
背景
在早期计算机中都是批处理的模型,每个任务顺序执行,但是计算机上运行的任务会有各种类型,有IO类型,也有CPU计算类型,如果依然采用批处理的模型,在执行IO操作时,CPU就无法继续使用,导致CPU的效率低下。因此作业之间的切换和调度成为了计算机的核心需求,多进程结构是操作系统的基本图谱。
对于操作系统,实现概念远比理解概念重要。多进程的操作系统从 IBSYS -> OS/360 -> MULTICS -> Unix -> Linux 经过一代代的发展,实际上就是在实现上的改进,因此学习操作系统还是,纸上得来终觉浅,绝知此事要躬行。
进程
cpu的运行模式是不断的从pc寄存器取指执行,但是用户程序指令中会有io指令,也会有计算指令,而io指令耗时比计算指令高很多,如果在执行io时,cpu一直等待io完成后再执行下一条,这样必然造成cpu的使用效率低下。
为了解决这个问题,结合生活中烧水的例子:”在把水壶放到炉子上之后,我们不需要一直等着水壶,我们可以去做别的事情,等到水壶烧开了,发出提醒的声音之后再切换回来使用热水。”
类比到计算机中,如果程序出现io阻塞了,可以切换到另一道程序继续执行,在一个CPU上交替的执行多个程序(并发),这样能够提高cpu的使用效率。
为了能够将运行的程序切换到另一个程序运行,直观来看只需要修改PC寄存器就可以了,但是实际上还有很多上下文信息需要切换,比如各个寄存器的信息。因此为了区分运行中的程序和静态程序,引入了进程的概念即运行中的程序,进程由资源和执行序列两部分组成。每个进程都有一个存放运行时信息的结构: PCB(process control block),会存放切换时需要保留的上下文信息。
线程
操作系统中为了将资源和指令执行序列区分开,引入了线程的概念,线程作为操作系统中的最小的调度单位。线程的模型是多个执行序列 + 一个地址空间。因此线程的切换不需要切换进程的内存映射表,这样保留了并发的特点,避免了进程切换的代价。
用户级线程
我们首先看一个在用户态代码中线程切换的实现。如果只在用户态实现线程,不进入核心态。就需要在用户态主动通过调用用户函数进行线程执行的切换。
