Ref: liangliangLee
普通 IO 和 NIO
- 普通 IO 是基于字节的单向阻塞式传输;
- NIO 引入 FileChannel 全双工通道和 ByteBuffer 数据容器,ByteBuffer 可以精准的控制写入磁盘的数据大小。
如下图所示 FileChannel#write () 方法会将 ByteBuffer 里面的数据写到 PageCache 中,然后操作系统会定期将 PageCache 中的数据进行刷盘,如果想要立马通知操作系统进行刷盘可以调用 FileChannel#force () 方法。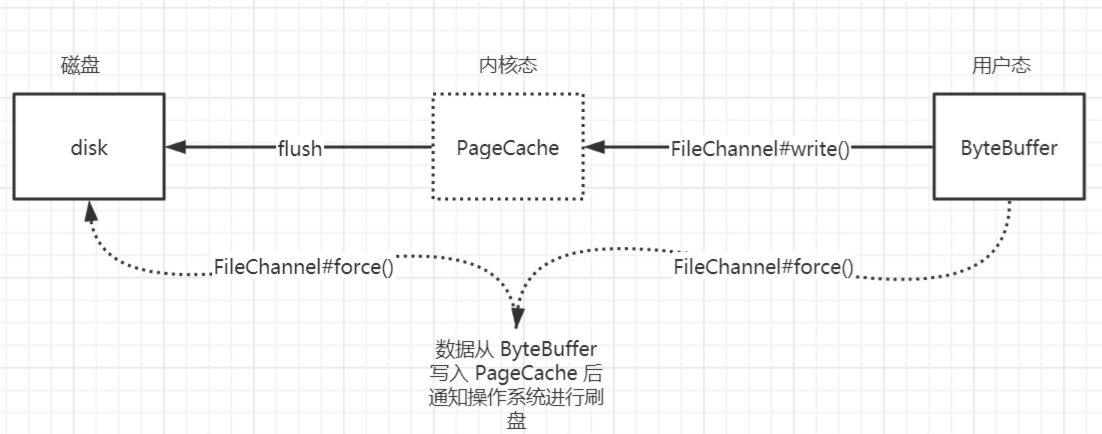
不管是普通 IO 还是没有使用 MMAP 的 NIO 都会有多次数据拷贝的问题。
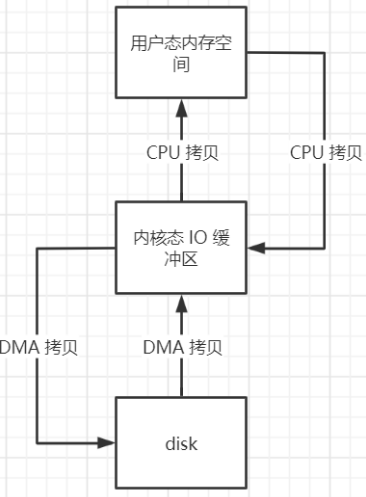
- 读磁盘的过程:先把磁盘里面的数据 DMA 拷贝到内核态 IO 缓冲区,然后再把内核态的数据 CPU 拷贝到用户态内存空间;
- 写磁盘的过程:把用户态内存空间的数据 CPU 拷贝到内存态 IO 缓冲区,然后再把内核态的数据 DMA 拷贝到磁盘;
- 不管是读还是写都需要两次数据拷贝,如果采用 MMAP 技术就可以把磁盘里面的文件映射到用户态空间的虚拟内存中,省去了内核态到用户态的 CPU 拷贝。
内存映射 MMAP(零拷贝技术)
NIO 可以采用 MappedByteBuffer 数据容器进行读写数据,而 MappedByteBuffer#map () 底层采用了 MMAP 技术进行了文件映射。
MappedByteBuffer mappedByteBuffer = fileChannel.map(FileChannel.MapMode.READ_WRITE, position, fileSize) ize);
上文提到了 MMAP 技术就是进行文件映射和内存映射,把磁盘里面的文件映射到用户态的虚拟内存,还有将 PageCache 映射到用户态的虚拟内存,从而减少内核态到用户态的 CPU 拷贝。
MappedByteBuffer#write () 方法会将数据直接写入到 PageCache 中,然后操作系统会异步刷盘将 PageCache 中的数据写入到磁盘。
从磁盘读取数据的时候,首先会从 PageCache 中查看是否有数据,如果有的话就直接从 PageCache 加载数据,如果没有的话就去磁盘加载数据到 PageCache 中,PageCache 技术还会将要加载的数据的附近的其他数据块也一并加载进 PageCache,下文继续分析 PageCache 技术。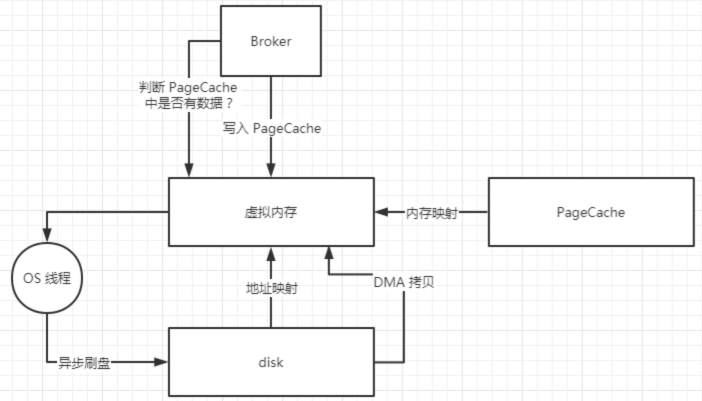
