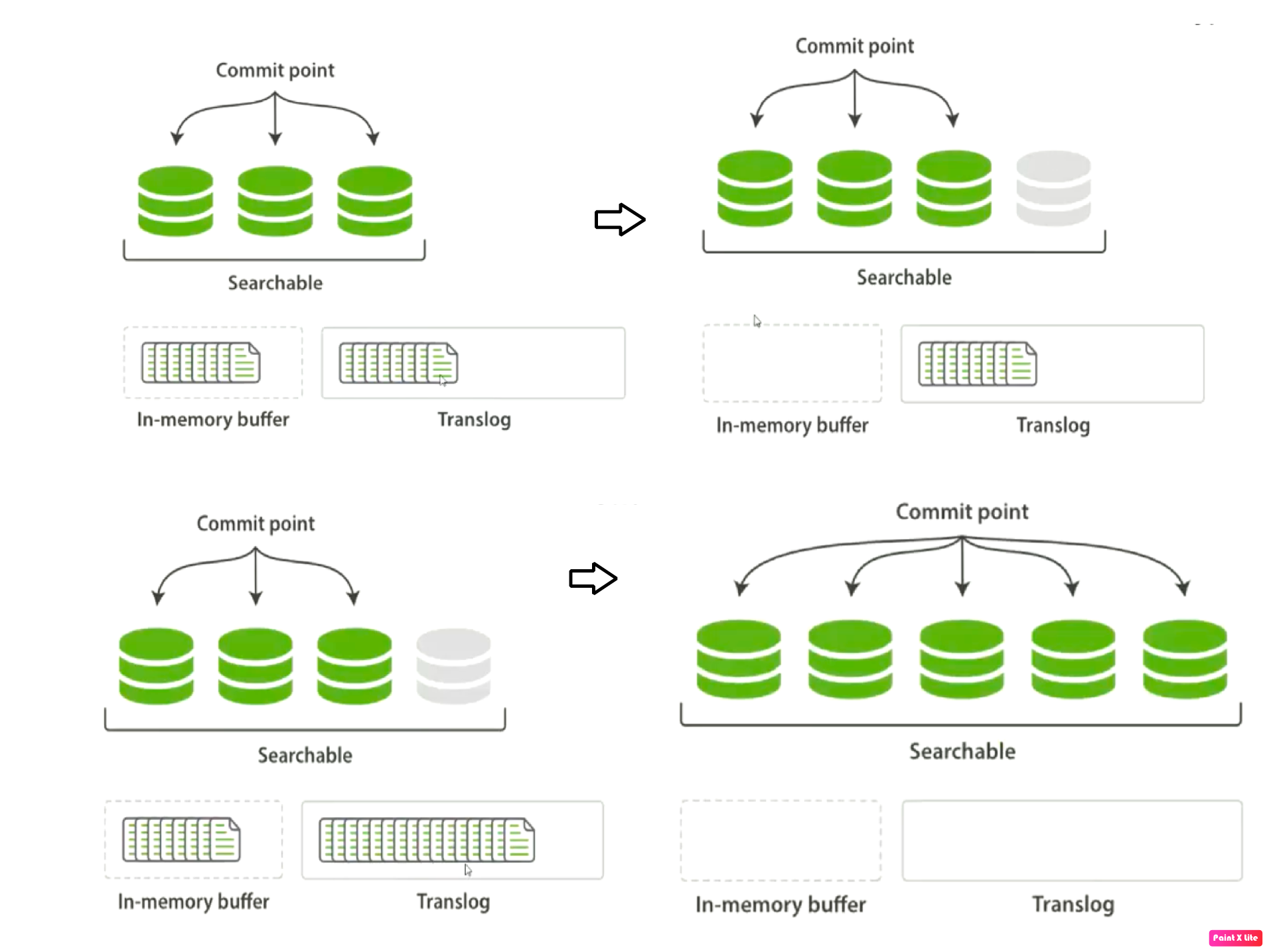
Lucene 的 commit 操作非常昂贵,segment 从文件系统缓存刷新到磁盘,更新 commit
- translog 记录发生在索引上的各种操作
- 每个不同的 shard 都有自己的事务日志
- 默认 5秒 进行一次进行一次 fsync(index,tanslog,sync_interval)
- 默认 512Mb 进行一次 Flush(index, translog, flush_threshold_size)
- 主动调用 /_flush 接口
异步 translog
PUT /my_index/_settings{"index.translog.durability": "async","index.translog.sync_interval": "5s"}
段合并过程