在实现中每个线程都应该拥有自己的栈空间,如果多个线程共用一个栈,会导致函数调用在切换之后弹栈会出现跳转错误。每个线程通过tcb数据结构,保存当前运行的栈指针。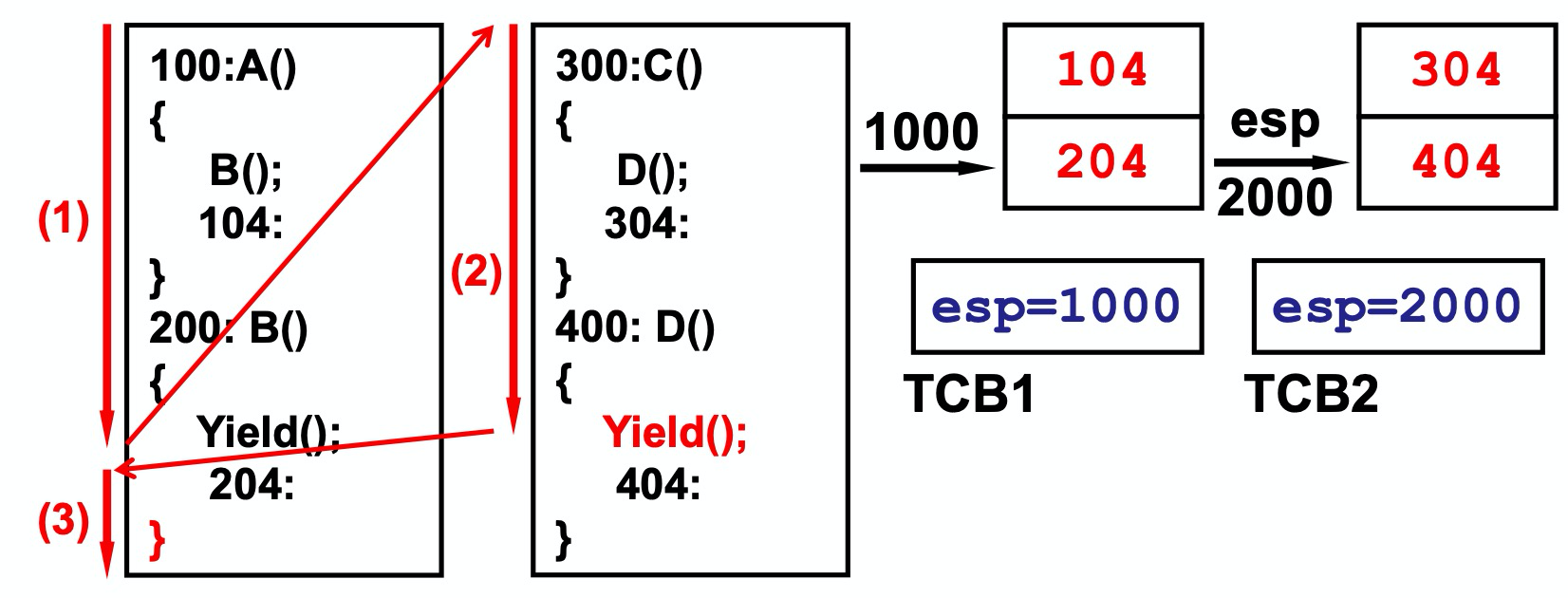
在切换时,只要进行栈指针的切换, 图中红色Yield的实现
void Yield(){TCB2.esp=esp;esp=TCB1.esp;}
这里可能会有疑问,这里仅仅只是切换了栈指针esp,怎么没有切换cs:ip呢?在切换完之后esp就指向了204处,而204就是线程1的在调用Yield时的IP指针。我们想下,当红色Yield执行到右括号时,当前的PC指针指向的是Yield函数后的ret指令,继续执行就是弹栈,将栈中的内容赋值给IP,那么就是将IP设置为 204 (注意此时栈指针已经指向了程序1的204处),这样就完成了IP的转化。所以不需要再Yield函数中手动进行jmp 204 了,这一步很精妙~。主要原因是因为已经将PC信息压入了栈中
在create用户级线程时,就是要构建相应的数据结构
void ThreadCreate(A){TCB *tcb=malloc(); // 创建tcb*stack=malloc(); // 申请栈*stack = A;//100tcb.esp=stack; // 赋值tcb中esp的初始地址}
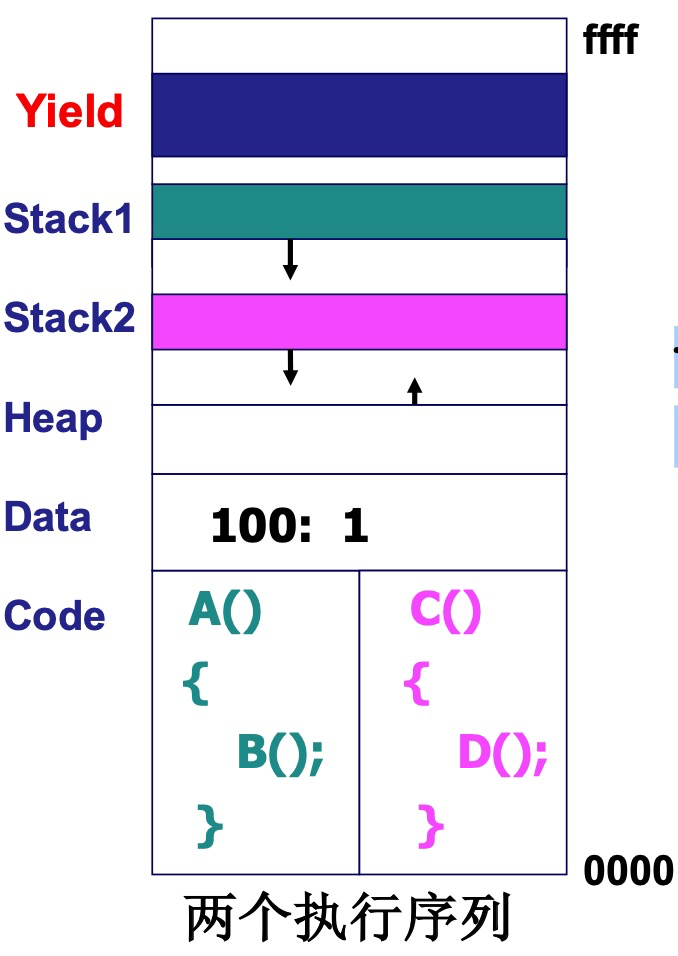
通过Yield和ThreadCreate两个用户级函数,不借助操作系统的内核实现,也可以在用户态实现用户级线程。在早期Linux不支持线程的时候就是通过这种方式来实现的。
用户级线程的特点
- 用户级线程的切换完全在内核态进行,操作系统感知不到用户线程的存在
- 用户级线程的调度是由Yield函数主动发起的,而内核态线程的调度点完全是由系统决定的,也正因此,用户及线程的代价更小
- 一旦进程因为某个线程IO操作阻塞住了,cpu就schedule别的进程开始执行,该进程的所有线程就无法进行了,这也是chrome的多tab使用多进程的模型原因,防止因为某个网页卡住导致所有的页面无法访问
内核级线程