MMAP 虽然可以提高磁盘读写的性能,但是仍然有诸多缺陷和限制,比如:
- MMAP 进行文件映射的时候对文件大小有限制,在 1.5GB~2GB 之间,所以 RocketMQ 设计 CommitLog 单个文件 1GB,ConsumeQueue 单个文件 5.7MB;
当不再需要使用 MappedByteBuffer 的时候,需要手动释放占用的虚拟内存。
PageCache 技术
为了优化磁盘中数据文件的读写性能,PageCache 技术对数据文件进行了缓存。“对磁盘中数据文件的顺序读写性能接近于对内存的读写性能”,其主要原因就是 PageCache 对磁盘中数据文件的读写进行了优化。
PageCache 对数据文件的读优化:由于读数据文件的时候会先从 PageCache 加载数据,如果 PageCache 没有数据的话,会从磁盘的数据文件中加载数据并且顺序把相邻的数据文件页面预加载到 PageCache 中,这样子如果之后读取的数据文件在 PageCache 中能找到的话就省去了去磁盘加载数据的操作相当于直接读内存。
- PageCache 对数据文件的写优化:往数据文件中写数据的时候同样先写到 PageCache 中,然后操作系统会定期刷盘把 PageCache 中的数据持久化到磁盘中。
那么 RocketMQ 具体是怎么使用 PageCache + Mmap 技术的呢?又做了哪些优化呢?
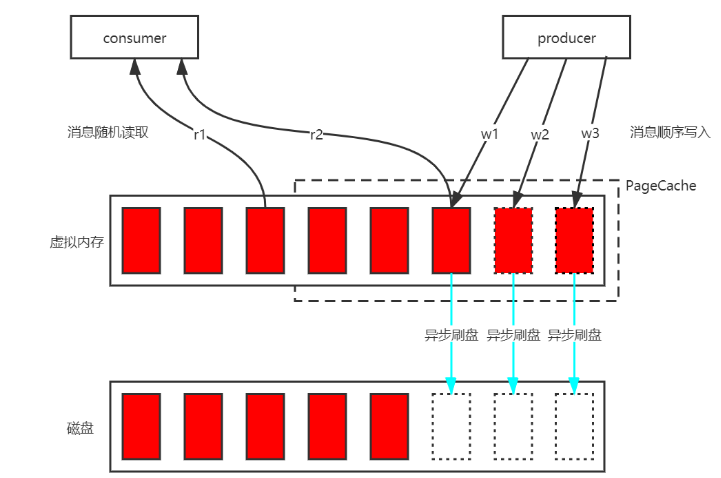
- 首先将磁盘中的 CommitLog 数据文件映射到虚拟内存中;
- 生成端将消息顺序写到 PageCache 中,然后操作系统定期进行异步刷盘,将 PageCache 中的数据批量持久化到磁盘;
- 消费端随机读取 CommitLog 数据文件,由于程序的局部性热点原理,未来将要加载的数据和正在使用的数据在存储空间上是邻近的,所以要加载的数据基本可以在 PageCache 中找到,避免了缺页中断而去磁盘中加载数据。
虽然 PageCache 技术优化了数据文件的读写性能,但是仍然有一些影响其性能的问题:
操作系统的脏页回写(当空闲内存不足的时候操作系统会将脏页刷到磁盘释放内存空间)、内存回收、内存 SWAP(当内存不足的时候把一部分磁盘空间虚拟成内存使用) 等都会造成消息读写的延迟。
为了解决消息读写的延迟问题,RocketMQ 还引入了其他优化方案,下文继续分析。