过多 segment 影响数据读取的性能,占用文件句柄、内存资源。专门的 merge 线程池负责。
手工调用接口:新版本 _forcemerge 接口、老版本 _optimize 接口,POST /my_index/ _forcemerge?max_num_segments=1。
如下是两个已提交的段和一个未提交的段正在合并成一个大的段,合并后的段被删除。若合并过程中删除小段文档,文档中 DL 字段记录已删除,不在小段中删除,磁盘可用空间不会增加,合并到大段中时文档删除。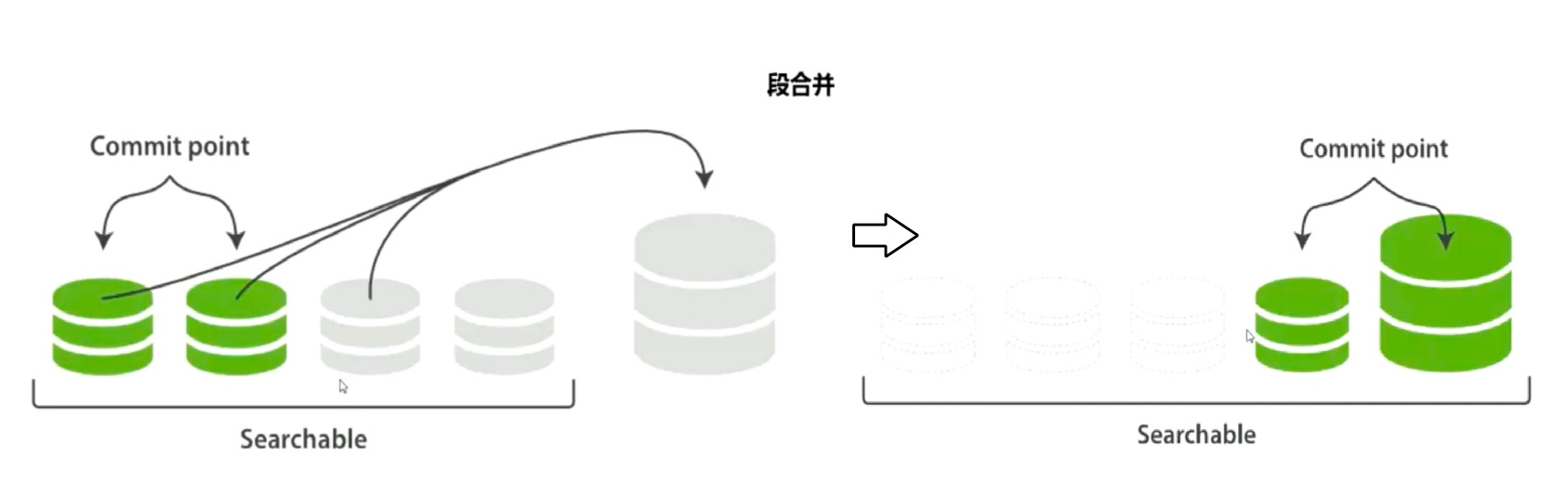
段合并配置
合并线程的数量:
index.merge.scheduler.max_thread_count
- 默认值:Math.min(3, Runtime.getRuntime().availableProcessor()/2)
合并线程的限速配置:

若有收获,就点个赞吧
0 人点赞
