最近线上的flink集群在升级jdk版本到jdk11之后比较频繁的出现进程134码退出,同时产生了core文件,这里做一下排查记录。
现象
-rw------- 1 hadoop hadoop 8875200512 Feb 7 23:37 core.VM Thread.760.blinkhighcompute-49-033157180128.1612712134-rw------- 1 hadoop hadoop 8818241536 Feb 7 22:15 core.VM Thread.787.blinkhighcompute-49-033157180128.1612707174
在机器上生成了两个core文件,从core文件的命名上可以看到应该是执行jvm的线程的地方发生了crash,生成的core文件。一般来说jvm crash之后会生成hs_err.log的日志文件,但是现场没有看到这两个文件(存疑)
gdb分析挂掉的线程栈
gdb /opt/taobao/java/bin/java core.VM\ Thread.787.blinkhighcompute-49-033157180128.1612707174
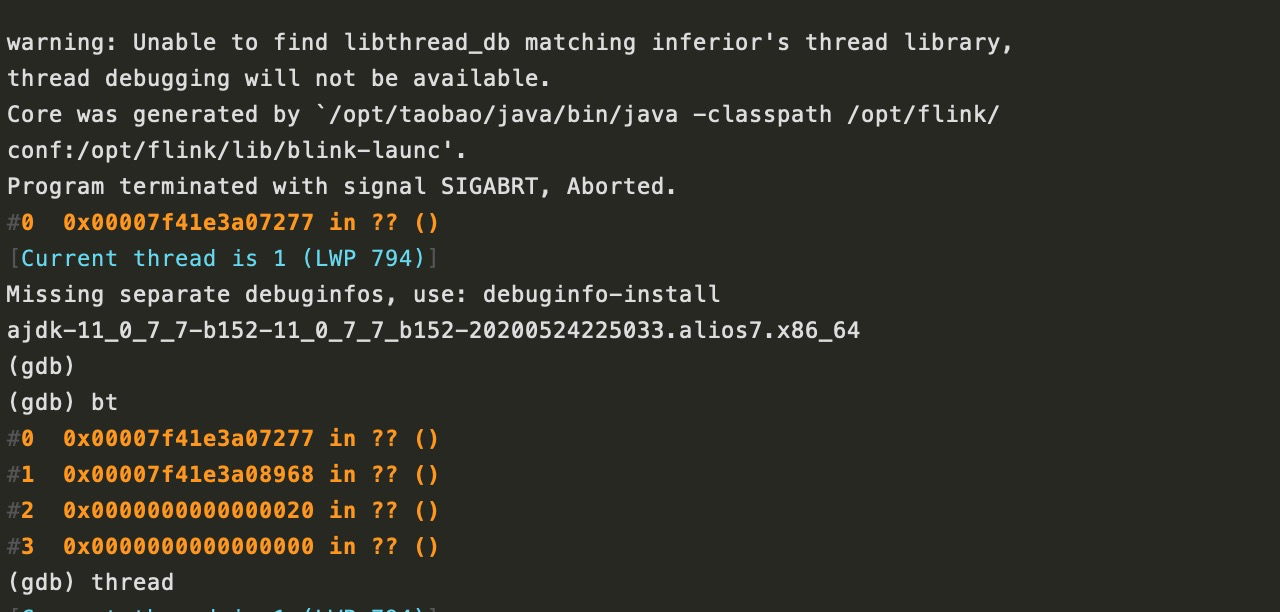
可以看到进程当时crash的时候正在执行的1号线程是0x00007f41e3a07277
jhsdb获取当时的线程栈
jhsdb jstack --exe /opt/taobao/java/bin/java --core Thread.787.blinkhighcompute-49-033157180128.1612707174 --mixed

可以看到core的时候这个线程正在执行的是G1 gc的线程,后来和JVM同学确认是这块代码有问题,导致assert fail后134码退出
Exit code 134 means your program was aborted (received SIGABRT), perhaps as a result of a failed assertion
taskmanager.out
经JVM同学提醒,查看进程的控制台输出的日志,flink的控制台输出日志在taskmanager.out日志中, 可以比较清晰的看到这个问题。
## A fatal error has been detected by the Java Runtime Environment:## Internal Error (g1HeapSizingPolicy.cpp:194), pid=787, tid=794# guarantee(maximum_desired_capacity > used_after_gc) failed: sanity## JRE version: OpenJDK Runtime Environment (11.0.7.7+152) (build 11.0.7.7-AJDK+152-Alibaba)# Java VM: OpenJDK 64-Bit Server VM (11.0.7.7-AJDK+152-Alibaba, mixed mode, tiered, compressed oops, g1 gc, linux-amd64)# Core dump will be written. Default location: /home/admin/logs/core.%e.787.%h.%t#
但是这个问题引出了另一个问题,为什么开始我们没有看到jvm crash时候输出的hs_err日志呢?
后来发现,其实是因为我们现在的运行模式在docker中,在进程退出后会引起container重启,container重启会导致pod内部的文件都被恢复到镜像中的初始状态,因为pod中的数据本身就不是持久化的,导致排查问题的时候少了必要的信息。

若有收获,就点个赞吧
0 人点赞