有了用户级线程,为什么要有内核级线程呢?考虑以下的多核系统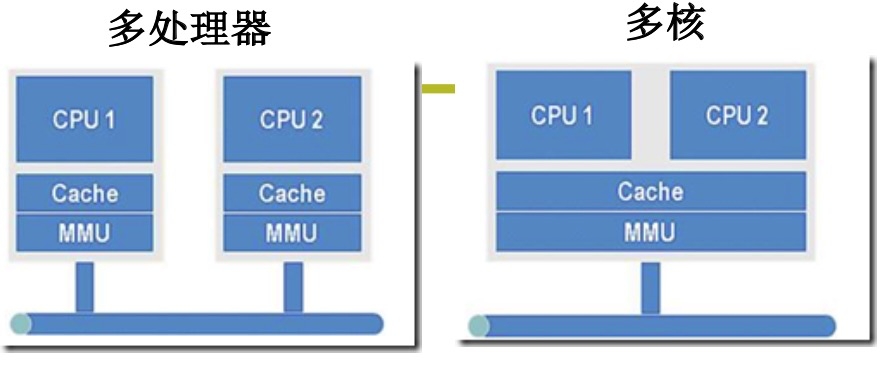
多核系统只有一个MMU(内存映射),如果只有多进程的机制,在只有一个MMU的情况下,同一个时刻只有一个进程在运行,但是如果是多个线程,同一个时刻只需要一个MMU,多个核就可以并行跑多个线程。而如果只是用户级线程,操作系统无法感知用户线程,只会分配到一个cpu执行,就无法利用上多核的能力。因此要想充分发挥多核系统的能力,必须要支持内核级线程
- 并行是同时触发同时进行,多套资源
- 并发是同时触发交替执行,一套资源
而且内核级线程相比用户级线程,tcb等数据是维护在内核中,内核中的调度单位就是线程,所以当某个线程因为io阻塞,可以调度到别的线程继续执行。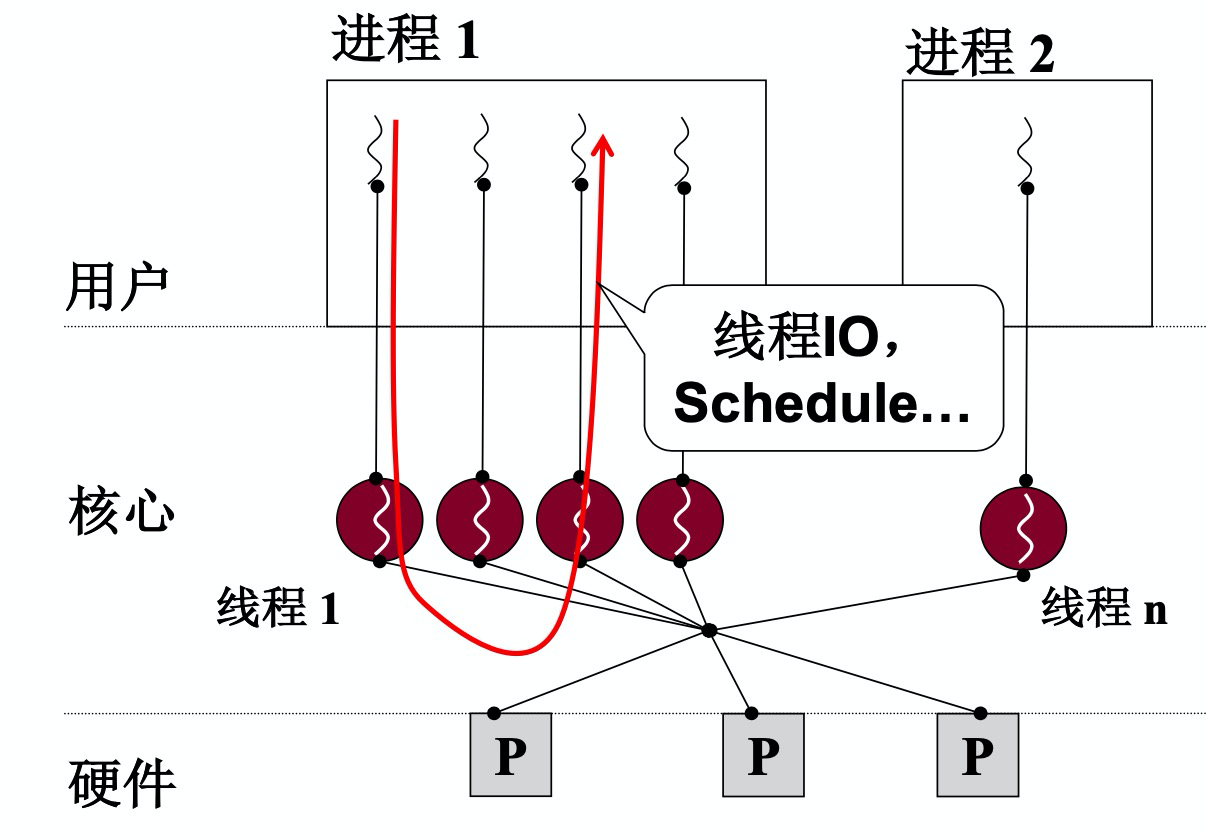
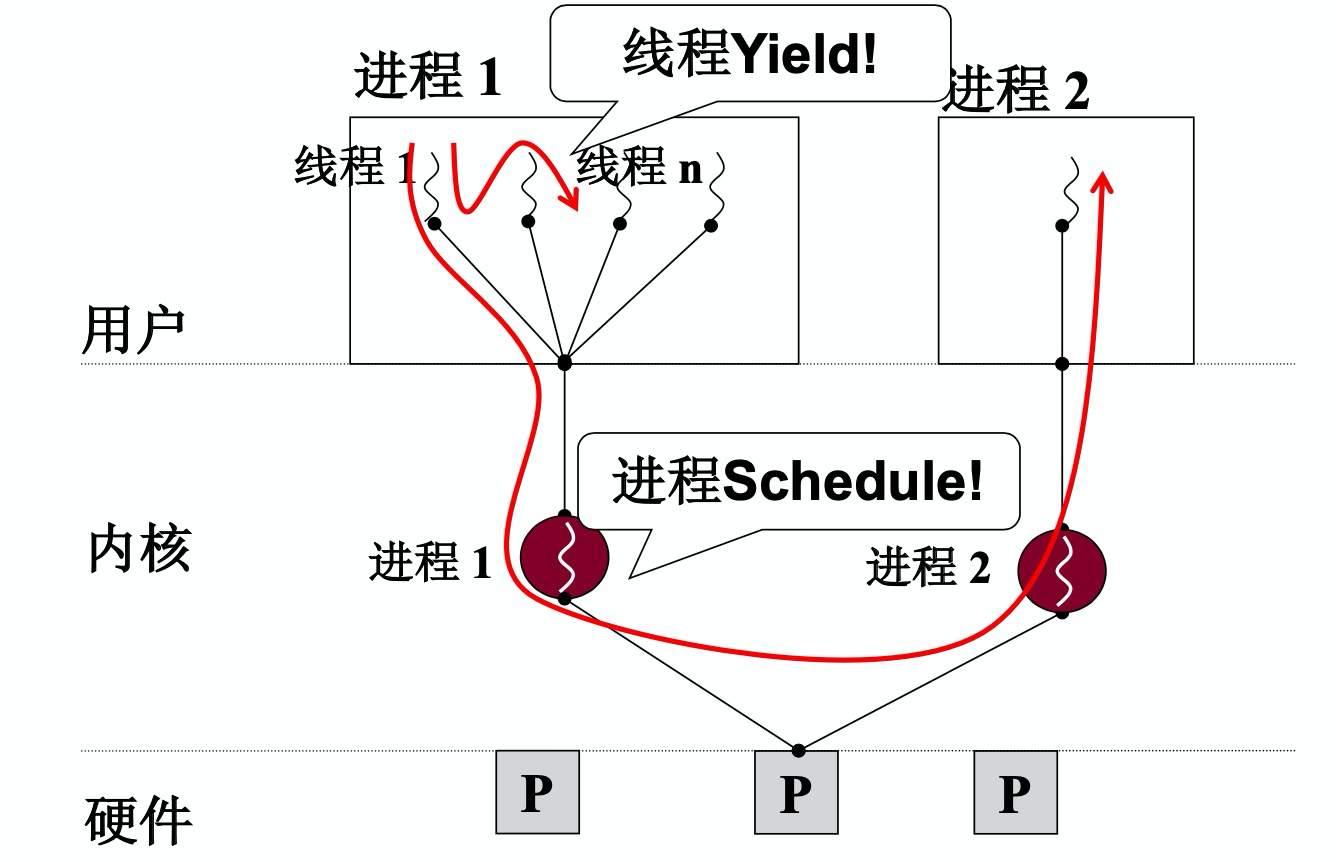
内核级线程的实现
用户级线程下的切换是两个线程的栈的切换,在内核级线程中,涉及的就是用户态和内核态两套栈的切换。
在用户程序触发中断进入内核后,会将用户栈中的栈信息压入内核栈,这个是通过int指令自动完成的,返回时通过IRet指令弹栈(iret是中断返回的指令),将ss,sp,cs,ip等内容重新赋值给相应的寄存器
以下面的函数调用为例
main() {A();B();}A() {fork();}
中断入口
1)在执行到fork函数前,用户栈如下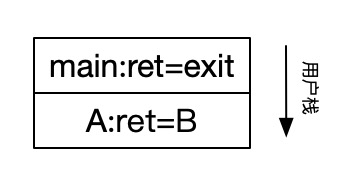
2)在A函数中执行遇到fork,fork函数是系统调用,那么会通过int 0x80触发中断进入内核态
mov %eax, __NR_forkINT 0x80mov res,%eax <= IP指针
int 0x80指令在执行时,cpu会自动将用户栈的地址压入内核栈,SS是用户栈基址,SP是用户栈偏移。以及当前的CS和IP也要压入内核栈,CS是代码段的基址,IP是指令指针偏移。也就是下图ret=CS:IP。 其中IP = mov res,%eax 的地址,因为在执行int 0x80时,IP指针下移一位,指向 mov res,%eax 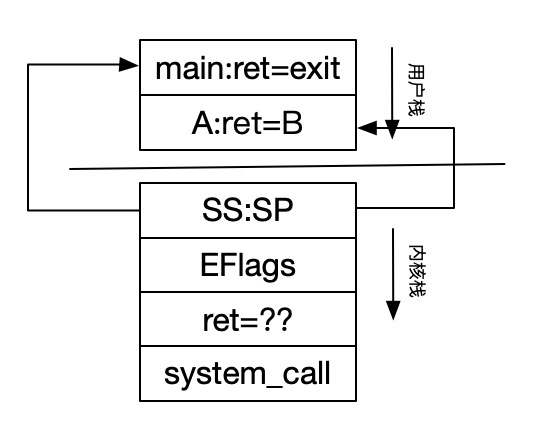
