分类: flink
tag: 源码分析
背景
今天我们来聊一聊flink中状态rescale的性能优化。我们知道flink是一个支持带状态计算的引擎,其中的状态分为了operator state和 keyed state两类。简而言之operator state是和key无关只是到operator粒度的一些状态,而keyed state是和key绑定的状态。而Rescale,意味着某个状态节点发生了并发的缩扩。在任务不修改并发重启的情况下,我们只需要按照task,将先前job的各个并发的state handle重新分发处理下载远程的持久化的state文件即可恢复。而发生rescale时,状态的数据分布将发生变化,因此存在一个reshuffle的过程,那么我们就来看看这个rescale的实现是怎么做的,以及其问题和优化手段。
Rescale的实现
2017年社区有一篇博客就比较深入的介绍了Operator 和 keyed state的rescale的实现,感兴趣的话可以去了解下。

这两张图对比了是否基于keyGroup来划区的一个差别,社区中的版本使用的是基于keygroup的版本实现的,可以看到可以减少对于数据的random的访问。但是从B中我们看到,以rescale后的subtask为例:
- subtask-0: 需要将原先subtask-0的dfs文件下载后将KG-3的数据剔除掉。这里需要剔除的原因是: 虽然我们任务启动后由于keyshuffle的原因,subtask-0不会再接收到KG-3的数据,但是后续如果继续做checkpoint,会导致这部分数据重新被上传到DFS文件中,而如果继续发生rescale,就可能导致和其他subtask-1上的KG-3的数据发生冲突导致数据问题
- subtask-1: 需要download原先subtask-0和subtask-1的数据dfs文件,并将subtask-0中的KG-1和KG-2的数据删除,以及原先subtask-1中的 KG-5 和 KG-6删除,并将其导入到新的RocksDB实例中。
因此我们可以总结出rescale的大致流程中,首先会将当前task所涉及的db文件恢复到本地,并从中挑选出属于当前keygroup的数据重新构建出新的db。
从理论上分析,在不同的并发调整场景下,其rescale的代价也不尽相同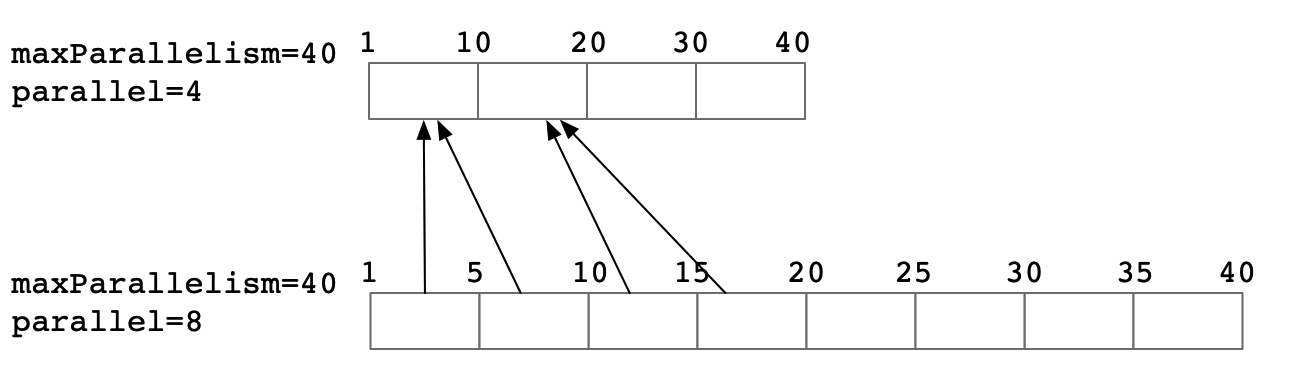
并发翻倍
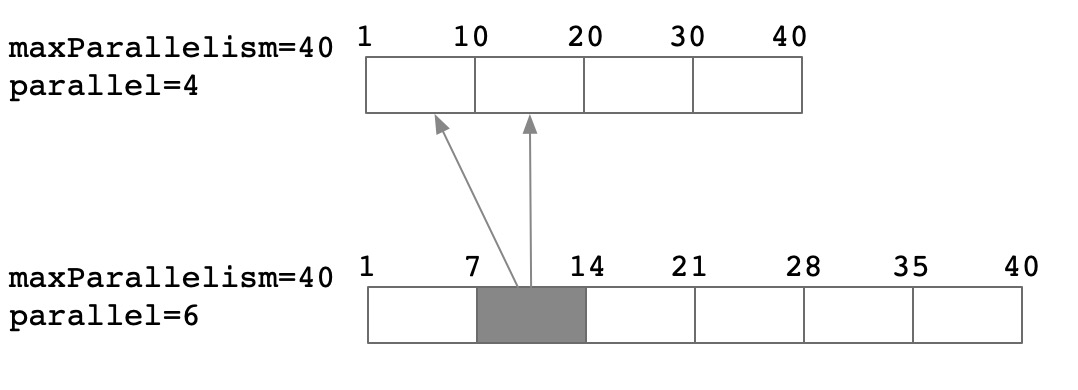
1.5倍扩并发
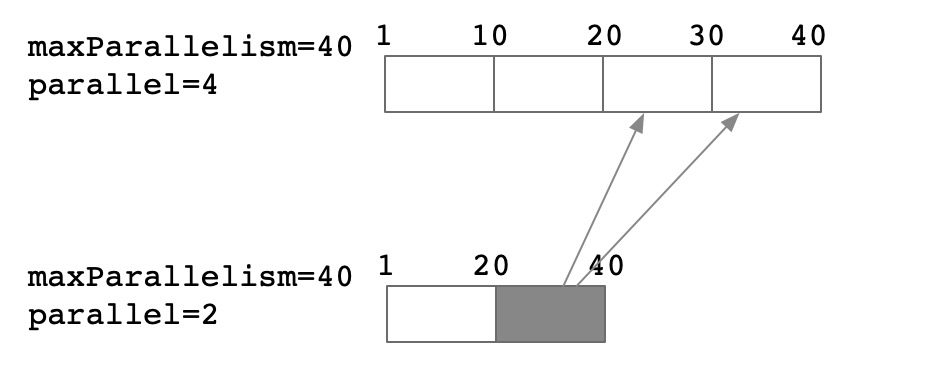
并发减半
接下来,我们在代码中确认相关的逻辑(代码基于Flink1.15版本)。
根据stateHandle元信息判断是否是rescale
我们可以看到当restoreStateHandles的数量大于1,或者stateHandle的keyGroupRange和当前task的range不一致时就是rescale的过程