预分配 MappedFile(内存预分配)
为了解决 PageCache 技术带来的消息读写延迟问题,RocketMQ 进行了内存预分配处理。
当往 CommitLog 写入消息的时候,会先判断 MappedFileQueue 队列中是否有对应的 MappedFile,如果没有的话会封装一个 AllocateRequest 请求,参数有:文件路径、下下个文件路径、文件大小等,并把请求放到一个 AllocateRequestQueue 队列里面;
在 Broker 启动的时候会自动创建一个 AllocateMappedFileService 服务线程,该线程不停的运行并从 AllocateRequestQueue 队列消费请求,执行 MappedFile 映射文件的创建和下下个 MappedFile 的预分配逻辑,创建 MappedFile 映射文件的方式有两个:一个是在虚拟内存中通过 MapperByteBuffer 即 Mmap 创建一个 MappedFile 实例,另一个是在堆外内存中通过 DirectByteBuffer 创建一个 MappedFile 实例。创建完当前 MappedFile 实例后还会将下一个 MappedFile 实例创建好并且添加到 MappedFileQueue 队列里面,即预分配 MappedFile。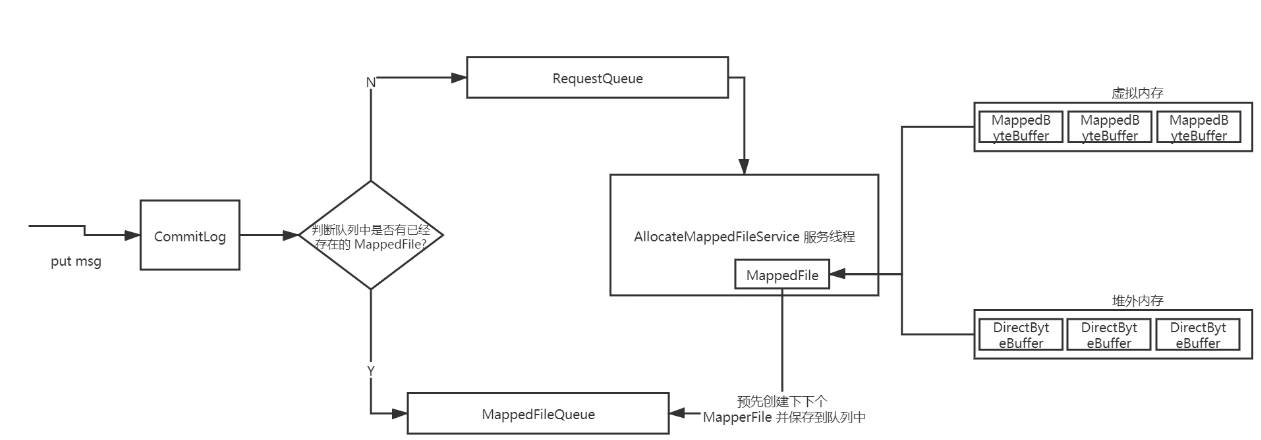
mlock 系统调用
当内存不足的时候可能发生内存 SWAP,读写消息的进程所使用的内存可能会被交换到 SWAP 空间,为了保证 RocketMQ 的吞吐量和读写消息低延迟,肯定希望尽可能使用物理内存,所以 RocketMQ 采用了 mlock 系统调用将读写消息的进程所使用的部分或者全部内存锁在了物理内存中,防止被交换到 SWAP 空间。
文件预热(内存预热)
mlock 系统调用未必会锁住读写消息进程所使用的物理内存,因为可能会有一些内存分页是写时复制的,所以 RocketMQ 在创建 MapperFile 的过程中,会将 Mmap 映射出的虚拟内存中随机写入一些值,防止内存被交换到 SWAP 空间。
由于 Mmap 技术只是创建了虚拟内存地址至物理内存地址的映射表,并没有将磁盘中的数据文件加载到内存中来,如果内存中没有找到数据就会发生缺页中断,而去磁盘读取数据,所以 RocketMQ 采用了 madvise 系统调用将数据文件尽可能多的加载到内存中达到内存预热的效果。

若有收获,就点个赞吧
0 人点赞