中断处理函数
3)然后在内核态就会进行中断的处理函数 system_call
_system_call:push %ds..%fspushl %edx...call sys_forkpushl %eax
4)system_call执行开始会继续压栈,压栈记录的还是用户态的寄存器的内容,然后调用sys_fork。
_sys_fork:push %gs; pushl %esi ... // 压入copy_process 函数的参数pushl %eaxcall _copy_processaddl $20,%espret
5)copy_process 的参数包含父进程运行的所有寄存器的信息,在调用前全部压入栈中,包括内核栈中的ss,sp都是作为copy_process参数传入
int copy_process(int nr,long ebp, long edi,long esi,long gs,longnone,long ebx,long ecx,long edx, longfs,long es,long ds,long eip,longcs,long eflags,long esp,long ss)
copy_process 会创建栈,这里写的是tss的现实方式(tss是Linux 0.11中内核线程切换的一个实现,通过ljmp长跳转指令实现,因为效率不高,后来被内核栈实现的内核线程切换方式所取代)
p=(struct task_struct *)get_free_page(); //申请内存空间p->tss.esp0 = PAGE_SIZE + (long) p; // 内核栈,指向栈底p->tss.ss0 = 0x10; // 内核数据段//创建内核栈p->tss.ss = ss & 0xffff;p->tss.esp = esp; // 用户栈,和父进程共用栈p->tss.eip = eip;p->tss.cs = cs & 0xffff;//将执行地址cs:eip放在tss中p->tss.eax = 0; // 子进程的返回值设置p->tss.ecx = ecx;//执行时的寄存器也放进去了// 内存相关的p->tss.ldt = _LDT(nr); set_tss_desc(gdt+(nr<<1) + FIRST_TSS_ENTRY, &(p->tss));set_ldt_desc(gdt+(nr<<1) + FIRST_LDT_ENTRY, &(p->ldt));//内存跟着切换p->state = TASK_RUNNING; // 置成running状态,等待调度
在子进程获得运行机会后,就会继续执行cs:ip处的内容,此时子进程和父进程的IP指针是一样的,都指向了 mov res,%eax 的代码,而创建子进程的时候eax赋值成了0,所以就可以通过fork返回值来判断是不是子进程
if (!fork()) {... // 子进程代码}
6)在子进程获得运行时间片,并且通过fork返回值和父进程区分开之后,开始执行自己的逻辑, 例如以下代码
if (!fork()) {exec(cmd)}
exec也是系统调用,就会执行
_system_call:push %ds .. %fspushl %edx..call sys_execve
在进入内核栈时,子进程和父进程执行的是相同的代码(内核栈的内容还是一致的),要让子进程执行自己的逻辑,需要在内核栈中替换子进程的ret中的ip地址,使其指向子进程所要执行程序的地址,这样从内核栈退出返回用户栈时,就会执行的是子进程的代码
_sys_execve:lea EIP(%esp), %eax // 将 EIP + 当前栈顶地址赋值给eax。EIP = 0x1C, 这个获取的是ret的返回地址pushl %eax // 压入 _do_execve 函数的参数call _do_execve
int do_execve( * eip,...) {p += change_ldt(...);eip[0] = ex.a_entry; // 将要执行的cmd的可执行文件的entry地址放在ret处eip[3] = p; ...}
执行时内核栈的信息
将cmd的入口地址,放在ret处,这样在从内核栈返回用户栈后,就开始执行新的用户代码了