在不是rescale的场景下,恢复的流程只需要将相应IncrementalRemoteKeyedStateHandle对应的文件下载到本地或者是直接使用local recovery中的 IncrementalLocalKeyedStateHandle所对应的本地文件的目录,直接执行 RocksDB.open()就可以将db数据恢复。
initialDB
首先根据keygroup的重叠比较,挑选出和当前keygroup有最大重叠范围的stateHandle作为initial state handle。这样的好处是可以尽可能利用最大重叠部分的数据,减少后续数据遍历的过程。在挑选出initial state handle 创建db之后,首先需要将db中不属于当前的task的keygroup的数据进行遍历删除。
因为flink中存储的keyed state的数据已经按照keygroup作为前缀作为排序,所以只需要删除头部和尾部的数据即可,这样就不用遍历全量的数据。
在当前的deleteRange的实现中是依赖遍历db,通过writeBatch的方式进行批量执行删除,这种方式当需要删除的key的基数较大时会比较耗时,并且都会触发io和compaction的开销,而rocksdb提供了deleteRange的接口,可以通过指定start和end key来进行快速的删除,经过测试下来基本只要ms级别就可以完成。参考 FLINK-21321
Bulk load
在完成base db裁剪之后,就需要将其他db的数据导入到base db中,目前的实现还是通过writeBatch来加速写入
在 FLINK-17971 中作者提供了sst ingest 写入的实现,本质上是利用rocksdb 的sst writer的工具,通过sst writer能直接构建出sst 文件,避免了直接写的过程中的compaction的问题,然后通过 db.ingestExternalFile直接将其导入db中。实际测试的过程中这样的写入性能有2-3倍的提升。
Rescale的优化应该迭代优化了很多次,最开始的实现应该是将所有的statehandle的数据download下来,将其遍历写入新的db,在 FLINK-8790 中首先将其优化成 base db + delete Range + bulk load的方式,后续的两个pr又通过Rocksdb提供的deleteRange + SSTIngest 特性加速。虽然这些优化应用上只有rescale的提速很明显,但是当我们遇到key的基数非常大时,就会出现我们遍历原先的db next调用和 写入的耗时也非常的大,因此rescale的场景可能还需要继续优化。
关于RocksDB中deleteRange和SST Ingest功能笔者也做了一些研究,在后续的文章中会陆续更新出来,敬请期待
参考
https://blog.csdn.net/Z_Stand/article/details/115799605 sst ingest 原理
http://rocksdb.org/blog/2017/02/17/bulkoad-ingest-sst-file.html
https://rocksdb.org/blog/2018/11/21/delete-range.html delete range原理

若有收获,就点个赞吧
0 人点赞