eip[0] = esp + 0x1Ceip[3] = esp + 0x1C + 0x0C = esp + 0x28
引发切换
7)在执行完sys_fork后会判断当前是否需要调度
movl _current,%eax // current 是pcbcmpl $0,state(%eax) // 判断pcb中的state是否 == 0jne reschedule // 如果不是0,则触发调度cmpl $0,counter(%eax) // 判断pcb中的counter是否为0je reschedule // 为0则触发调度,counter表示的是线程的时间片ret_from_sys_call:
reschedule:pushl $ret_from_sys_calljmp _schedule
在调度时会通过调度算法获取到next(下一个要执行的线程),再执行switch_to进行切换
void schedule(void){next=i;switch_to(next);}
8)假设触发了调度,执行时会先压入返回的地址,在运行一段时间后,会回到这段代码继续执行 即reschedule执行完之后继续执行ret_from_sys_call 。
ret_from_sys_call:popl %eax //返回值 popl %ebx ...pop %fs ...iret
Iret弹出用户栈
9) 执行返回时首先将ds,fs等栈信息都弹出,再通过iret指令将ss:sp cs:ip弹出,设置寄存器,恢复用户态的栈状态。那么到这里就会回到最上面的IP地址处 mov res,%eax 执行,将%eax 赋值给返回结果。
小结: 内核级线程切换的五个步骤
- 中断入口
- 中断处理,如果是阻塞函数,或时钟中断,都可能引发内核级线程调度
- 调度选择下一个要执行的线程,开始进行切换
- 切换时将下一个内核级线程的tcb.esp 赋给当前的%esp寄存器
- 切换到另一个内核级线程,执行后,最后通过iret从内核栈返回用户栈
- 如果是涉及到两个进程的切换,还要有映射表的切换


若有收获,就点个赞吧
0 人点赞
